- The paper introduces FLTrojan, a selective weight tampering attack that exploits intermediate model snapshots to extract sensitive data.
- It presents two novel methods, SWO and WTL, which significantly boost data memorization in victim models while preserving overall model utility.
- Evaluation on multiple datasets and model types shows up to 71% data reconstruction and a 29% increase in membership inference recall, highlighting serious privacy concerns.
Privacy Leakage Attacks in Federated LLMs via Selective Weight Tampering
Introduction
This paper presents a systematic study of privacy leakage in federated learning (FL) for LLMs, focusing on the extraction of privacy-sensitive data through selective weight tampering. The authors introduce FLTrojan, a suite of attack methodologies that exploit intermediate model snapshots and manipulate specific model weights to maximize memorization of sensitive user data. The work is distinguished by its focus on targeted extraction of out-of-distribution (OOD) data (e.g., SSNs, credit card numbers, medical records) and its demonstration that intermediate FL model states are more vulnerable to privacy leakage than final models. The attacks are evaluated on both autoregressive and masked LMs (Gemma, Llama-2, GPT-2, BERT) using synthetic canaries and real-world sensitive data.
Key Observations and Hypotheses
The authors establish two critical hypotheses:
- Intermediate Model Vulnerability: Model snapshots from intermediate FL rounds exhibit higher memorization of privacy-sensitive data than the final converged model, due to the tendency of LMs to forget rare/OOD samples as training progresses.
- Selective Weight Susceptibility: Only a subset of layers—primarily model heads and adjacent transformer blocks—undergo significant weight changes when fine-tuned on OOD data, making them disproportionately responsible for memorizing sensitive information.
These hypotheses are empirically validated by analyzing the norms of weight changes across transformer layers after fine-tuning with regular versus sensitive data.
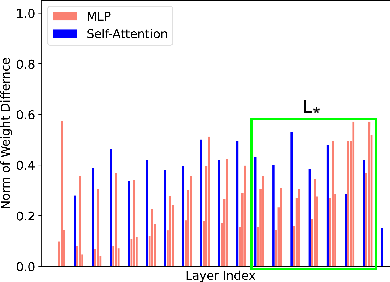
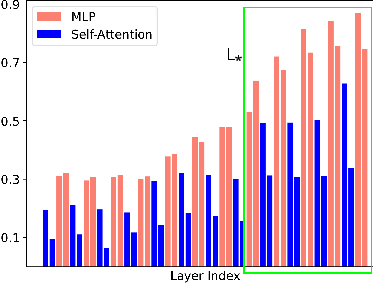
Figure 1: Overview of the attack flow, including victim round identification, maximizing data memorization, and sensitive data extraction via crafted prompts.
Attack Methodology
Threat Model
The adversary is a malicious FL client aiming to extract specific sensitive data from other clients. Two scenarios are considered: (1) without server cooperation, where the attacker only observes global model updates, and (2) with server cooperation, where the attacker can access victim local updates and ground-truth participation information.
Victim Round Identification (VRI)
The VRI algorithm identifies FL rounds in which victims with privacy-sensitive data participated. This is achieved by comparing the distribution of selective weight changes (L⋆) in global model snapshots against reference models fine-tuned with regular and sensitive data, using pairwise t-tests. High recall and precision are reported for VRI, with recall increasing as the number of victims grows.
Maximizing Data Memorization (MDM)
Two novel methods are introduced for boosting memorization in victim models:
- Selective Weights Optimization (SWO): Maximizes the norm difference between selective weights of victim and reference models, updating only the magnitude while preserving directionality to avoid arbitrary model drift.
- Weights Transformation Learning (WTL): Trains a supervised model (e.g., dense autoencoder) to learn the transformation pattern of selective weights from regular to sensitive data, enabling fine-grained weight manipulation.
Both methods are applied in static (post-training) and dynamic (during training) attack modes, with dynamic attacks further increasing leakage by aggregating and injecting victim models into the global state.
