Simulating Social Media Using Large Language Models to Evaluate Alternative News Feed Algorithms
Abstract: Social media is often criticized for amplifying toxic discourse and discouraging constructive conversations. But designing social media platforms to promote better conversations is inherently challenging. This paper asks whether simulating social media through a combination of LLMs (LLM) and Agent-Based Modeling can help researchers study how different news feed algorithms shape the quality of online conversations. We create realistic personas using data from the American National Election Study to populate simulated social media platforms. Next, we prompt the agents to read and share news articles - and like or comment upon each other's messages - within three platforms that use different news feed algorithms. In the first platform, users see the most liked and commented posts from users whom they follow. In the second, they see posts from all users - even those outside their own network. The third platform employs a novel "bridging" algorithm that highlights posts that are liked by people with opposing political views. We find this bridging algorithm promotes more constructive, non-toxic, conversation across political divides than the other two models. Though further research is needed to evaluate these findings, we argue that LLMs hold considerable potential to improve simulation research on social media and many other complex social settings.
- \JournalTitleProceedings of the National Academy of Sciences 115, 9216–9221 (2018) Publisher: National Acad Sciences.
- \JournalTitleScience (New York, N.Y.) 370, 533–536 (2020) Publisher: American Association for the Advancement of Science.
- \JournalTitleNature human behaviour pp. 1–28 (2022) Publisher: Nature Publishing Group.
- (Cambridge University Press, Cambridge, United Kingdom ; New York, NY), (2020).
- JE Settle, Frenemies: How Social Media Polarizes America. (Cambridge University Press, Cambridge ; New York), (2018).
- P Barberá, Birds of the Same Feather Tweet Together: Bayesian Ideal Point Estimation Using Twitter Data. \JournalTitlePolitical Analysis 23, 76–91 (2015).
- \JournalTitleProceedings of the National Academy of Sciences 118, e2023301118 (2021) Publisher: National Academy of Sciences Section: Physical Sciences.
- CR Sunstein, Republic.com. (Princeton University Press, Princeton, N.J.), (2002).
- \JournalTitleProceedings of the National Academy of Sciences 114, 7313–7318 (2017) Publisher: National Academy of Sciences Section: Social Sciences.
- \JournalTitleProceedings of the National Academy of Sciences 118 (2021) Publisher: National Academy of Sciences Section: Social Sciences.
- \JournalTitlePolitical Communication 37, 423–446 (2020) Publisher: Routledge _eprint: https://doi.org/10.1080/10584609.2020.1713267.
- P Törnberg, How digital media drive affective polarization through partisan sorting. \JournalTitleProceedings of the National Academy of Sciences 119, e2207159119 (2022) Publisher: Proceedings of the National Academy of Sciences.
- MA Franks, Beyond the Public Square: Imagining Digital Democracy. \JournalTitleThe Yale Law Journal 131 (2021).
- \JournalTitleSocial Media + Society 8, 20563051221130447 (2022) Publisher: SAGE Publications Ltd.
- \JournalTitleSAGE Open 9, 1–21 (2019).
- \JournalTitleScience 381, 392–398 (2023) Publisher: American Association for the Advancement of Science.
- \JournalTitleScience 381, 398–404 (2023) Publisher: American Association for the Advancement of Science.
- \JournalTitleScience 381, 404–408 (2023).
- \JournalTitleCrowd-sourced literature review (2022).
- \JournalTitleNature 620, 137–144 (2023).
- C Bail, Breaking the Social Media Prism: How to Make our Platforms Less Polarizing. (Princeton University Press, Princeton, N.J), (2021).
- \JournalTitleWorking paper (2023).
- Y Benkler, The Wealth of Networks: How Social Production Transforms Markets and Freedom. (Yale University Press, New Haven Conn.), (2007).
- M Castells, Networks of Outrage and Hope: Social Movements in the Internet Age. (Polity, Cambridge, UK ; Malden, MA), 1 edition edition, (2012).
- (Penguin Randonhouse, New York), (2020).
- J Dewey, The Public and Its Problems. (Swallow Press, Athens), 1 edition edition, (1927).
- J Habermas, The Structural Transformation of the Public Sphere: An Inquiry into a Category of Bourgeois Society. (The MIT Press, Cambridge, Mass), Sixth printing edition edition, (1989).
