Understanding Addition in Transformers
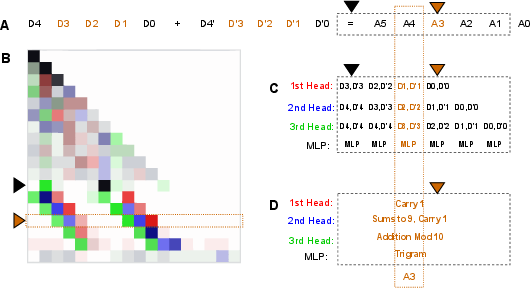
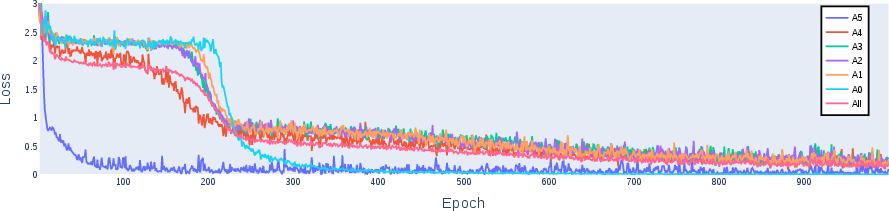
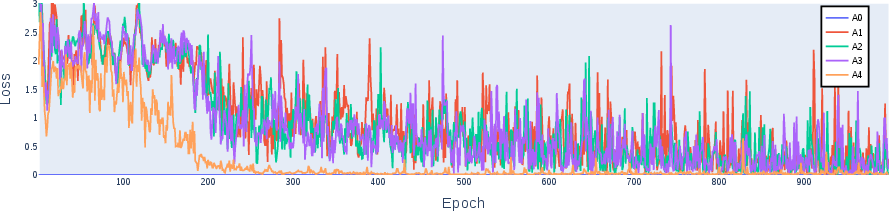
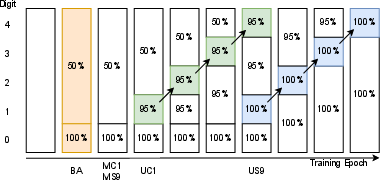
Abstract: Understanding the inner workings of machine learning models like Transformers is vital for their safe and ethical use. This paper provides a comprehensive analysis of a one-layer Transformer model trained to perform n-digit integer addition. Our findings suggest that the model dissects the task into parallel streams dedicated to individual digits, employing varied algorithms tailored to different positions within the digits. Furthermore, we identify a rare scenario characterized by high loss, which we explain. By thoroughly elucidating the model's algorithm, we provide new insights into its functioning. These findings are validated through rigorous testing and mathematical modeling, thereby contributing to the broader fields of model understanding and interpretability. Our approach opens the door for analyzing more complex tasks and multi-layer Transformer models.
- System iii: Learning with domain knowledge for safety constraints, 2023.
- Network dissection: Quantifying interpretability of deep visual representations. Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3319–3327, 2017.
- Measuring disentanglement: A review of metrics, 2022.
- Towards automated circuit discovery for mechanistic interpretability, 04 2023a.
- Towards automated circuit discovery for mechanistic interpretability, 2023b.
- A mathematical framework for transformer circuits. https://transformer-circuits.pub/2021/framework/index.html, 2021.
- Toy models of superposition, 2022.
- Neuron to graph: Interpreting language model neurons at scale, 2023.
- Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, Online and Punta Cana, Dominican Republic, Nov. 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.446. URL https://aclanthology.org/2021.emnlp-main.446.
- How does information bottleneck help deep learning?, 2023.
- Locating and editing factual associations in gpt. https://proceedings.neurips.cc/paper_files/paper/2022/file/6f1d43d5a82a37e89b0665b33bf3a182-Paper-Conference.pdf, 2022.
- R. Miikkulainen. Creative ai through evolutionary computation: Principles and examples. https://doi.org/10.1007/s42979-021-00540-9, 2021.
- N. Nanda and T. Lieberum. Mechanistic interpretability analysis of grokking. https://www.alignmentforum.org/posts/N6WM6hs7RQMKDhYjB, 2022.
- Progress measures for grokking via mechanistic interpretability, 2023.
- Zoom in: An introduction to circuits. https://distill.pub/2020/circuits/zoom-in/, 2020a.
- Zoom in: An introduction to circuits. Distill, 5(3):e00024.001, 2020b.
- Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients. Advances in Neural Information Processing Systems, 34, 2021.
- Toward transparent ai: A survey on interpreting the inner structures of deep neural networks. arXiv preprint arXiv:2207.13243, 2022.
- A. K. Seth. Causal connectivity of evolved neural networks during behavior. Network: Computation in Neural Systems, 16(1):35–54, 2005. doi: 10.1080/09548980500238756. URL https://doi.org/10.1080/09548980500238756.
- J. Vig. A multiscale visualization of attention in the transformer model. arXiv preprint arXiv:1906.05714, 2019.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.