Published 9 Oct 2023 in cs.CL and cs.LG | (2310.05914v2)
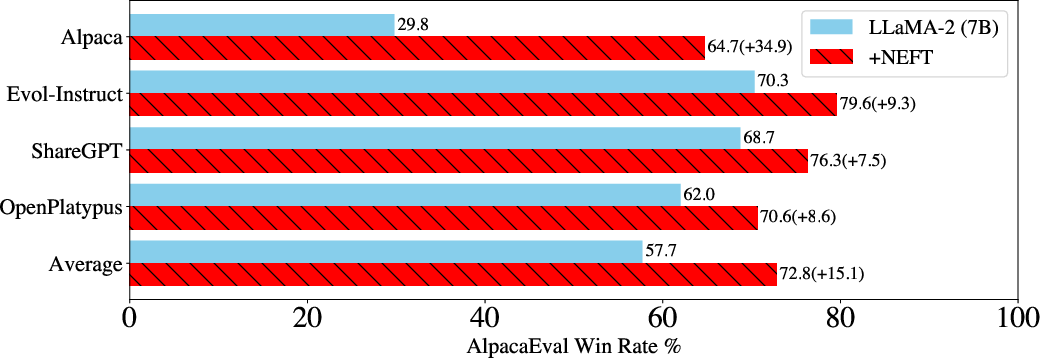
Abstract: We show that LLM finetuning can be improved, sometimes dramatically, with a simple augmentation. NEFTune adds noise to the embedding vectors during training. Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
The paper "NEFTune: Noisy Embeddings Improve Instruction Finetuning" (2310.05914) introduces NEFTune, a novel augmentation strategy for finetuning LLMs by adding noise to the embedding vectors during training. NEFTune aims to enhance the performance of LLMs on instruction datasets without additional computational or data overhead. This simple technique results in substantial improvements, especially in conversational tasks, allowing models to achieve better performance while maintaining their capabilities across factual question answering.
Figure 1: AlpacaEval Win Rate percentage for LLaMA-2-7B models finetuned on various datasets with and without NEFTune. NEFTune leads to massive performance boosts across all of these datasets, showcasing the increased conversational quality of the generated answers.
Methodology
NEFTune Algorithm
NEFTune training involves injecting noise into the embeddings of tokenized instructions. Each training instance is augmented by applying random noise sampled uniformly, scaled by a factor of α/Ld where L is sequence length, d is embedding dimension, and α is a tunable parameter. This process aims to prevent models from overfitting to the training data specifics, enabling better generalization to test distributions.
Experimental Set-up
The experiments focus on 7B parameter LLMs, specifically LLaMA-1, LLaMA-2, and OPT-6.7B. NEFTune performance was evaluated using Alpaca, Evol-Instruct, ShareGPT, and OpenPlatypus datasets. Evaluation metrics included AlpacaEval, focusing on conversational quality, and OpenLLM Leaderboard tasks for factual and reasoning capabilities.
Results
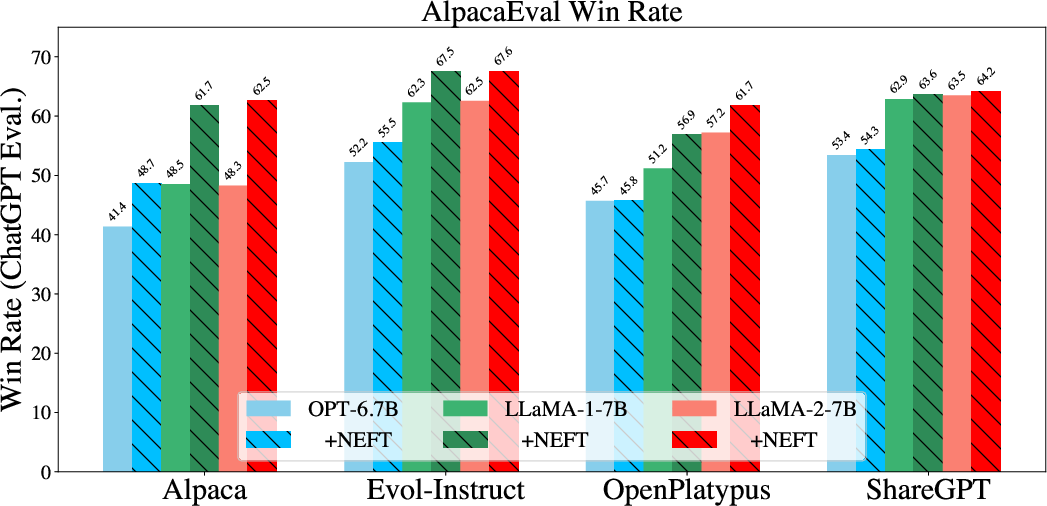
The application of NEFTune demonstrates a marked improvement in text quality, with average score increases of 15.1% in conversational models evaluated via AlpacaEval. In comparison tests, NEFTune models showed superior performance on LLaMA-2 and older models like LLaMA-1 and OPT across multiple datasets.
