- The paper introduces CapFSAR, which leverages automatically generated captions to create enriched multimodal representations for few-shot action recognition.
- It employs a Transformer-based fusion of visual features and text embeddings, significantly outperforming traditional unimodal models.
- Experimental results show a 5.6% accuracy boost on Kinetics in 1-shot assessments, highlighting its efficacy in data-limited scenarios.
Few-shot Action Recognition with Captioning Foundation Models
Introduction
The paper "Few-shot Action Recognition with Captioning Foundation Models" (2310.10125) proposes CapFSAR, a novel framework aimed at addressing the challenges associated with few-shot action recognition. Traditional approaches have primarily relied on unimodal vision models due to the prohibitive costs of annotating additional textual descriptions for videos. CapFSAR sidesteps these limitations by leveraging a captioning foundation model, BLIP, to automatically generate captions, thereby creating a richer multimodal representation without the need for manual text annotation. This study explores how transferring vision-language knowledge from pretrained multimodal models can effectively improve few-shot recognition tasks, which depend heavily on effective data exploitation in data-limited regimes.
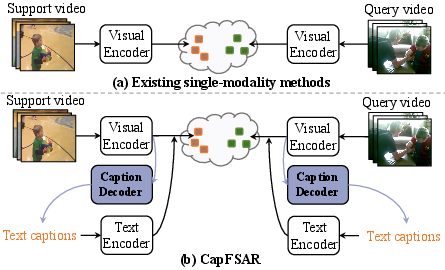
Figure 1: Comparison between existing methods and the proposed CapFSAR. (a) Traditional techniques utilize single visual modality; (b) CapFSAR generates captions for informative multimodal representations.
Framework Overview
CapFSAR utilizes BLIP in several critical stages to enhance input video categorization. Initially, a visual encoder processes the input video to extract visual features. These features are then fed into the caption decoder, producing synthetic text descriptors. The text encoder further processes these captions to obtain representative text embeddings. Lastly, a Transformer-based visual-text aggregation module is employed to integrate the multimodal data—capitalizing on spatio-temporal complementary information for reliable few-shot matching.
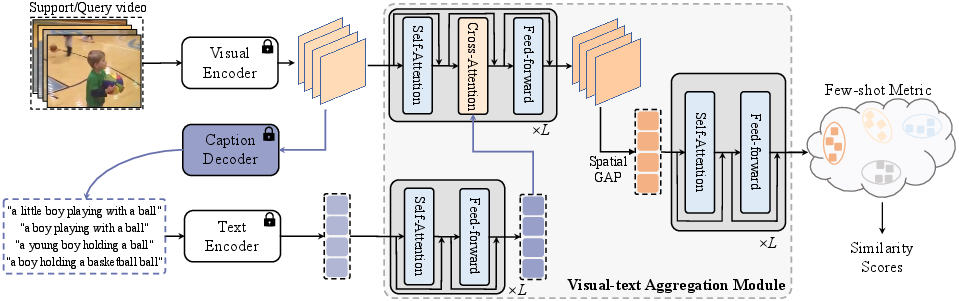
Figure 2: Overall pipeline of CapFSAR highlighting video encoding, caption generation, textual representation encoding, multimodal information fusion, and final classification.
Experimental Results
The efficacy of CapFSAR was benchmarked across various public datasets, including Kinetics, SSv2-Full, UCF101, SSv2-Small, and HMDB51. The framework demonstrated substantial performance enhancement over previous state-of-the-art methods by a considerable margin. Utilizing ImageNet pretrained ResNet-50 for fair comparison, CapFSAR, when applied to the HyRSM architecture, achieved 79.3% accuracy in 1-shot assessment, overtaking HyRSM by 5.6% on the Kinetics dataset. These results underscore the practical applicability and competitive advantage of integrating multimodal data over traditional unimodal approaches.
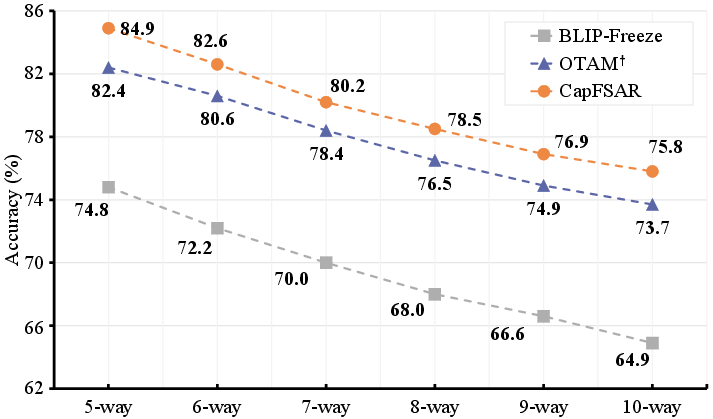
Figure 3: N-way 1-shot experiment on the Kinetics dataset.
Ablation Studies
Several ablation studies were conducted to shed light on the performance drivers within CapFSAR. Key findings affirm the role of the multimodal fusion strategy in enhancing classification outcomes. Experiments with various aggregation methods, the number of Transformer layers, and diverse caption generation techniques illustrate the nuanced impact of these design choices on the recognition performance. Notably, using CLIP as a text encoder demonstrated heightened success on appearance-biased tasks, whilst DeBERTa excelled in motion-biased datasets.
Qualitative Outcomes
Qualitative analysis further illuminates the benefits of integrating automatically generated captions. A comparative assessment of gradient heat maps between CapFSAR and baseline models reveals a marked focus on discriminative regions within the video frames, corroborating the utility of augmenting visual features with text.

Figure 4: Examples of the generated captions and GradCAM heat maps.
Implications and Future Directions
CapFSAR's advancements suggest significant potential for further exploration in the field of few-shot learning and multimodal data usage. The framework opens avenues for exploiting other advanced LLMs in similar tasks, enhancing adaptive learning capacities in complex environments. Future work could focus on optimizing computational efficiency or extending caption generation capabilities beyond current foundation models.
Conclusion
The research concludes that CapFSAR, through its innovative exploitation of multimodal foundation models, achieves state-of-the-art few-shot action recognition by harmonizing visual and textual data, thereby filling information gaps intrinsic to data-limited conditions. The framework holds promise for advancing multimodal approaches in learning scenarios demanding adaptability and generalization.