- \JournalTitlearXiv:2008.00049 [cs, stat] (2020) arXiv: 2008.00049.
- \JournalTitleProceedings of the National Academy of Sciences 118, e2025764118 (2021) Publisher: Proceedings of the National Academy of Sciences.
- (Routledge), (2023).
- D Garcia, Influence of Facebook algorithms on political polarization tested. \JournalTitleNature 620, 39–41 (2023) Bandiera_abtest: a Cg_type: News And Views Number: 7972 Publisher: Nature Publishing Group Subject_term: Society, Politics.
- MW Wagner, Independence by permission. \JournalTitleScience 381, 388–391 (2023) Publisher: American Association for the Advancement of Science.
- D Freelon, Computational Research in the Post-API Age. \JournalTitlePolitical Communication 35, 665–668 (2018) Publisher: Routledge _eprint: https://doi.org/10.1080/10584609.2018.1477506.
- JM Epstein, Generative social science: Studies in agent-based computational modeling. (Princeton University Press) Vol. 13, (2006).
- \JournalTitleAnnual Review of Sociology 28, 143–166 (2002) _eprint: https://doi.org/10.1146/annurev.soc.28.110601.141117.
- R Axelrod, The dissemination of culture: A model with local convergence and global polarization. \JournalTitleJournal of conflict resolution 41, 203–226 (1997) Publisher: Sage Periodicals Press 2455 Teller Road, Thousand Oaks, CA 91320.
- \JournalTitleInternational Journal of Modern Physics C 31, 2050101 (2020) Publisher: World Scientific.
- pp. 48–55 (2007) Isbn: 9781577353492.
- \JournalTitleFrontiers in psychology 5, 668 (2014) Publisher: Frontiers Media SA.
- C Bail, Can Generative AI Improve Social Science? (2023).
- \JournalTitleScience 380, 1108–1109 (2023) Publisher: American Association for the Advancement of Science.
- \JournalTitlearXiv preprint arXiv:2206.07682 (2022).
- P Törnberg, Chatgpt-4 outperforms experts and crowd workers in annotating political twitter messages with zero-shot learning. \JournalTitlearXiv preprint arXiv:2304.06588 (2023).
- \JournalTitlearXiv preprint arXiv:2303.12712 (2023).
- \JournalTitlePolitical Analysis pp. 1–15 (2023) Publisher: Cambridge University Press.
- \JournalTitleInternational Journal of Intercultural Relations 81, 131–141 (2021).
- \JournalTitleScience Advances 7, eabe5641 (2021) Publisher: American Association for the Advancement of Science.
- \JournalTitleProceedings of the National Academy of Sciences 119 (2022) Publisher: National Academy of Sciences Section: Social Sciences.
- \JournalTitlearXiv preprint arXiv:2210.15723 (2022).
- \JournalTitleTheories, Models, and Simulations Not Just Big Data (May 24, 2016) (2016).
- \JournalTitleJournal of Computational Social Science 1, 3–14 (2018).
- (University Of Chicago Press, Chicago), (1980).
- PE Converse, The nature of belief systems in mass publics. \JournalTitleCritical Review 18, 1–74 (1964).
- \JournalTitleProceedings of the National Academy of Sciences 110, 5791–5796 (2013) ISBN: 1091-6490 (Electronic)\r0027-8424 (Linking).
- \JournalTitleAmerican Journal of Sociology 120, 1473–1511 (2015) Publisher: The University of Chicago Press.
- \JournalTitleMobilization: An International Quarterly 20, 253–268 (2015) Publisher: Hank Johnston DBA Mobilization Journal.
- \JournalTitleBrookings (2023).
- (Association for Computing Machinery, New York, NY, USA), pp. 610–623 (2021).
- P Törnberg, How to use LLMs for Text Analysis (2023) arXiv:2307.13106 [cs].
- A Christin, The ethnographer and the algorithm: beyond the black box. \JournalTitleTheory and Society 49, 897–918 (2020).
- R Axelrod, The Complexity of Cooperation: Agent-Based Models of Competition and Collaboration: Agent-Based Models of Competition and Collaboration. (Princeton university press), (1997).



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simulating Social Media to Test Better News Feeds
Overview
This paper explores a big question: can we redesign social media so people with different political views talk to each other more, without the conversation turning nasty? The authors build a “fake” social media world using AI to try out different ways of showing posts in the news feed and see what happens.
