- The paper introduces FAVOR, a fine-grained framework that integrates audio and visual data at the frame level, advancing causal reasoning in LLMs.
- It employs a causal Q-Former and temporal synchronization to align audio and video frames, achieving a 20% accuracy boost in video QA tasks.
- Ablation studies show that key components, including the causal encoder and diversity loss function, significantly enhance multimodal integration and reduce redundancy.
Fine-grained Audio-Visual Joint Representations for Multimodal LLMs
Introduction
The paper introduces a novel methodology for enhancing multimodal LLMs through a fine-grained audio-visual joint representation learning framework called FAVOR. This new framework was designed to perceive and seamlessly integrate audio and visual data at a frame level, thereby increasing the model's ability to handle multimodal inputs such as speech, audio events, and video simultaneously. The paper identifies existing limitations in multimodal LLM research, particularly regarding the under-explored fine-grained integration of varied input streams, and proposes FAVOR as a solution.
Methodology
FAVOR utilizes a precise structure with several key components aimed at integrating differing multimedia inputs at high temporal resolutions.
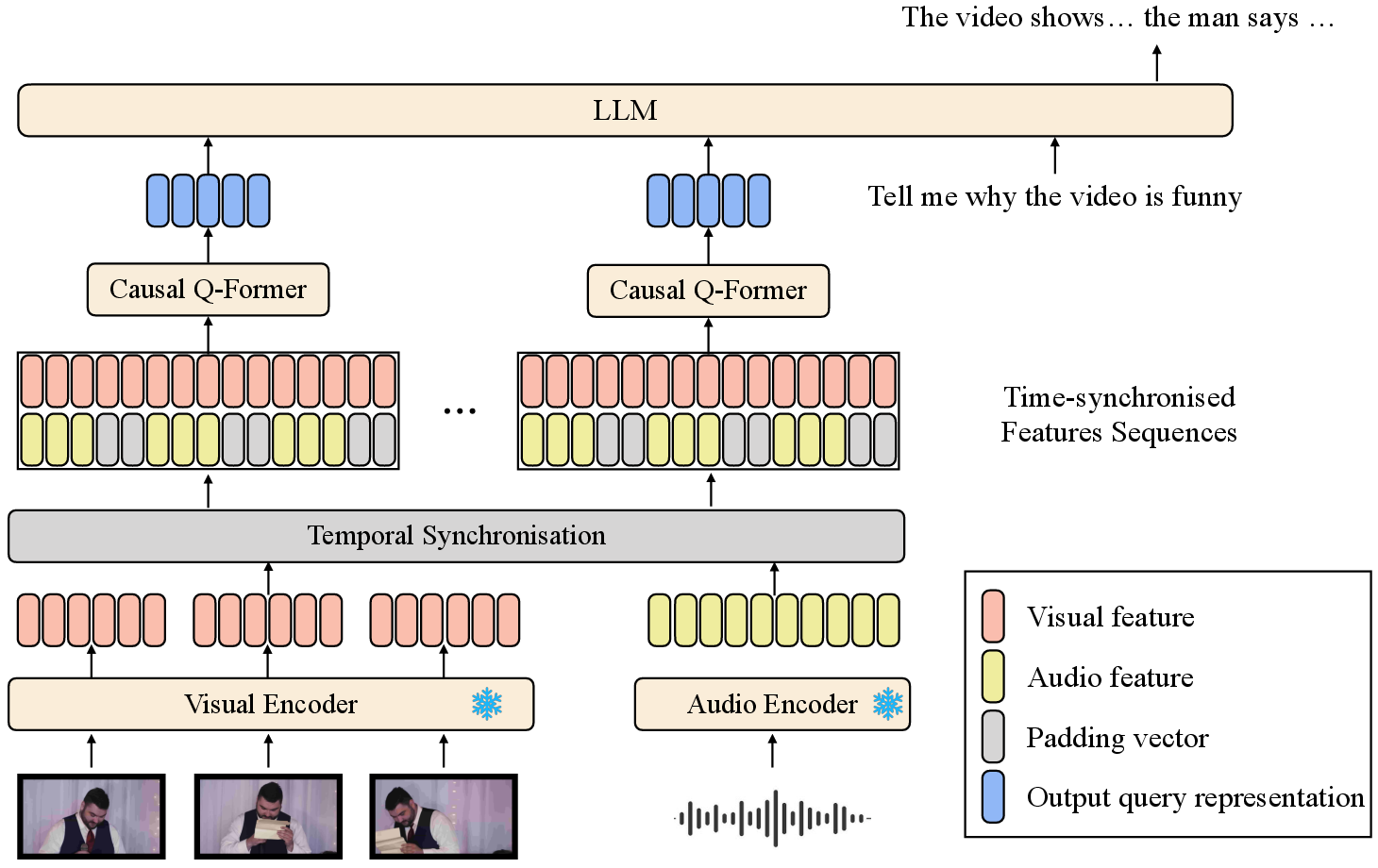
Figure 1: The fine-grained audio-visual joint representation (FAVOR) learning framework for multimodal LLMs. The temporal synchronisation module does not contain trainable parameters.
