- The paper demonstrates that LLMs, particularly GPT-4 with belief state engineering, can exhibit Theory of Mind in collaborative multi-agent tasks.
- The paper leverages a text-based search and rescue game to assess coordination, comparing LLM performance to traditional MARL and planning-based methods.
- The paper highlights that while LLMs achieve strong initial performance, challenges such as long-horizon context and systematic failures remain.
Theory of Mind for Multi-Agent Collaboration via LLMs
The paper "Theory of Mind for Multi-Agent Collaboration via LLMs" investigates the utility of LLMs in multi-agent collaborative environments. By leveraging LLM-based agents in a multi-agent cooperative text game, the paper evaluates their Theory of Mind (ToM) capabilities and compares these agents with Multi-Agent Reinforcement Learning (MARL) and planning-based baselines.
Introduction and Motivation
Recent advancements in LLMs, such as GPT-4, suggest these models exhibit proficiency not just in traditional NLP tasks, but potentially in complex reasoning tasks involving Theory of Mind (ToM). This paper addresses the gap in research concerning LLMs' performance in multi-agent collaborations, traditionally dominated by MARL approaches. It asks whether LLMs can manifest cognitive skills akin to ToM—recognizing and reasoning about others' mental states—within dynamic, interactive team settings.
Multi-Agent Collaboration Tasks
To put LLMs to the test, a multi-agent search and rescue task was devised. The environment models a connected graph where agents need to navigate and defuse bombs dispersed across rooms:
- Agents and Roles: The team consists of three agents with unique capabilities, each possessing specific bomb-defusing tools.
- Environment: Composed of nodes (rooms) connected via edges (hallways), each node can contain bombs requiring specific sequences of wire-cutter operations to be neutralized.
- Objective: Maximize team score by defusing bombs efficiently, demanding team coordination and sharing of limited information.
The agents interact via a textual interface that translates environmental observations into language descriptions. This setup inherently limits agents' observations to their current room and communicated messages, crucial for testing their ToM capabilities.
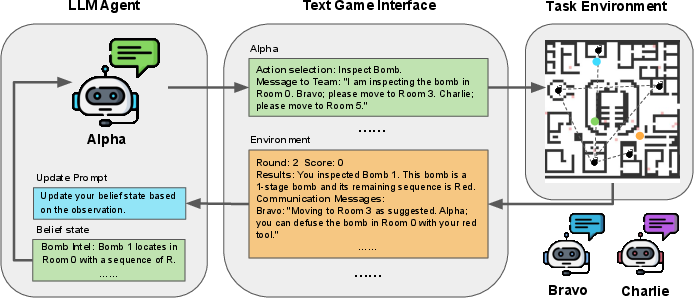
Figure 1: Our proposed framework consists of 3 LLM-based agents, a text game interface, and the task environment.
LLM-Based Embodied Agents
The paper examines OpenAI's GPT-3.5-turbo and GPT-4 models as potential embodied agents. The LLMs engage in a text-based game interface, processing large textual interaction histories limited to 4096 tokens. This interaction history facilitates agent memory and planning:
- Communication and Coordination: LLMs must send structured communication messages to coordinate actions and share critical mission updates.
- Belief State Representation: An explicit textual belief state is maintained per agent to encapsulate long-term world knowledge, aiding efficient action planning and execution.
Experiments and Results
The paper presents comparative results of LLM-based agents against traditional MARL methods and a state-of-the-art planning algorithm. These results highlight LLMs' strengths and systematic weaknesses:
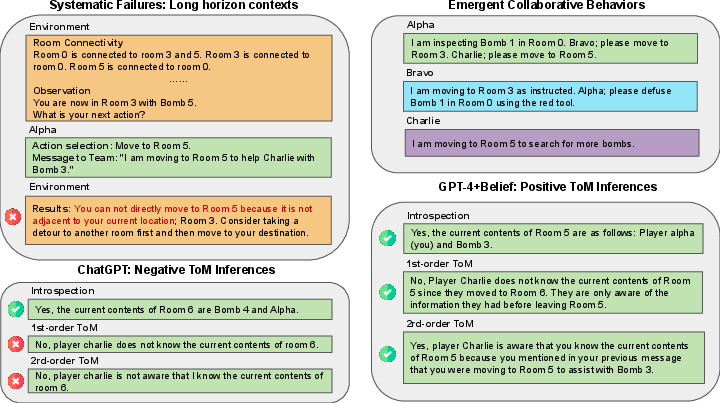
Theory of Mind Inference
The study extends into evaluating the Theory of Mind capabilities of LLMs through introspection, first-order and second-order ToM inferences:
- Higher-Order Reasoning: It was found that while LLMs show promise in ToM tasks, their reasoning abilities in dynamic agent scenarios with communication complexity are limited compared to even young children in human studies.
Conclusions
The research demonstrates that LLMs, especially GPT-4 with belief state engineering, can serve as effective zero-shot collaborators in multi-agent environments. While impressive, challenges remain in fine-tuning LLMs for optimal task-specific efficiency reaching that of specialized MARL or planned strategies.
Future Directions and Limitations
Potential future research could expand on model varieties, scalability of task environments, and heterogeneity of agent roles. Ground truth estimation for ToM could also benefit from more automated, less-human-centric frameworks to benchmark LLM reasoning on a larger scale.
Conclusively, while LLMs perform impressively in novel collaborative tasks, this study identifies areas for significant improvement, particularly in nuanced, interactive ToM capabilities critical for advanced AI-agent and human-agent team collaboration.