- The paper demonstrates that Vec2Text accurately recovers text from embeddings using iterative hypothesis refinement, achieving a BLEU score of 97.3 and 92% recovery rate for 32-token inputs.
- The method leverages cosine similarity and sequence-level beam search to optimize generated hypotheses, outperforming traditional Bag-of-Words and single-step decoding techniques.
- The study highlights privacy vulnerabilities in text embeddings and proposes adding Gaussian noise as an effective defense mechanism without severely impairing retrieval performance.
Embedding Inversion: Analyzing "Text Embeddings Reveal (Almost) As Much As Text" (2310.06816)
The paper investigates the potential privacy risks associated with text embeddings by proposing a novel method for inverting embeddings to reconstruct their original text. The core contribution is the Vec2Text method, which iteratively refines text hypotheses to recover inputs represented by dense embeddings, posing potential risks to sensitive information stored in vector databases.
Methodology: Vec2Text
Overview of Vec2Text Approach
The problem of inverting text embeddings is framed as a task of controlled text generation. Vec2Text iteratively generates and corrects text hypotheses to align closely with a given embedding in latent space. The method leverages the cosine similarity between hypothesis and target embeddings as a metric for proximity, optimizing hypotheses through iterative feedback loops to refine the reconstruction process.
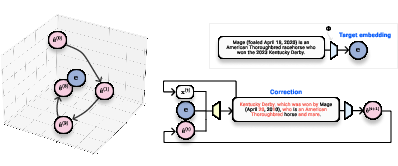
Figure 1: Overview of our method, Vec2Text. Given access to a target embedding e and query access to an embedding model ϕ, the system aims to iteratively generate hypotheses e^ to reach the target.
Operational Details
The backbone of Vec2Text employs an encoder-decoder transformer for parameterization. Initially, a hypothesis is guessed and iteratively re-embedded to minimize the cosine distance to the target embedding. Each hypothesis serves as a starting point for subsequent re-embedding and correction, enabling recovery of complex semantic structures. The model requires querying the embedding function ϕ during each iterative step, making it crucial to efficiently manage query usage in practical deployments.
Evaluation: Performance Across Domains
In-Domain Reconstruction
The paper demonstrates the efficacy of Vec2Text by achieving a near-perfect BLEU score of 97.3 and recovering 92% of 32-token inputs. The technique shows superior performance compared to baseline methods like Bag-of-Words and direct decoders. Testing reveals that more rounds of refinement enhance reconstruction quality, with sequence-level beam search yielding significant improvements in exact match percentages.
Out-of-Domain Reconstruction
Extensive evaluation on BEIR benchmark datasets reveals that Vec2Text adapts well across text domains. While performance varies with text length, the method consistently achieves high token F1 and cosine similarity, underscoring its robustness. Specific applications to the MIMIC-III clinical notes (pseudo re-identified version) demonstrate that full names can be reconstructed with high accuracy, raising concerns about privacy in medical contexts.
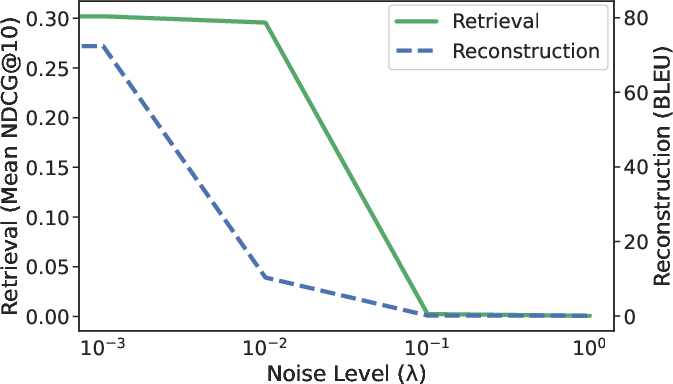
Figure 2: Retrieval performance and reconstruction accuracy across varying levels of noise injection.
Defending Against Inversion Attacks
The paper suggests adding Gaussian noise to embeddings as a straightforward defense mechanism. The analysis shows that minor noise levels can significantly degrade inversion accuracy while preserving retrieval performance, providing a potential avenue for enhancing privacy without severely impairing functional utility.
The study articulates the relationship between feedback during iterative hypothesis correction and model performance. Feedback from the embedding model, ϕ, markedly enhances Vec2Text's corrective capability, as indicated by ablation studies.
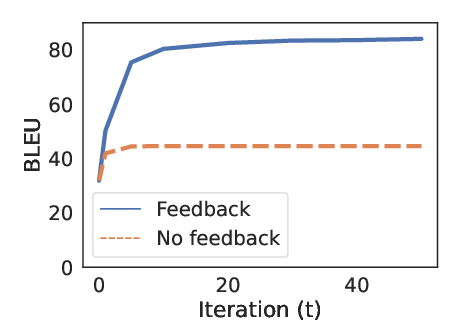
Figure 3: Recovery performance across multiple rounds of self-correction comparing models with access to ϕ vs text-only.
Privacy implications are discussed in analogy to existing research on inverting visual embeddings and gradient leakage. Prior methods in text embedding inversion, such as single-step query decoders and bag-of-words recovery, are contrasted with Vec2Text's multi-step refinements, which unveil latent privacy vulnerabilities in modern NLP systems.
Conclusion
This paper illustrates the potential for text embedding inversion to compromise data privacy, suggesting rigorous protection strategies for text embeddings akin to raw text data. While Vec2Text demonstrates superior recovery capability of short text embeddings, considerations such as adaptive defenses, sequence-level scaling, and embedding model dependencies remain critical for future exploration.
In conclusion, the method's ability to reconstruct structured data from embeddings suggests a need for heightened awareness and proactive defense mechanisms in applications deploying sensitive information through embeddings.