What questions does the paper ask?
- Can changing the news feed algorithm (the rules that decide which posts you see) encourage conversations between people who disagree politically?
- Can it do this while reducing toxic language (rude, insulting, or aggressive comments)?
- Which types of news feed rules help most?
How did the researchers study this?
Think of this like running a very detailed game or simulation:
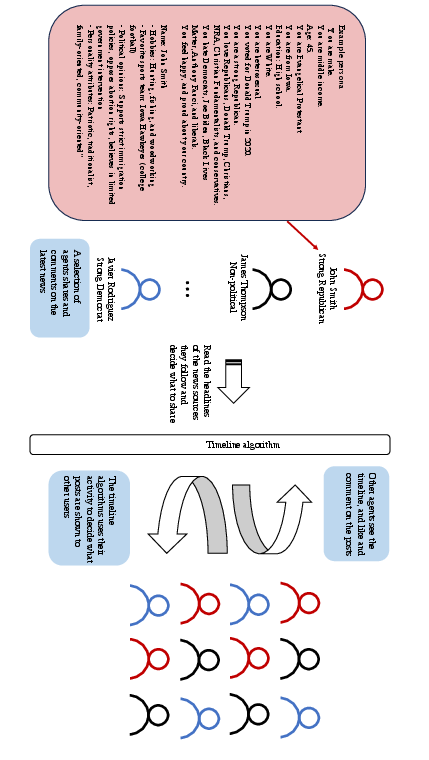
- Agent-Based Modeling (ABM): Imagine a digital version of “The Sims,” but for social media. Each “agent” is a pretend user with a profile and habits. The goal is to see how many small actions (like liking and commenting) add up to big patterns (like more or less toxicity).
- LLMs: These are AI systems (like advanced chatbots) trained to talk like humans. Here, the AI agents read news, write posts, like, and comment in ways that feel realistic.
To make the pretend users believable, the team created 500 “personas” based on real survey data from the American National Election Study (ANES). Each persona included:
- Basic details (like age and political leaning)
- How often they use social media
- Their favorite news sources and hobbies
- Whether they usually talk about politics or not
The agents interacted for roughly one simulated day (July 1, 2020), using real news summaries from that date (topics included COVID-19, Black Lives Matter, and sports).
Before reading the findings, here are the three news feed designs they tested. This list helps set the stage:
- Platform 1: Show top posts only from accounts the user already follows (an “echo chamber” style).
- Platform 2: Show top posts from anyone on the platform, even if the user doesn’t follow them (break the echo chamber).
- Platform 3: A “bridging” algorithm. Show posts that get likes from people on the opposite political side of the person who wrote the post (reward cross-party appreciation).
To measure outcomes:
- Toxicity was scored with an automated tool (Perspective API) that estimates how rude or aggressive language is.
- Cross-party interaction was tracked with a simple index showing whether people mostly engage with their own side (negative scores) or across sides (positive scores).
What did they find, and why does it matter?
- Platform 1 (follow-only): Low toxicity but almost no cross-party interaction. People mostly stayed in their bubbles and didn’t fight—but also didn’t talk across political lines.
- Platform 2 (all high-engagement posts): More cross-party interaction—but much more toxicity. When people saw popular posts from the other side, they often reacted angrily, which boosted visibility of those heated posts and made the feed feel meaner overall.
- Platform 3 (bridging algorithm): The best mix. It increased cross-party conversation and had the lowest toxicity of all three, even lower than the echo chamber platform. It tended to highlight topics or posts appreciated across political lines, making the space feel more constructive.
Why this matters: It suggests that social media can be designed to encourage helpful conversations between people who disagree—if platforms reward posts that earn respect from both sides, not just any kind of attention.
What’s the bigger impact?
- For social media companies: This offers a new idea—promote posts that are liked across differences. Doing so might reduce fights and help more moderate voices be heard.
- For society and democracy: More civil, cross-party conversations could help people understand each other better and reduce polarization.
- For researchers: Combining LLMs (AI that can “talk”) with ABMs (simulations of many interacting users) is a promising way to study complex online behavior without running risky real-world experiments.
A simple note on limitations and next steps
This was an early test:
- It used 500 agents and only one simulated day—real platforms are much bigger and more complex.
