- The paper presents a novel backdoor attack strategy leveraging machine unlearning to selectively remove mitigation data and reveal latent vulnerabilities.
- Experiments demonstrate significantly increased attack success rates on datasets like MNIST and CIFAR10 while preserving model accuracy.
- The study explores detection methods using model uncertainty and sub-model similarity, highlighting challenges for robust AI defenses.
Exploiting Machine Unlearning for Backdoor Attacks in Deep Learning Systems
Introduction
The paper "Exploiting Machine Unlearning for Backdoor Attacks in Deep Learning System" (2310.10659) discusses a novel method for executing backdoor attacks through the process of machine unlearning. The primary focus is on utilizing unlearning requests to secretly embed backdoors into deep learning models, thereby escaping detection by existing defense mechanisms. This strategy underscores the persistent vulnerabilities in modern AI systems when manipulation of the training data is involved.
Methodology
Backdoor Attack via Machine Unlearning: The proposed method involves two phases. Initially, a seemingly benign model is trained using both regular data and poison samples with concealed mitigation data. These mitigation samples act to mask the effects of the poison samples during training. In the subsequent phase, machine unlearning requests are strategically issued to forget specific mitigation samples. This gradually reveals the latent backdoor, increasing the model's susceptibility to a backdoor attack.
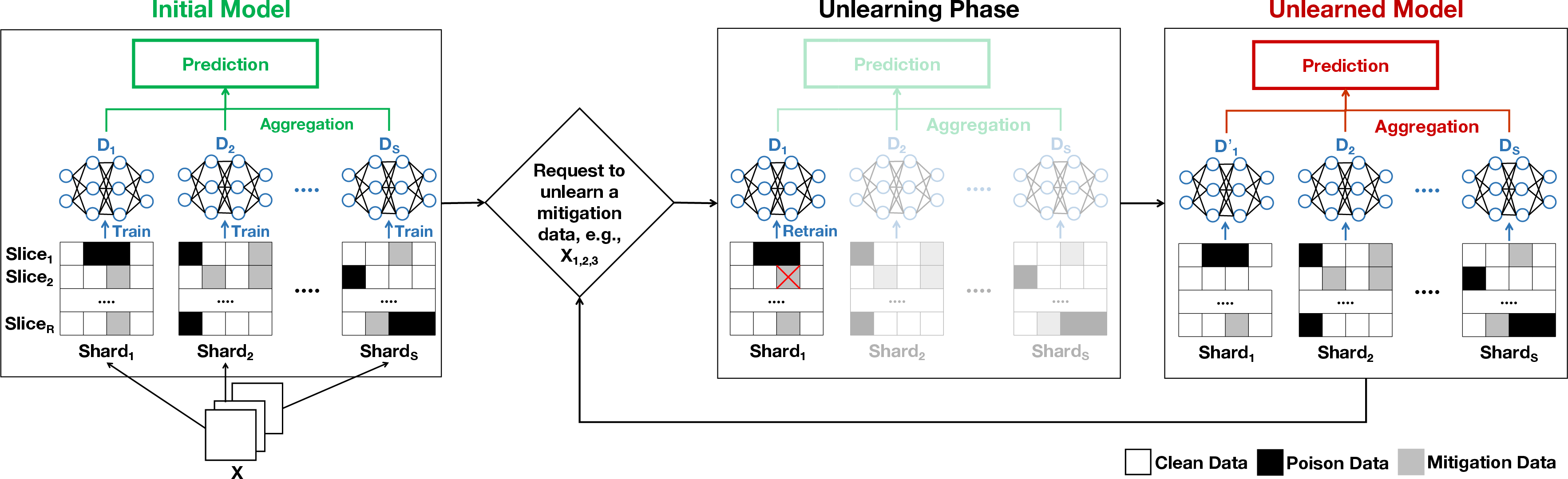
Figure 1: An overview of BAU under SISA setting. SISA~\cite{sisa}
Types of Backdoor Attacks: The paper also explores different methods of backdoor injection, including Input-Targeted-based attacks and BadNets-based attacks. The former exploits neighborhood variations in the input space, while the latter involves embedding specific patterns into input images as triggers.
Exact and Approximate Unlearning: The experiments are conducted both under exact unlearning (retraining the model from scratch) and approximate unlearning conditions using SISA. This approximation allows for faster computations, albeit with more memory usage.
Experimental Results
Exact Unlearning Performance: The findings reveal a significant increase in attack success rates when unlearning requests effectively remove mitigation samples. Importantly, this is achieved with minimal deductions in model accuracy. The approach's success is evident across various datasets including MNIST, FMNIST, GTSRB, and CIFAR10.
Impact of SISA Settings: Sharding has a notable effect on the difficulty of implementing the backdoor; more shards require an increased amount of poisoned samples. Slicing, however, shows less influence on the success of such attacks.