Model Architecture
The architecture comprises several modulatory systems, including the Q-Former structure, a causal attention module, and a temporal synchronization approach. When encountering both visual and audio inputs, the system temporally synchronizes these streams to facilitate fine-grained interactions crucial for comprehensive understanding, particularly in videos with speech. Synchronization is conducted by aligning audio frames with video frames using a synchronization module.
Fundamental to FAVOR’s success is the adoption of a causal Q-Former with a dedicated causal attention module to efficiently handle and encode sequential video frames. This module is designed to capture the temporal causal relationships between video and audio frames effectively.
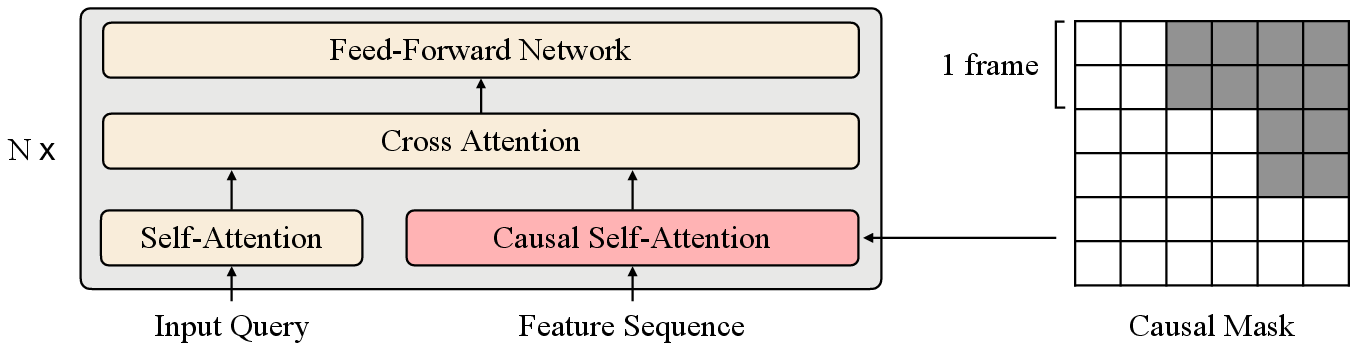
Figure 2: The causal attention module in the causal Q-Former with a block-wise triangular causal mask (grey cells are masked). The number of features per frame here is 2 as an example.
Evaluation
FAVOR's performance was assessed using the newly introduced AVEB benchmark, which includes both single-modal tasks like ASR and image captioning, and cross-modal tasks such as audio-visual scene-aware dialogue. FAVOR demonstrates a notable 20\% increase in accuracy for complex video QA tasks demanding fine-grained temporal causal reasoning.
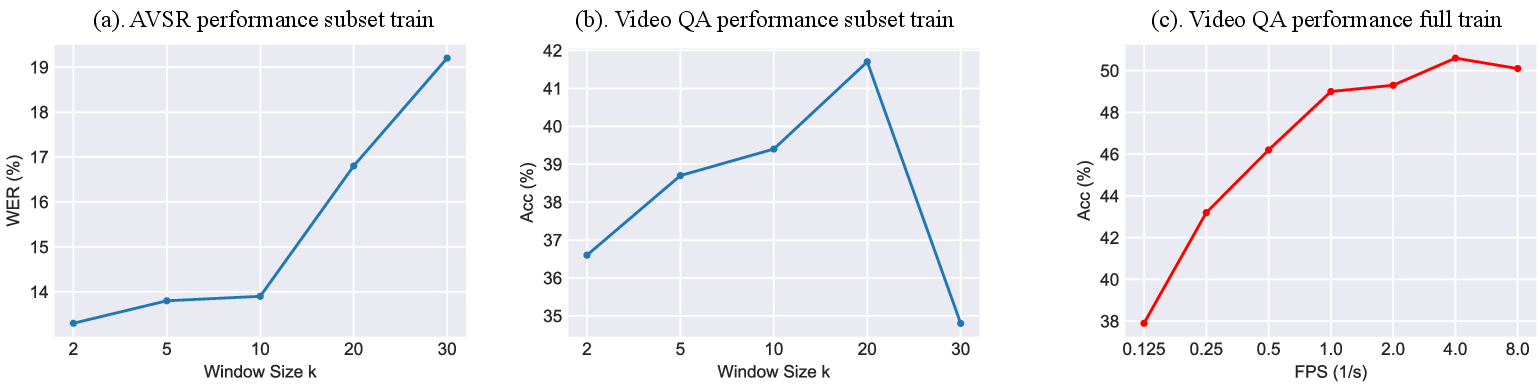
Figure 3: Influence of the window sizes and the frames per second (FPS) to the model performance on speech and video tasks.
