- The paper introduces IAP to measure attention head importance and demonstrates its effect on model performance.
- It presents IAT for fine-tuning key attention heads, reducing negative transfer and sharpening multi-task learning efficiency.
- Empirical results reveal that task similarity inversely correlates with functional specialization across various transformer models.
Interpreting and Exploiting Functional Specialization in Multi-Head Attention under Multi-task Learning
Introduction
The paper "Interpreting and Exploiting Functional Specialization in Multi-Head Attention under Multi-task Learning" addresses the obscure mechanisms of transformer models by examining their multi-head attention modules. Inspired by brain functional specialization, the authors propose methods to quantify and augment the functional specialization in multi-head attention under multi-task training. They introduce an interpretation technique dubbed Important Attention-head Pruning (IAP) and propose Important Attention-head Training (IAT) for enhancing specialization in task-specific attention heads.
Important Attention-head Pruning (IAP)
To ascertain functional specialization in attention heads, the authors developed IAP. This method involves calculating importance scores for each attention head by measuring their contribution to task performance. The most critical heads are then pruned to evaluate their effect on the model's functionality.
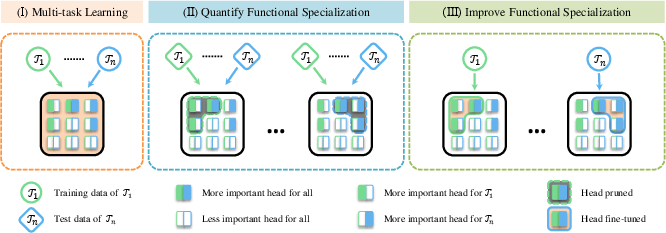
Figure 1: Illustration of how to quantify and improve the degree of functional specialization in multi-head attention for Transformer-based models.
Their findings indicate a negative correlation between task similarity and functional specialization. By applying IAP, they observe varied functional specialization phenomena within multi-head attention modules across different model sizes and pre-training methods, such as BERT and RoBERTa.
Important Attention-head Training (IAT)
IAT is designed to enhance the functional specialization of attention heads by exclusively fine-tuning the most crucial heads for individual tasks. This approach mitigates negative transfer between tasks, thereby improving multi-task learning performance.
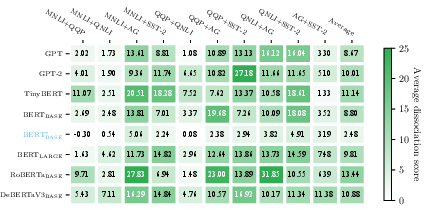
Figure 2: Average dissociation scores of different Transformer-based models after various dual-task learning tasks, showing specialization in multi-head attention.
The methodology leverages mask variables to selectively fine-tune important heads during the latter stages of training. Empirical results on the GLUE dataset demonstrate that IAT increases generalization capabilities and boosts model performance in both multi-task and transfer learning settings without adding parameters.
Task Similarity and Specialization
The study examines how task similarity influences functional specialization within multi-head attention. It establishes that a high similarity between tasks results in reduced functional specialization. The authors employ metrics like Cognitive-Neural Mapping to quantify task similarity.
Empirical Results and Analysis
Experimental results across seven transformer models and multiple tasks reveal consistent functional specialization. Models with task-specific fine-tuned heads exhibit marked improvements in processing distinct tasks, indicating significant operational separability in multi-head attention modules post multi-task learning.
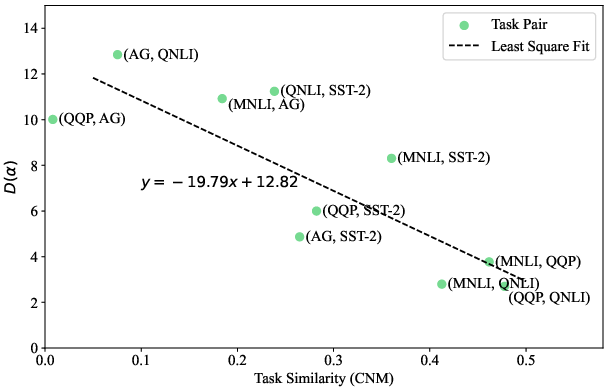
Figure 3: The average dissociation score and similarity of each task-pair in multi-task learning.
Implications and Future Directions
This research provides insights into the inner workings of transformer models and showcases how functional specialization can be harnessed to enhance model efficiency in multi-task scenarios. The methodologies proposed could inspire future explorations into other neural components that similarly benefit from specialization.
Conclusion
This paper underscores the potential of interpreting and exploiting functional specialization in transformer models to refine multi-task learning strategies. Future work may involve exploring similar phenomena in different neural network architectures and extending these findings to broader applications, potentially bridging neuroscience and artificial intelligence more closely.