Figure 2: AlpacaEval Win Rate with and without NEFTune on LLaMA-2, LLaMA-1, and OPT across Alpaca, Evol-Instruct, ShareGPT, and OpenPlatypus datasets. Performance improves across different datasets and models with ChatGPT as the evaluator.
Furthermore, NEFTune was effective in enhancing refined models such as LLaMA-2-Chat. Despite extensive prior tuning using RLHF, NEFTune enabled further improvement of +10% in conversational ability, showcasing its versatility in training already mature models.
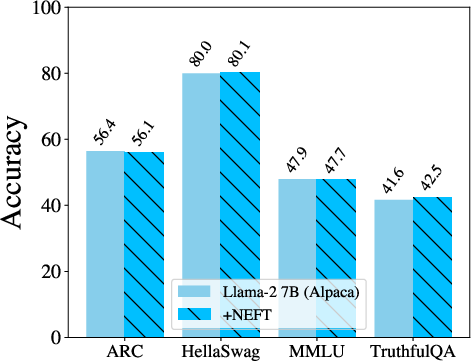
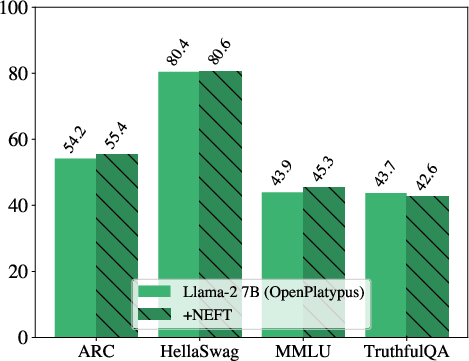
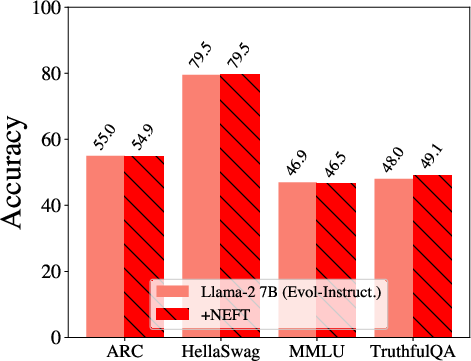
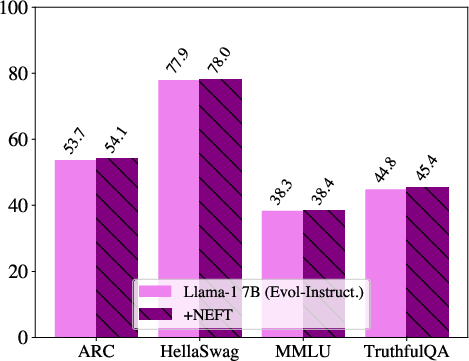
Figure 3: OpenLLM Leaderboard tasks with and without NEFTune on LLaMA-2 across Alpaca, Evol-Instruct, and OpenPlatypus datasets and LLaMA-1 trained on Evol-Instruct. We observe that performance does not change across datasets and models.