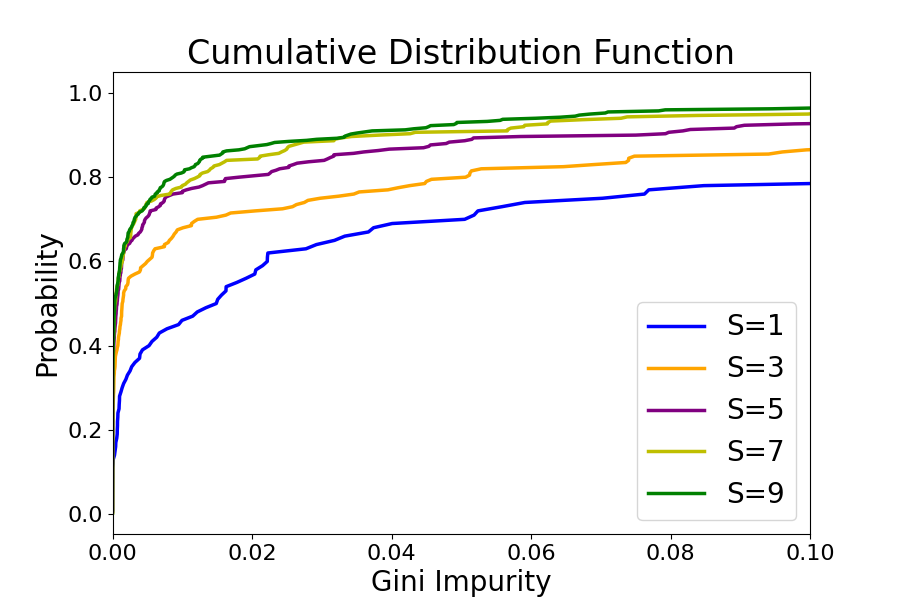
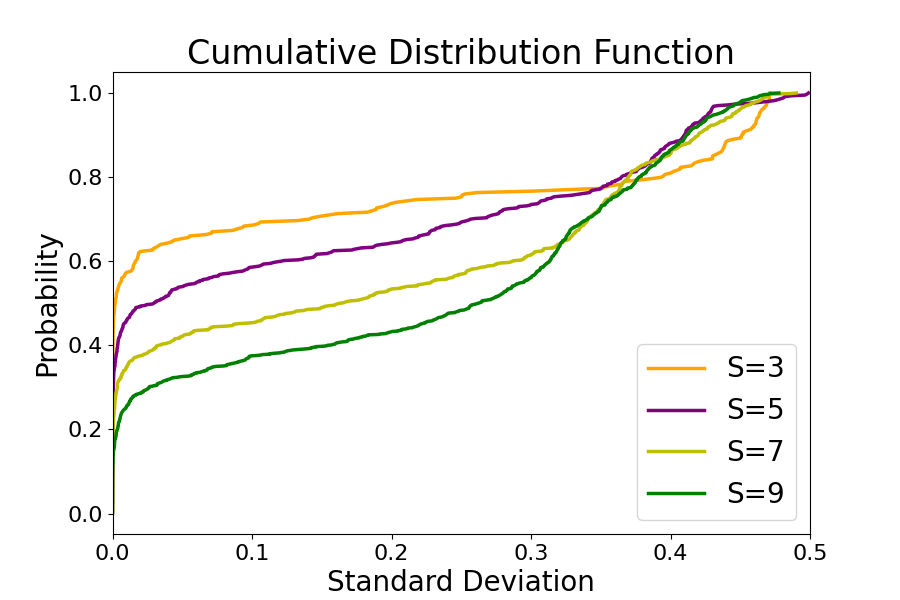
Figure 2: The Cumulative Distribution Function (CDF) w.r.t Gini impurity and standard deviation for BadNets-based BAU.
Defense Mechanisms
Detection Strategies: The paper presents detection methods focusing on model uncertainty and sub-model similarity, aimed at identifying malicious unlearning requests. By leveraging metrics like Gini impurity of output probabilities, these mechanisms can effectively discern the malicious nature of unlearning samples, limiting the success of BAU under specific conditions.
Implications and Future Directions
These innovations pose a new challenge landscape for ensuring AI model security. The unlearning-based attack mechanism exemplifies how privacy-preserving technologies can be subverted for malicious purposes. This invites further research into robust defenses that protect against not only traditional poisoning but also unlearning-driven attacks.