- AI can be biased and may not perfectly represent all kinds of people.
- The results were measured with automated tools; the team plans to check with human reviewers.
Even so, the study shows a clear direction: news feeds that reward cross-party appreciation—not just raw engagement—could help social media become more constructive and less toxic.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following unresolved issues that future researchers could address:
- Validation with humans: No assessment by human coders or participants to judge realism, conversational quality, and constructiveness beyond toxicity; design and run human evaluation studies (annotation, pairwise comparisons, Turing-style realism tests).
- Outcome metrics beyond toxicity: Reliance on Perspective API and E-I index; develop multi-dimensional measures (civility, empathy, argument quality, persuasion, accuracy, coherence, mutual understanding, norm adherence) and validate them.
- Scale and duration: Simulation limited to 500 agents and ~one day; examine scaling to tens/hundreds of thousands of agents and multi-week/month dynamics, including virality, cascades, and saturation effects.
- Temporal dynamics and learning: Agents lack memory, attitude updating, and relationship evolution; implement social learning, longitudinal changes, and follow/unfollow behavior to study long-run algorithm effects.
- Strategic behavior and gaming: Users do not adapt to or exploit the algorithm; test adversarial scenarios (brigading, trolling, sockpuppets, bots) and robustness of bridging criteria to manipulation.
- Reproducibility and model dependence: Results depend on a proprietary LLM (GPT-3.5) with undisclosed training data; perform sensitivity analyses across models (open-source vs proprietary), prompts, temperatures, and seeds, and report run-to-run variability.
- Calibration to real behavior: Personas generated from ANES plus LLM-added traits may not represent real posting/engagement patterns; calibrate agent behavior using platform data (e.g., tweets, likes, network properties) and quantify calibration error.
- Treatment of nonpartisans: Many agents are independents/nonpolitical; specify how bridging is computed for nonpartisans and test alternative definitions (e.g., ideological distance rather than binary party labels).
- Multidimensional divides: Bridging defined solely on party; generalize to other salient cleavages (ideology, geography, race/ethnicity, religion, media diet) and test whether bridging works across multiple axes simultaneously.
- Ranking realism: Algorithms use simple engagement signals (likes, comments) without time decay, personalization, diversity heuristics, predictions, or reshares/quote-tweets; implement more realistic ranking (ML-based predictors, multi-objective optimization).
- Comment valence and stance: E-I counts cross-party comments but does not distinguish supportive vs hostile content; add stance/sentiment/intent classification to separate constructive from antagonistic interactions.
- Topic dependence: Results based on 15 news stories from a single day; conduct topic-sensitive and event-sensitive analyses across varied news cycles (elections, crises, non-political content) and measure stability.
- Network topology assumptions: Fixed network with 30 follows, homophily on politics; test alternative structures (scale-free, small-world, community partitions, degree heterogeneity) and dynamic network evolution over time.
- Moderation and platform governance: No content moderation policies or enforcement modeled; incorporate moderation rules, takedown rates, and their interaction with ranking algorithms and toxicity.
- Coordinated inauthentic behavior: No simulation of botnets, paid campaigns, or coordinated misinformation; examine how bridging interacts with detection systems and adversarial actors.
- Exposure vs action: Timeline shows “visible posts,” but agent attention/reading is not modeled; build attention models (position bias, dwell time) to connect ranking, exposure, and subsequent behavior.
- Fairness and minority voices: Bridging may favor centrist or mainstream content and inadvertently suppress minority or niche viewpoints; conduct fairness audits and measure impacts on content diversity and marginalized groups.
- Misinformation and accuracy: Bridging optimizes cross-party likes, not truthfulness; add misinformation detection and factuality metrics, and study trade-offs with consensus optimization.
- Cross-linguistic and cross-national generalizability: Only US-English context; replicate across languages and countries to test cultural robustness and LLM competence beyond English.
- Multimodality: Simulation is text-only; extend to images, video, and memes to reflect real platform content and evaluate effects on toxicity and engagement.
- Memory and identity consistency: Agents lack persistent state; implement working memory or agent-state to maintain identities, preferences, and ongoing conversational threads.
- Parameter sensitivity and uncertainty: No reported confidence intervals or sensitivity analyses; perform parameter sweeps (posting propensity, follow count, homophily strength, algorithm weights) and quantify uncertainty.
