- The paper demonstrates that prominent LLMs, such as GPT-3 and PaLM, exhibit inherent conservative moral biases using the Moral Foundations Questionnaire.
- It employs context-specific prompts and random dialogue samples to assess the consistency and adaptability of LLM moral foundations across varied scenarios.
- Prompt engineering shifts LLM behavior in downstream tasks like donation decisions, highlighting ethical implications for real-world applications.
Moral Foundations of LLMs
Abstract
The study "Moral Foundations of LLMs" (2310.15337) leverages Moral Foundations Theory (MFT) to analyze whether prominent LLMs reflect particular moral biases acquired from their training data. By employing the Moral Foundations Questionnaire (MFQ), the paper examines the predispositions of various LLMs towards specific moral dimensions and investigates their consistency across different contexts, exploring the impact of moral conditioning on downstream tasks, such as donation behavior.
Introduction
The introduction of the paper highlights the rapid integration of LLMs, such as GPT-3 and PaLM, into diverse applications, driven by their capability to generate contextually rich text based on extensive internet-derived datasets. While these models exhibit advanced linguistic competencies, concerns arise regarding the implicit biases embedded within their training data—particularly cultural and political biases—that could potentially influence their performance and ethical stance in various applications.
Moral Foundations Theory (MFT), which differentiates human moral reasoning into five primary factors—care/harm, fairness/cheating, loyalty/betrayal, authority/subversion, and sanctity/degradation—is utilized to assess these biases. Historically, MFT has elucidated the moral variances across political ideologies, portraying liberals and conservatives as emphasizing different sets of foundations. This paper extends MFT to evaluate if LLMs encapsulate biases congruent with specific human moral foundations.
Methodology
The research is centered on two primary objectives: assessing the inherent moral biases in LLMs and evaluating the consistency of these biases across varied contexts. To achieve this, the authors apply the MFQ to several models, including GPT-3's DaVinci2 and Google's PaLM, to compare their moral scores with data from psychological studies involving human subjects across different demographics (2310.15337).
Application of MFQ to LLMs
For each model, the MFQ is administered by prompting the LLM with its questions, modified with context instructions aimed at maintaining the relevancy of each query. Random sampling from the BookCorpus dataset further augments the evaluation by providing non-moral random dialogues, thereby examining the consistency of moral scores under different conversational prompts.
Prompt Engineering
The study also uses prompt engineering to deliberately condition LLMs to favor particular moral foundations. Prompts emphasizing specific moral dimensions are crafted, aiming to observe substantial shifts in moral foundation scores and their consequent influence on downstream applications, notably in donation tasks.
Results
Human and LLM Moral Foundations Comparison
The analysis reveals that models like GPT-3 DaVinci2, and to some extent PaLM, exhibit moral foundation scores closely resembling conservative human profiles, especially when unprompted (Figure 1). This observation implies an inherent bias towards conservatism in the default behavior of these models. However, deliberate political prompting allows models to adaptively simulate the moral foundations of liberal or moderate human ideologies—a promising avenue for bias mitigation.


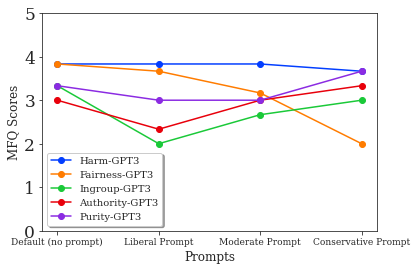
Figure 1: We apply t-SNE to reduce moral foundations scores to two dimensions and plot the location of different human populations alongside the LLM models.
Consistency Across Contexts
The experiments show that models manifest varied degrees of moral foundation consistency. GPT-3, particularly, demonstrates a persistent bias towards some dimensions, such as fairness, across different contexts, which may imply that it could propagate these biases into applications irrespective of the immediate linguistic context.

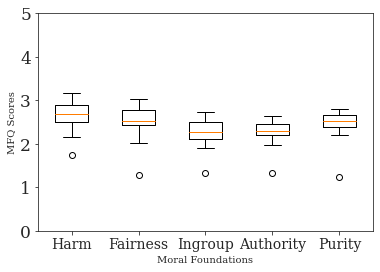
Figure 2: We assess consistency in moral foundations by randomly prompting the LLM with 50 random book dialogues from the BookCorpus dataset.
Inducing Moral Shifts
By utilizing prompts crafted to highlight specific moral dimensions, the DaVinci2 model exhibits a capacity to adjust its moral foundation scores predictably (Figure 3). This capability is crucial as it allows the alteration of model responses—applying corrections or intentional biases that could be employed strategically in applications.
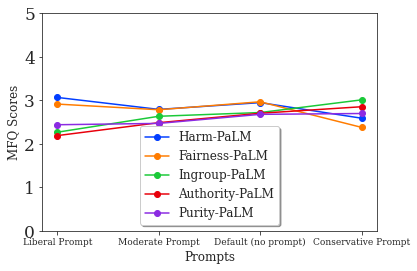
Figure 3: PaLM moral foundation scores.
Impact on Downstream Tasks
The donation experiments determine that shifts in moral foundations induced through targeted prompts significantly alter the LLM's behavior on tasks, such as charity donation scenarios (Table 1). Notably, the models conditioned to value loyalty and purity tend towards higher donation outputs compared to their default or politically conservative conditioning.
Implications and Future Work
The findings underscore potential ethical and societal ramifications of deploying LLMs without accounting for their inherent biases. If left unchecked, biases might inadvertently shape decision-making across applications. However, the ability to deliberately condition LLMs offers a mechanism for mitigating these biases, enhancing neutrality, and achieving alignment with intended ethical standards.
Future research should explore multi-dimensional prompt strategies across various tasks to comprehensively understand bias dynamics in LLM performance, particularly in real-world applications. Furthermore, expanding investigations to include more robust cross-cultural comparisons could deepen insights into LLM biases and their strategic rectification.
Conclusion
This study explores the moral architectures of LLMs, revealing persistent biases aligned with conservative moral foundations and emphasizing the significant effects of prompts in reshaping these biases. While posing ethical considerations, the results also offer pathways for refining LLM applications towards more ethically congruent outcomes. Understanding and managing the moral predispositions within LLMs remain essential for their responsible deployment.

