- The paper demonstrates that integrating large multi-modal encoders such as CLIP and VLMo with recommender systems significantly enhances item representations by aligning visual and textual modalities.
- It employs various training paradigms—including pre-training, fine-tuning, and end-to-end training—to evaluate performance improvements on Amazon datasets using metrics like Recall@K and NDCG@K.
- The results indicate that dual-stream architectures, particularly through end-to-end training, outperform traditional modality-specific methods by reducing conflicts in feature extraction and alignment.
Large Multi-modal Encoders for Recommendation
Introduction
The paper "Large Multi-modal Encoders for Recommendation" (2310.20343) explores the integration of large multi-modal (LMM) encoders, specifically CLIP and VLMo, into recommender systems to enhance the representation of items through a deeper alignment of multiple modalities. Traditional recommendation systems rely primarily on user-item interactions, failing to exploit the complex interdependencies among visual and textual data. The paper proposes employing LMM encoders to better align and integrate these diverse data sources.
Architecture and Methodology
The study investigates two state-of-the-art encoders: CLIP, a dual-stream architecture designed for image-text retrieval tasks, and VLMo, a unified encoder handling multi-modal data with a mixture-of-modality-experts (MoME) transformer. CLIP independently processes images and text using Vision Transformers (ViT) and LLMs like GPT-2, aligning them through a contrastive loss. In contrast, VLMo combines both image and text data within a joint network, coordinating using modality-specific experts in its architecture.
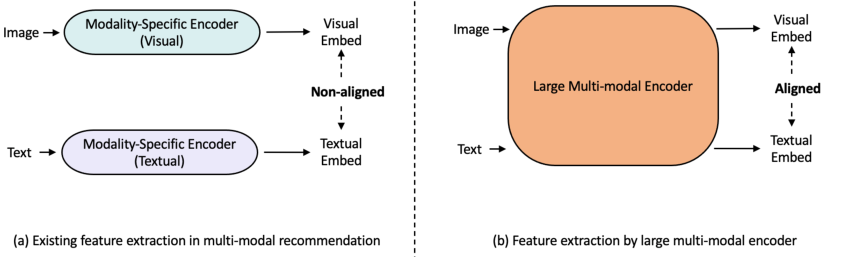
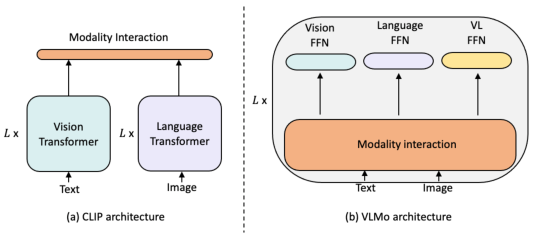
Figure 1: An illustration of different feature extraction methods.
The integration of these encoders into existing recommendation models is examined under multiple paradigms: using pre-trained encoders, fine-tuning them on specific datasets, and incorporating them in an end-to-end training framework with respective recommendation models. The implementation assesses capabilities across variably demanding computational paradigms to suit different application requirements.
Experiments and Results
Experiments are conducted on three Amazon review datasets: Sports, Clothing, and Baby categories, leveraging visual elements and textual product descriptions. The study performs a comprehensive evaluation across multiple recommendation tasks to determine efficacy improvements facilitated by LMM encoder integration. The evaluation metrics, including Recall@K and NDCG@K, indicate significant performance enhancements using LMM encoders versus traditional modality-specific encoders.
The findings reveal distinct advantages of LMM encoder strategies:
- Pre-trained and Fine-tuned Encoders: Fine-tuning LMM encoders typically yielded enhanced recommendation accuracy, though some encoder-model combinations like LATTICE experienced performance conflicts owing to overlapping feature extraction and alignment objectives.
- End-to-end Training: This paradigm generally proved superior, markedly with dual-stream LMMs (CLIP), underscoring its potential to refine existing multi-modal networks by aligning representations more robustly via recommendation losses.
Modality Contribution Analysis
The analysis of the contribution of each modality reveals that integrating both visual and textual modalities consistently performs better than utilizing individual ones. This reinforces the argument for incorporating diverse data types in recommender systems, and the alignment achieved by LMM encoders significantly surpasses traditional separate encoding methods.
Conclusions
The utilization of LMM encoders, particularly through fine-tuning and end-to-end training, demonstrates significant potential in enhancing multi-modal recommender system performance. By better aligning modalities such as text and images through advanced encoding methods like CLIP and VLMo, these systems can achieve richer, more contextually relevant user and item representations. The study's findings set a precedent for leveraging large-scale pre-trained models in recommendation tasks, suggesting directions for future research, including optimizing model architectures to eliminate conflicts in inherent learning objectives.