- The paper demonstrates that LLMs exhibit a bias towards more verbose answers, deviating from precise human judgments.
- It employs experiments with GPT-4 and human feedback datasets to quantitatively measure divergence in evaluation between verbosity and conciseness.
- The study proposes mitigation strategies, including refined training protocols and prompt engineering, to align LLM evaluations with human preferences.
Verbosity Bias in Preference Labeling by LLMs
The paper "Verbosity Bias in Preference Labeling by LLMs" (2310.10076) explores the phenomenon where LLMs, such as GPT-4, display a preference for more verbose answers over concise ones when evaluating responses—a bias termed as verbosity bias. The authors explore this bias primarily within the context of Reinforcement Learning from AI Feedback (RLAIF), which substitutes the costly human feedback component in RLHF with evaluations from other LLMs. This paper examines this bias, its roots, and its implications on the performance and alignment of LLMs with human preferences and performance metrics.
Introduction to LLMs and Verbosity Bias
LLMs, noted for their extensive application across natural language processing tasks, have increasingly relied on reinforcement learning to fine-tune their performance. In the RLHF framework, human feedback is instrumental in improving model alignment with human evaluative standards. However, due to the high cost of human annotators, researchers propose leveraging LLM evaluations instead, termed RLAIF. Verbosity bias arises when LLMs favor lengthier responses, potentially leading to inefficiencies in chatbots and summarization. Despite recognizing verbosity bias, previous studies have primarily limited context and failed to compare LLM and human preferences directly. This paper aims to address this gap by systematically investigating verbosity bias across varied contexts, comparing it directly to human evaluations.

Figure 1: An example of a prompt to an LLM to judge two texts and the verdict. There is no one correct answer, and a comprehensive judgement is required.
Quantifying and Analyzing Verbosity Bias
The authors constructed experiments to discern how verbosity bias manifests within LLM evaluations. By employing GPT-4 and comparing its judgments against human feedback datasets (such as HH-RLHF), a metric was devised to quantitatively assess verbosity bias. This metric evaluates the divergence in LLM accuracy against human judgments when bias-induced verbosity interferes. Figures within the paper demonstrate that GPT-4 tends to prefer verbose answers (Figure 2), especially when human-evaluated succinct responses provide more accurate or helpful content compared to verbose counterparts.
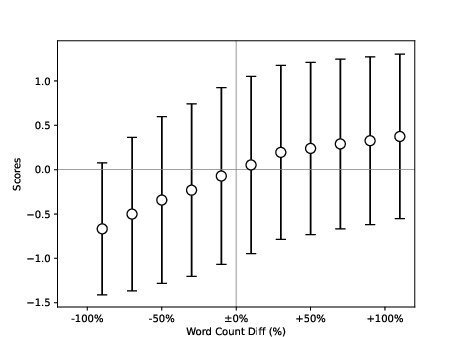
Figure 2: X-axis is the percentage of the difference between the first and the second option compared to the length of the second option. Y-axis is the resulting score by human judgement.
Implications and Mitigation Strategies
The implications of verbosity bias are significant; they suggest inefficiencies may pervade LLM applications due to unwarranted verbosity, particularly when utilized in settings where precision and conciseness are valued. The authors propose several mitigation strategies, including adjusting training protocols to account for verbosity, incorporating calibration techniques akin to those used for position and self-enhancement biases, and utilizing enhanced prompt engineering like chain-of-thought prompting. These methods aim to rectify verbosity bias, aligning LLM evaluations more closely with human judgment without compromising efficiency or effectiveness.
Conclusion
The research elucidates a critical area of bias present in LLM evaluations, emphasizing the discrepancy between LLM and human preferences in answer length and its influence on evaluation efficacy. By refining the process through which LLMs are trained and evaluated using AI feedback mechanisms, verbosity bias can be mitigated, improving model alignment with intended performance metrics and user expectations. This paper contributes significantly to understanding and reducing bias in preference labeling, suggesting pathways for further exploration and refinement of LLM evaluation frameworks. Such insights hold promising implications for the future refinements of RLAIF methodologies and the broader application of LLMs across various domains.