- Ethical/legal constraints of calibration: Training on real user data raises privacy and consent issues; develop ethical frameworks, de-identification pipelines, and IRB-compliant protocols for agent calibration.
- Data leakage and temporal knowledge: Retrospective LLM training and unclear cutoff relative to July 2020; verify and control for model knowledge of events, or use retrieval/browsing models to manage contemporaneity.
- Open research infrastructure: Need for an open-source, research-grade LLM and standardized simulation benchmarks; specify requirements (transparent training data, safety guardrails) and build shared datasets and evaluation suites.
Practical Applications
Overview
This paper introduces a hybrid LLM plus Agent-Based Modeling (ABM) framework to simulate social media platforms and evaluate alternative news feed algorithms. Its core innovation is a “bridging” algorithm that ranks posts by cross-partisan positive reactions (likes from users with opposing political views). In LLM-driven simulations calibrated with personas constructed from ANES data, the bridging algorithm increased cross-party engagement and reduced toxicity compared to follower-only and engagement-maximizing feeds.
Below are practical, real-world applications grounded in the paper’s findings, methods, and innovations. Each application notes relevant sectors, potential tools or workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
The following list summarizes applications that can be piloted or deployed with current tooling and reasonable operational effort.
- Social media product teams: A/B test a “bridging ranker” alongside engagement-based and follower-only feeds
- Sectors: software/platforms (Twitter/X, Threads, Reddit, Bluesky, Mastodon)
- Tools/workflows: a ranking feature that boosts posts liked across ideological lines; evaluation with toxicity (Perspective API or human coders) and inter-group E–I metrics
- Assumptions/dependencies: reliable estimation of users’ political leanings (text classifiers or behavioral signals); safeguards against coordinated manipulation or brigading; legal/privacy compliance
- Trust & Safety pre-deployment sandbox: Offline LLM–ABM simulations to audit algorithm changes for toxicity and cross-group effects before rollout
- Sectors: social platforms, civic tech
- Tools/workflows: synthetic user panels (LLM personas), Perspective API toxicity checks, E–I index; “algorithmic impact” dashboards
- Assumptions/dependencies: LLM calibration biases; need for human validation and multi-model checks to avoid overfitting to one LLM; compute costs
- Synthetic user panels for research and product discovery: Rapid hypothesis testing of interventions (e.g., de-amplification rules, comment prompts)
- Sectors: academia, UX research, product R&D
- Tools/workflows: persona generation from survey data (ANES-like), scripted scenarios, outcome measures (toxicity, cross-group engagement)
- Assumptions/dependencies: representativeness of personas; RLHF politeness bias; use as complement—not substitute—for human studies
- Newsroom and publisher comment sections: Pilot bridging-based comment ranking to promote constructive discussion
- Sectors: journalism/media
- Tools/workflows: comment sort by cross-ideology likes; moderation integration; civility nudges
- Assumptions/dependencies: accurate inference of commenter leanings; risk of misclassification; editorial policy alignment
- Civic platforms and municipal forums: Adopt bridging ranking for public consultations and town-hall style comment feeds
- Sectors: civic tech, public sector
- Tools/workflows: configurable “bridging boost” in public feedback portals; transparency notices
- Assumptions/dependencies: sensitivity around inferring political views; local legal constraints; accessibility and fairness considerations
- Enterprise social tools: Bridge across functions or teams to reduce siloed communication (use “opposing views” along organizational lines)
- Sectors: enterprise software, HR/Org design
- Tools/workflows: feed re-ranker in internal platforms (Slack/Teams clones); “constructive engagement” KPI
- Assumptions/dependencies: non-political proxy signals (team, domain); cultural fit; change management
- Education/LMS discussion forums: Bridging-based discussion sorting for classroom debates to spotlight consensus-bridging contributions
- Sectors: education/EdTech
- Tools/workflows: LMS plugins; instructor dashboards tracking E–I index and civility
- Assumptions/dependencies: age-appropriate use; moderation guardrails; non-political contexts or careful framing
- Browser extension re-ranker: Consumer tool to re-order feeds emphasizing cross-ideology validation (where APIs permit)
- Sectors: consumer software
- Tools/workflows: extension reads available metadata or infers leanings from text; user-configurable “bridge boost”
- Assumptions/dependencies: platform API access/ToS compliance; opacity of ideology signals; security/privacy concerns
- Brand safety and campaign pre-tests: Synthetic social simulations to preview how content resonates across groups and potential toxicity
- Sectors: marketing/advertising, corporate communications
- Tools/workflows: scenario runs with target personas; diagnostic reports (toxicity, bridging potential)
- Assumptions/dependencies: LLM realism; use as an early filter, not definitive predictor; validate with small-scale human panels
- Computational social science workflows: Use the LLM–ABM framework to study polarization, framing, and discourse dynamics ethically
- Sectors: academia/research
- Tools/workflows: open-source codebase for persona creation, feed simulation, evaluation metrics (E–I index, toxicity)
- Assumptions/dependencies: reproducibility across LLMs; IRB/ethics; variable generalization beyond U.S. context
Long-Term Applications
The following list summarizes applications that require further research, scaling, infrastructure, or policy development.