Ablation Studies
The ablation studies conducted reveal the impact of each component in the FAVOR framework. Notably, the causal encoder and the temporal synchronization module were crucial for achieving higher performance in tasks involving causal reasoning and multimodal integration, particularly in audio-visual matching and video QA tasks.
Analysis
The diversity loss function plays a critical role in encouraging a wider spread of output query representation vectors, enhancing the model’s ability to capture diversified data sequences. This loss function was shown to influence model performance across several tasks, including AVEB auditory tasks, where it decreases query redundancy.
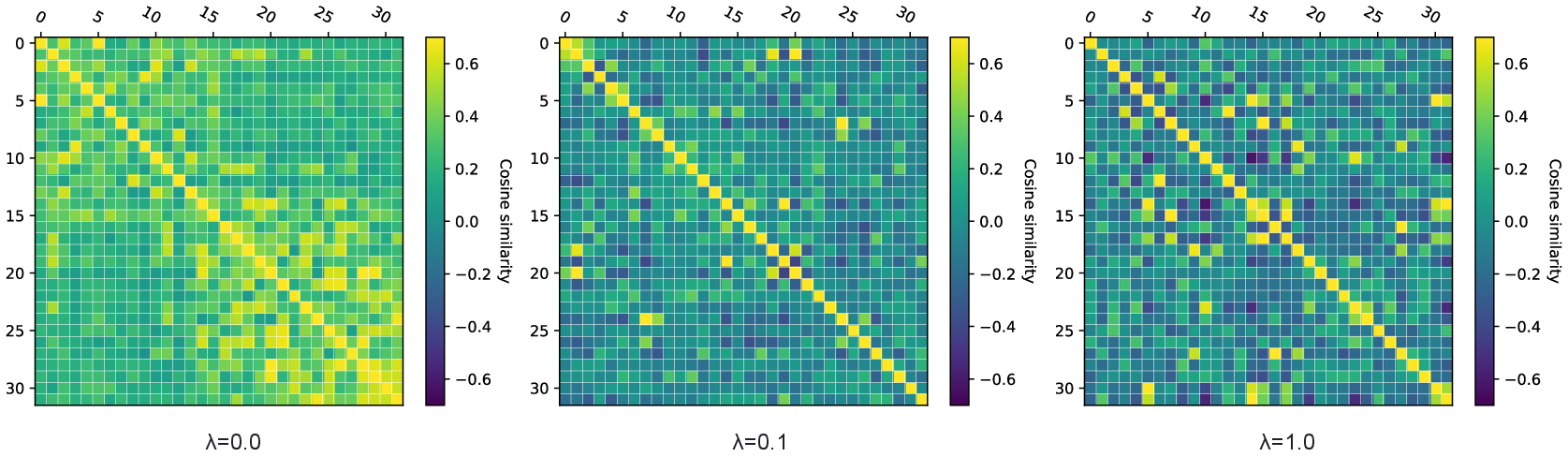
Figure 4: Visualisation of cosine similarity matrix with different diversity loss factors.
Implications and Future Work
FAVOR’s advancements have significant implications for audio-visual LLM research, particularly as it paves the way for better temporal synchronization and integration of complex, sequential multimedia inputs. Further improvements could focus on reducing computational overhead while maintaining high synchronization fidelity, and the extension of FAVOR to additional languages and domains. Cross-modal emergent abilities are clearly reflected in the presented examples providing a practical application baseline for future studies.
Conclusion
The introduction of FAVOR offers a marked improvement in the integration and understanding of fine-grained audio-visual data, facilitating sophisticated reasoning and comprehension capabilities within LLMs. As audio-visual data becomes increasingly central to LLM applications, FAVOR’s ability to enhance the comprehension of video input streams through frame-level integration presents a significant advancement. The FAVOR framework sets a new benchmark for multimodal analysis, encouraging future exploration into more efficient and comprehensive multimodal learning paradigms.