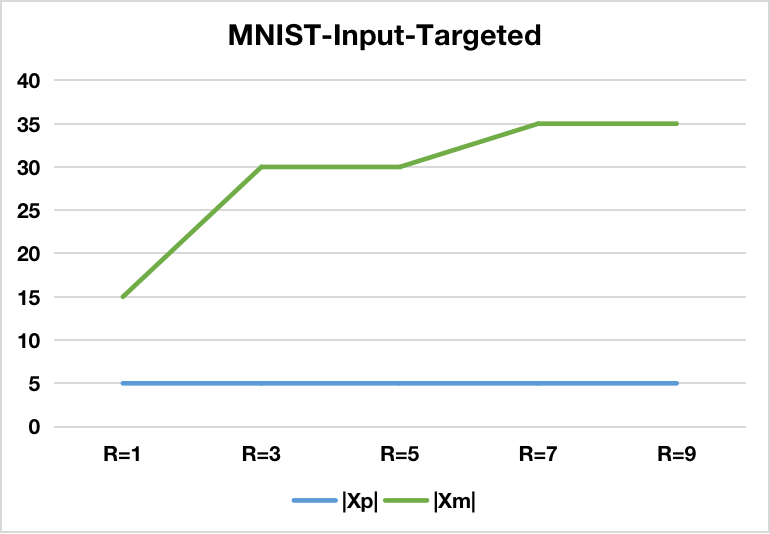
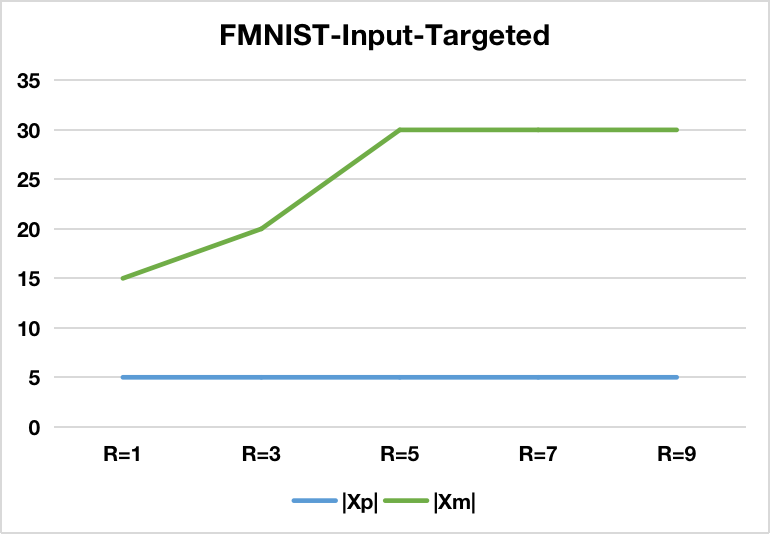
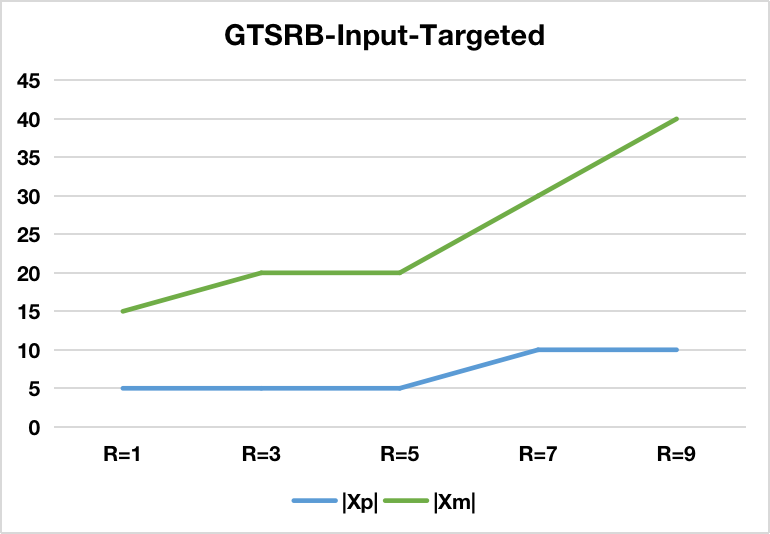
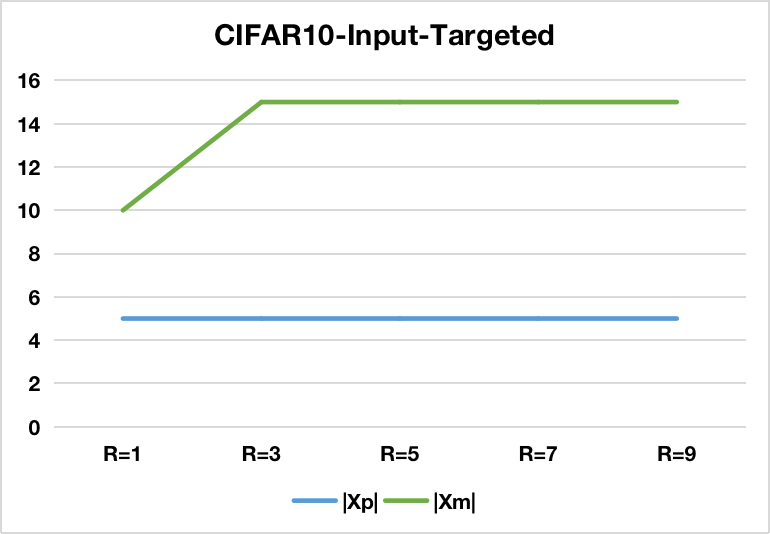
Figure 3: The effectiveness of Input-Targeted-based BAU w.r.t different number of slices (S=1).
Conclusion
The research presents a compelling case for the vulnerabilities introduced by machine unlearning in backdoor attacks. As machine unlearning becomes more prevalent for legal and ethical compliance, understanding these security ramifications will be critical for future AI deployments and standards.