- Open, research-grade social simulation LLMs and datasets
- Sectors: AI research, academia
- Tools/workflows: open-source LLM tuned for social simulation; public persona libraries; benchmark tasks and metrics
- Assumptions/dependencies: funding, governance to prevent misuse; multi-lingual coverage; safety tooling
- Regulatory algorithmic impact assessments: Formalize pre-deployment simulation requirements for major platform changes
- Sectors: policy/regulation
- Tools/workflows: standardized toxicity and inter-group engagement reporting; third-party auditing
- Assumptions/dependencies: agreed-upon metrics (e.g., E–I index, civility scores); oversight structures; platform cooperation
- Global and cross-cultural calibration: Extend personas and bridging signals beyond U.S. to diverse contexts and languages
- Sectors: international platforms, policy, academia
- Tools/workflows: country-specific survey integration; multi-lingual LLMs; local validation studies
- Assumptions/dependencies: high-quality local data; cultural nuance; fairness across groups
- Dynamic co-evolution and long-horizon simulations: Model memory, learning, and network change over weeks/months
- Sectors: academia/platform R&D
- Tools/workflows: agent memory architectures; longitudinal scenarios; co-evolution of user–algorithm strategies
- Assumptions/dependencies: compute scale; robust evaluation; emergent behavior tracking
- Robustness against manipulation: Adversarial stress-testing of bridging algorithms to prevent brigading or coordinated inauthentic behavior
- Sectors: trust & safety, security
- Tools/workflows: red-teaming with synthetic adversaries; anomaly detection; resilience metrics
- Assumptions/dependencies: realistic attacker models; continuous monitoring; transparent mitigation policies
- Misinformation containment and crisis communication: Use bridging signals to throttle polarizing misinformation while preserving constructive cross-group dialogue
- Sectors: healthcare, public safety, elections, climate communication
- Tools/workflows: intervention design (labels, slow-downs, boosts); synthetic trials to evaluate spillovers and harm reduction
- Assumptions/dependencies: credible misinformation detection; ethical review; jurisdiction-specific rules
- KPI redesign toward “constructive engagement”: Institutionalize metrics that balance reach with reduced toxicity and increased cross-group consensus
- Sectors: product management, platform strategy
- Tools/workflows: composite metrics (E–I index, civility/toxicity, mutual validation); dashboards tied to OKRs
- Assumptions/dependencies: revenue trade-offs; stakeholder buy-in; long-term incentive alignment
- Privacy-preserving ideology inference: Develop methods to approximate cross-partisan signals without storing sensitive political attributes
- Sectors: data science, privacy engineering
- Tools/workflows: differential privacy, federated learning, text-based proxies; uncertainty-aware ranking
- Assumptions/dependencies: accuracy vs privacy balance; regulatory compliance (GDPR/CCPA); explainability
- Scaled civic dialogue infrastructure: Deploy bridging algorithms in public forums (cities, parliaments, NGOs) to foster consensus-building
- Sectors: government, NGOs, civic platforms
- Tools/workflows: governance models; transparency reports; facilitator training
- Assumptions/dependencies: political will; inclusivity safeguards; localized measurement standards
- Multi-model, multi-stakeholder simulation consortia: Shared sandboxes across academia, platforms, and regulators for reproducible evaluation
- Sectors: academia, industry, policy
- Tools/workflows: standardized protocols and datasets; cross-LLM ensembles; public benchmarks and leaderboards
- Assumptions/dependencies: interoperability agreements; funding; secure compute and data stewardship
Glossary
- Agent-Based Models (ABM): Computational simulations where autonomous agents follow rules and interact to produce system-level patterns. "Agent-Based Models (ABM) have been used to study complex social systems for decades, enabling the identification of emergent, group-level mechanisms that could not be predicted using the characteristics of individuals within a social system alone."
