- The paper demonstrates that integrating IR systems with LLMs via enriched prompts significantly improves legal judgment prediction.
- The methodology leverages in-context learning with label candidates and retrieved similar cases to mimic human legal reasoning.
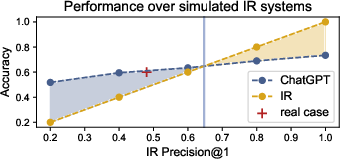
- Results reveal that models like GPT-4 excel in prediction accuracy, though standalone IR systems can sometimes outperform combined setups.
Evaluation of LLMs on Legal Judgment Prediction
The paper "A Comprehensive Evaluation of LLMs on Legal Judgment Prediction" (2310.11761) presents a detailed analysis of the capability of LLMs in handling tasks in the legal domain, specifically focusing on Legal Judgment Prediction (LJP). It explores the interaction of LLMs with Information Retrieval (IR) systems and evaluates models across zero-shot and few-shot learning scenarios.
Baseline Methods for Legal Judgment Prediction
The study introduces practical baseline solutions that leverage both LLMs and IR systems. LLMs are used to predict legal charges by employing in-context learning, where they generate outputs based on prompts that incorporate specific instructions, label candidates, and task demonstrations. The IR system enriches these prompts by retrieving similar cases, which aids in strengthening the reasoning capabilities of LLMs.
LLM Prompting
Prompts are crafted by combining task instructions with possible label candidates and case demonstrations. This approach aims to activate the LLM's pre-existing domain knowledge and facilitate a prediction process that aligns more closely with human legal reasoning.
Interaction with IR Systems
The IR system plays a crucial role in acquiring similar cases from a legal corpus, which are then used to construct informative demonstrations for the LLMs. This setup enables the transformation of complex open questions into more manageable multiple-choice questions by providing possible label candidates derived from these similar cases.
Results and Observations
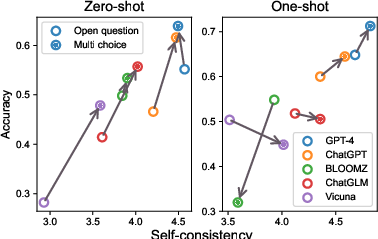
The evaluation includes prominent LLMs such as GPT-4 and its counterparts like ChatGPT, Vicuna, ChatGLM, and BLOOMZ. The experiment is structured under four distinct settings: zero-shot open questions, few-shot open questions, zero-shot multi-choice questions, and few-shot multi-choice questions.
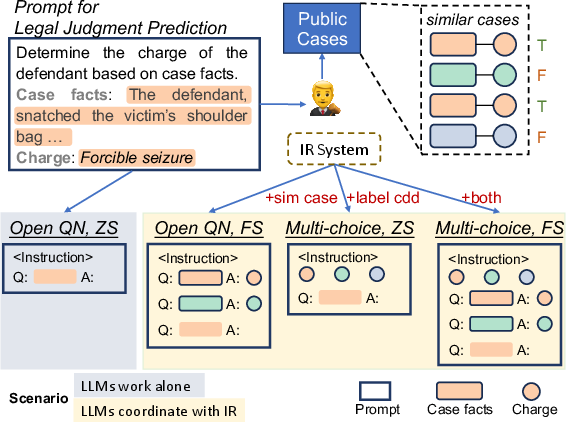
Figure 1: The task of Legal Judgment Prediction and the evaluation settings. Different colors refer to different charges.
- Significance of Prompt Enrichment: The inclusion of label candidates and demonstrations significantly enhances the predictive performance of LLMs, showcasing the benefit of integrating IR systems to support LLMs in legal domains.
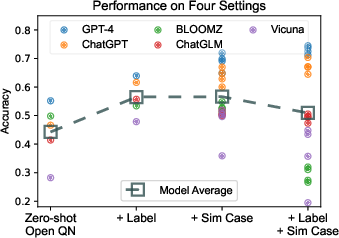
Figure 2: The macro comparison between the four settings, highlighting improvements with enriched prompts.
- Model Comparisons: Among the evaluated models, GPT-4 demonstrates the highest proficiency in leveraging domain knowledge, both through label candidates and similar case retrieval, surpassing its smaller counterparts (Figure 3).
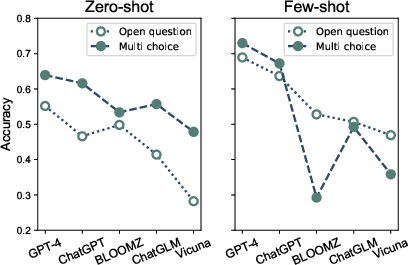
Figure 3: Compare the models under each setting. Few-shot performances are averaged among 1-shot to 4-shot.
The paper identifies multiple factors influencing the performance of LLMs:
Ablation Studies
The paper further explores the effects of increasing the number of demonstrations and the impact of noise from irrelevant cases. It concludes that while powerful models benefit from more demonstrations, adding noise from irrelevant cases can degrade performance.
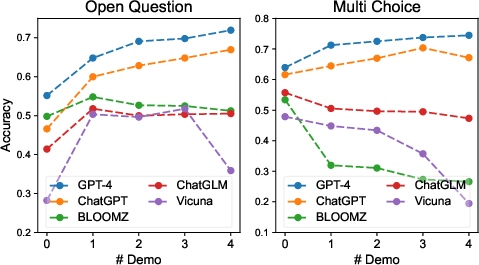
Figure 6: Performance vs. the number of similar demonstrations of the five LLMs, indicating the balance between knowledge gain and noise.
Conclusion
The research emphasizes the importance of integrating domain-specific knowledge into LLMs, particularly through structured prompts and the utilization of similar legal cases. Despite the promising capabilities of current LLMs, the study underlines the need for better synergy between LLMs and retrieval systems to fully harness the potential of AI in legal reasoning. The findings advocate for future research into tailored strategies that can accommodate the specific challenges within legal domains, paving the way for more robust and informed AI-driven legal systems.