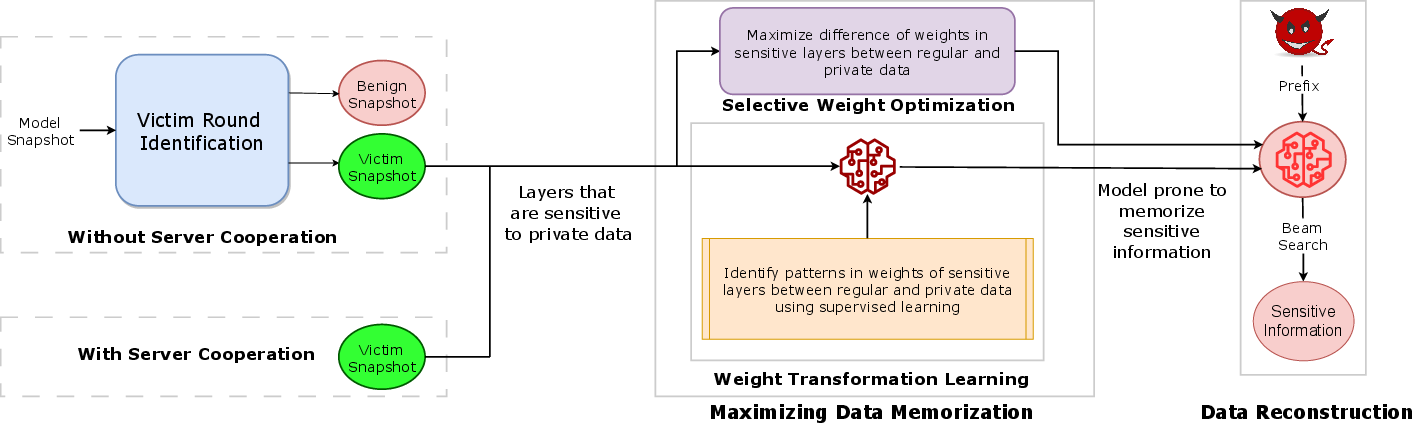
Figure 2: Attack flow diagram illustrating the sequence of victim round identification, weight tampering, and sensitive data extraction.
Evaluation and Results
Experimental Setup
Attacks are evaluated on Wikitext, PTB, and Enron datasets, with both synthetic canaries and real-world sensitive sequences. Models are fine-tuned in FL with 100 clients, 20 selected per round, and varying numbers of attackers/victims. Metrics include number of successful reconstructions (NSR), exposure (EXP), membership inference recall/precision, and perplexity (PPX).
Data Reconstruction
- Intermediate Rounds vs. Final Model: Attacks on intermediate victim rounds yield significantly higher NSR than attacks on the final model, confirming the first hypothesis.
- MDM Effectiveness: SWO and WTL substantially increase NSR over baseline attacks, with WTL outperforming SWO due to better alignment with true weight transformation patterns.
- Dynamic Attacks: Real-time interference further boosts NSR, especially with server cooperation, achieving up to 71% reconstruction of private data.
- Model and Data Factors: Larger models and repeated sensitive data increase leakage; masked LMs (BERT) are more resilient than autoregressive LMs (GPT-2, Gemma).
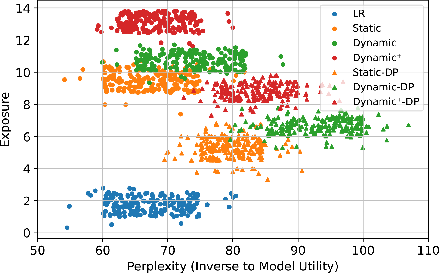
Figure 3: Tradeoff between model utility (perplexity) and private data memorization (exposure) with and without differential privacy.
Membership Inference
MDM methods increase membership inference recall by up to 29% over baselines, with only marginal changes in precision. Confusion matrices show a marked reduction in false negatives, indicating improved detection of training set membership for sensitive samples.
Ablation and Benchmarking
- Prompt Perturbation: Attacks remain effective with semantically perturbed prefixes, though NSR decreases with lower similarity.
- Sensitive Layer Selection: NSR increases with more layers in L⋆ up to a threshold, after which utility degrades.
- Victim Participation: NSR is robust to reduced victim round frequency under MDM attacks.
- Comparison to Decepticons and FILM: FLTrojan outperforms Decepticons and FILM, especially for masked LMs and without requiring active server adversaries.
