- The paper demonstrates that MechanisticProbe successfully extracts embedded reasoning trees from language models, with higher probing scores correlating with improved task performance.
- It applies the method on GPT-2 and LLaMA, showing that lower layers capture essential input details while higher layers synthesize these into cohesive reasoning processes.
- Attention simplification strategies, such as pooling across heads, enable tractable analysis and provide practical insights for enhancing model transparency in critical domains.
Towards a Mechanistic Interpretation of Multi-Step Reasoning Capabilities of LLMs
Introduction
The paper "Towards a Mechanistic Interpretation of Multi-Step Reasoning Capabilities of LLMs" (2310.14491) addresses a critical question about how LMs perform multi-step reasoning tasks. The authors aim to determine whether LMs engage in genuine procedural reasoning או\ר if they simply recall memorized answers from their training data. They propose a hypothesis that LLMs inherently embed a reasoning tree within their architecture, which mirrors the logical steps required to solve reasoning tasks.
MechanisticProbe and Reasoning Tree Hypothesis
The authors introduce "MechanisticProbe", a novel probing approach designed to extract the reasoning tree from a LLM's attention patterns. This framework is applied to study two models: GPT-2 on a synthetic task and LLaMA on language-based reasoning tasks such as ProofWriter and AI2 Reasoning Challenge (ARC). MechanisticProbe is structured to convert the task of reasoning tree discovery into two subproblems: identifying essential nodes and inferring the height of each node within the attention mapping.

Figure 1: Illustration of our MechanisticProbe with one example from each of the three reasoning tasks considered in this work.
Experimental Analysis
Experimentation with GPT-2 and LLaMA: The research investigates whether MechanisticProbe can determine the reasoning tree from the attention patterns of GPT-2 and LLaMA. Results indicate that for well-trained models, MechanisticProbe successfully extracts a reasoning tree that matches the actual reasoning process. For instance, with GPT-2 finetuned on a task to identify the k-th smallest number, MechanisticProbe exhibits strong performance by detecting the reasoning paths accurately.
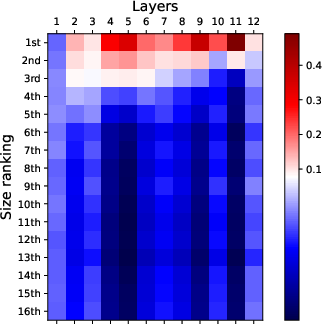
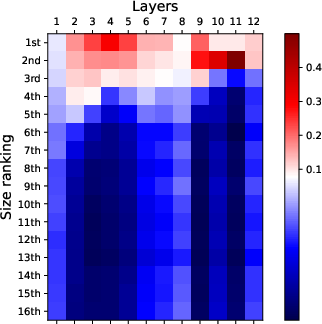
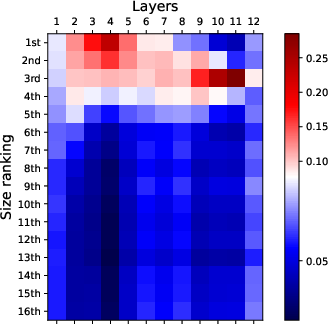
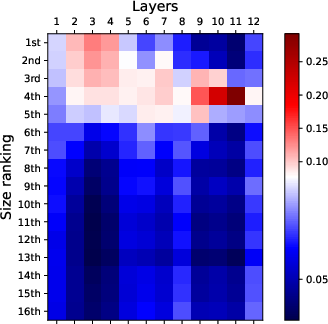
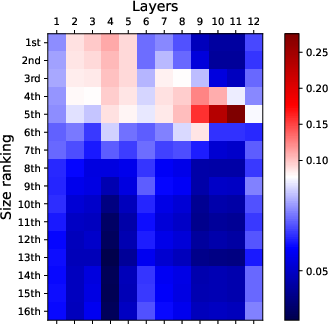
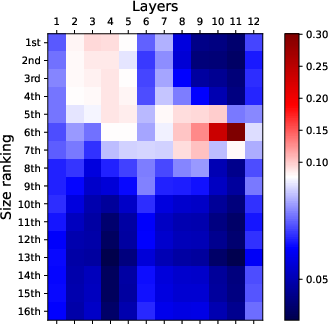
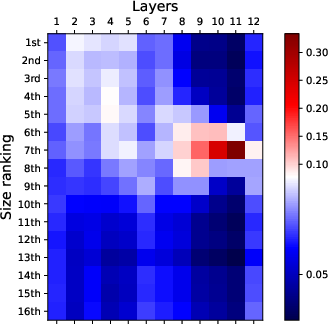
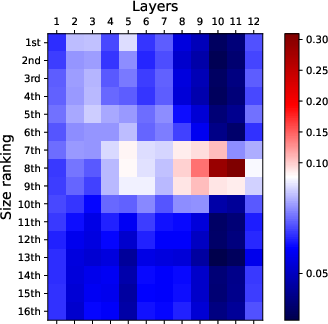
Figure 2: Visualization of attention patterns when identifying the k-th smallest number. Bottom layers focus on top-k numbers, while top layers focus on finding the k-th smallest number.
Attention Simplification Strategies: To address the vast number of attention weights involved, the paper suggests several reduction strategies, including focusing on the last token's attention and pooling across attention heads. These techniques simplify the matrix of considered attention weights, allowing for more tractable analysis and visualization.
Results and Interpretation
The findings affirm that LLMs tend to solve reasoning tasks procedurally, their attention patterns suggesting a structured reasoning trace akin to human logical processes.
- Probing Scores and Task Performance: The paper demonstrates that higher probing scores correlate with improved accuracy in reasoning tasks and increased robustness against data perturbations. This underscores that the attention patterns in LMs not only reflect but are also crucial for reasoning efficacy.
- Layer-wise Analysis: By examining attention patterns across layers, the study finds a layered reasoning process, where lower layers identify useful statements and higher layers engage in synthesizing these statements into a cohesive answer.
(Figure 3)
Figure 3: Layer-wise probing results on ARC illustrate that while lower layers identify useful input statements, higher layers focus on synthesizing the final reasoning steps.
Practical and Theoretical Implications
The implications of this study are twofold. Practically, it suggests that attention patterns could be harnessed to enhance reasoning transparency and predictability in LLMs, boosting their applicability in critical domains requiring interpretability. Theoretically, it advances the understanding of how procedural knowledge is embedded within neural architectures, an insight critical for developing next-generation LMs that can reason with greater accuracy and fairness.
Conclusion
The paper makes a significant stride in explicating the internal mechanisms of LMs concerning multi-step reasoning. By leveraging attention-based probes, it illustrates that LMs likely encode and operate on reasoning structures mechanistically. Future research could extend these insights to more complex tasks and models, refining and broadening the scope of mechanistic interpretability. While the current study focuses on relatively simple reasoning tasks, the methodologies and conclusions laid out offer a foundation for further exploration into more intricate reasoning scenarios within LMs.