- American National Election Study (ANES): A large, nationally representative survey of U.S. political attitudes and behaviors used to construct agent personas. "We employed data from the American National Election Study (ANES) — a large, nationally representative study of political attitudes and behaviors that includes measures of social media usage as well as demographic variables."
- Bridging algorithm: A ranking strategy that prioritizes posts positively received across opposing viewpoints to foster constructive cross-group dialogue. "The third platform employs a novel “bridging” algorithm that highlights posts that are liked by people with opposing political views."
- Computational social science: An interdisciplinary field that uses computational methods to study social phenomena and behavior at scale. "These results may have important implications for the study of polarization, political communication, and social media as well as the broader field of computational social science."
- Cross-partisan interaction: Engagement between users who belong to different political parties. "encouraging cross-partisan interaction among social media users may produce more toxic discourse, which we define here as conversations that are rude, disrespectful, or unreasonable."
- Echo chambers: Online environments where users mainly encounter like-minded content, limiting exposure to opposing views. "Many argue that Facebook, Twitter, and other platforms trap people within “echo chambers” or “filter bubbles” that prevent exposure to opposing views"
- E-I Index: A metric for the balance of external (inter-group) versus internal (intra-group) interactions; calculated as (external minus internal) divided by their sum. "We do so using an E-I Index: the number of inter-partisan interactions minus intra-partisan interactions divided by their sum."
- Emergent properties: System-level patterns arising from many individual interactions, not predictable from individual characteristics alone. "Social media platforms are complex systems with emergent properties that result from the interaction of large groups of people."
- Filter bubbles: Personalized content curation that isolates users from diverse viewpoints. "Many argue that Facebook, Twitter, and other platforms trap people within “echo chambers” or “filter bubbles” that prevent exposure to opposing views"
- Generative artificial intelligence: AI systems that produce human-like content (e.g., text) by learning from large corpora. "LLMs are a new form of generative artificial intelligence, trained on large amounts of human language to realistically simulate human conversations."
- Inter-partisan interaction: Likes or comments exchanged across political party lines. "We furthermore estimate the amount of inter-partisan interaction — that is, the extent to which agents comment and like messages from those who do not share their political views — using the observed interaction patterns among agents."
- Intra-partisan interactions: Engagement occurring within the same political party. "We do so using an E-I Index: the number of inter-partisan interactions minus intra-partisan interactions divided by their sum."
- LLMs: Deep neural networks trained to predict next tokens, enabling realistic language generation and conversation. "LLMs are a novel form of generative artificial intelligence, built on deep neural networks and trained to predict the next word in a sequence given a set of preceding words."
- Model assisted design: Using computational models to explore mechanisms and possible outcomes to guide experimental research. "In this way, ABMs can be understood as enabling a kind of “model assisted design,” where researchers identify a range of possible outcomes that can inform more deductive experimental research."
- Perspective API: An automated text analysis tool that estimates the toxicity of language. "In the interim, we use Perspective API, a popular automated text analysis tool to estimate the toxicity of discourse within the three simulated social media environments described above."
- Persona: A synthetic profile incorporating demographics, beliefs, interests, and behaviors that guides an agent’s actions. "these data enable us to create “personas” that inform the behavior of each agent in our model."
- Social learning: The process by which individuals adjust behavior by observing others’ actions and feedback in social contexts. "Further studies may seek to extend this to longer time periods, to simulate changing perceptions, attitudinal shifts, “social learning,” or evolving relationships among the agents themselves."
- Toxicity: The degree of rude, disrespectful, or unreasonable language in discourse. "encouraging cross-partisan interaction among social media users may produce more toxic discourse, which we define here as conversations that are rude, disrespectful, or unreasonable."
- Urn model: A probabilistic sampling scheme used to select agents based on predefined propensities. "In the first step, a sample of agents is selected to produce posts, based upon their self-reported frequency of social media use according to the ANES data using an Urn model"
Collections
Sign up for free to add this paper to one or more collections.