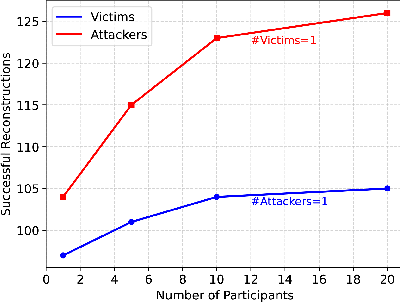
Figure 4: Number of successful reconstructions (NSR) as a function of the number of victims and attackers.
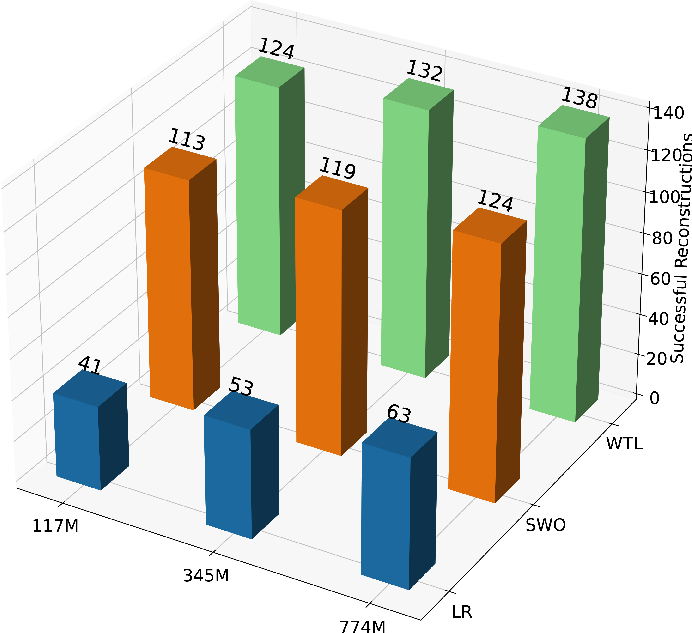
Figure 5: NSR for different model sizes, demonstrating increased leakage with larger models.
Defense Mechanisms
Differential Privacy
DP-SGD reduces exposure and NSR but at the cost of increased perplexity and degraded model utility. Even with strong privacy budgets (ϵ=0.5), leakage is not eliminated, and utility loss is substantial.
Scrubbing and Deduplication
Token scrubbing and data deduplication reduce leakage, particularly for repeated sensitive sequences, but are insufficient against targeted weight tampering attacks.
Implications and Future Directions
Practical Implications
- Federated LMs Are Vulnerable: FL does not guarantee protection against targeted privacy leakage, especially for OOD sensitive data.
- Intermediate Model Snapshots Are High-Risk: Model checkpoints during training are more susceptible to leakage than final models.
- Selective Weight Manipulation Is Potent: Attacks focusing on specific layers can dramatically increase memorization and leakage without global model drift.
Theoretical Implications
- Memorization Dynamics in FL: The findings highlight the non-uniform forgetting and memorization behavior of LMs in FL, with implications for privacy analysis and defense design.
- Layerwise Susceptibility: The identification of sensitive layers provides a new axis for both attack and defense research in neural architectures.
Future Work
- Advanced Defenses: There is a need for federated learning frameworks that can mitigate selective weight tampering, possibly via secure aggregation, robust DP, or architectural modifications.
- Generalization to Other Modalities: Extending these attacks and defenses to multimodal FL (e.g., vision, speech) is a promising direction.
- Automated Sensitive Layer Detection: Developing automated methods for identifying and protecting sensitive layers could improve privacy guarantees.
Conclusion
FLTrojan demonstrates that federated LMs are highly vulnerable to privacy leakage via targeted attacks on intermediate model states and selective weight tampering. The proposed MDM techniques (SWO, WTL) significantly outperform prior attacks, achieving up to 71% reconstruction of private data and a 29% increase in membership inference recall. Existing defenses such as DP are insufficient without severe utility loss. The work underscores the urgent need for more robust privacy-preserving mechanisms in federated language modeling and provides a foundation for future research on both attack and defense strategies.