Analysis
Overfitting Reduction
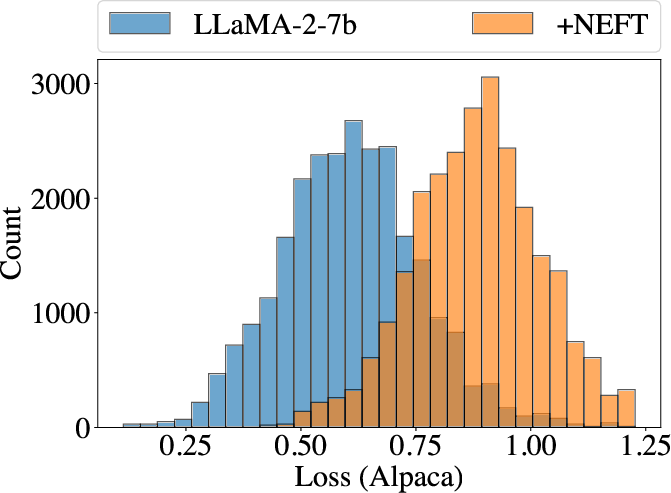
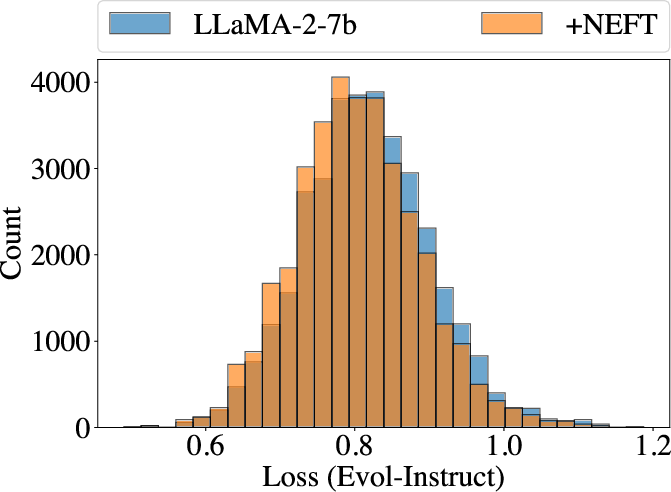
NEFTune reduces overfitting by enabling models to remain adaptive to diverse input formats from pretrained distributions. Training models with NEFTune yields higher training loss but lower test loss, indicating less overfitting without compromising generalization.
Figure 4: Left: training loss on the Alpaca dataset for models with and without NEFT, computed with no added noise. Training with NEFT yields a higher training loss. Right: loss of the same model, but evaluated on the ``test'' Evol-Instruct dataset. NEFT yields slightly lower loss.
Length vs. Diversity
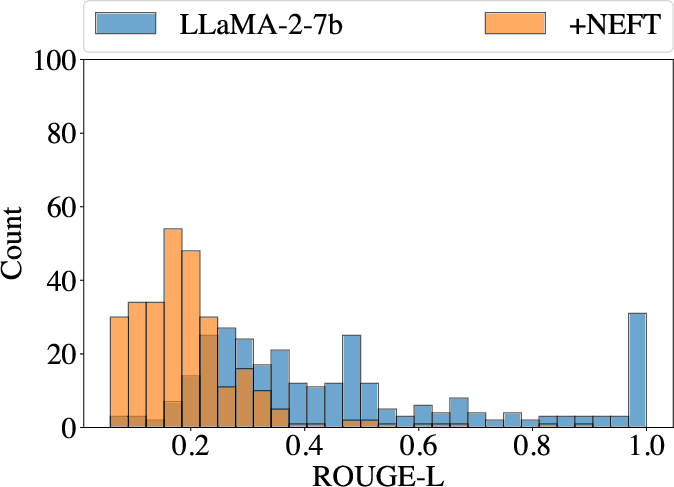
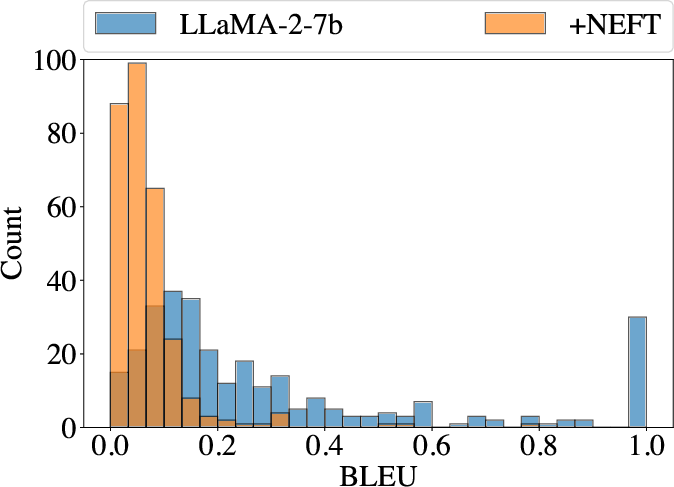
NEFTune models produce longer outputs, which correlates with improved benchmark scores; however, increased verbosity does not come at the cost of diversity or repetition rates, as evidenced by token repetition analysis.
Figure 5: Left shows the ROUGE-L of training with and without NEFT. Right shows BLEU score.
Conclusion
NEFTune offers a compelling alternative to traditional finetuning methods by enhancing model performance in instruction-following tasks without necessitating additional computational resources. By mitigating overfitting, NEFTune leads to better generalization and improved response quality, making it an essential consideration in LLM regularization strategies. While current findings highlight the benefits of NEFTune, further exploration into its application across larger models and alternative datasets could unveil additional insights and advancements.