LLM-Coordination: Evaluating and Analyzing Multi-agent Coordination Abilities in Large Language Models
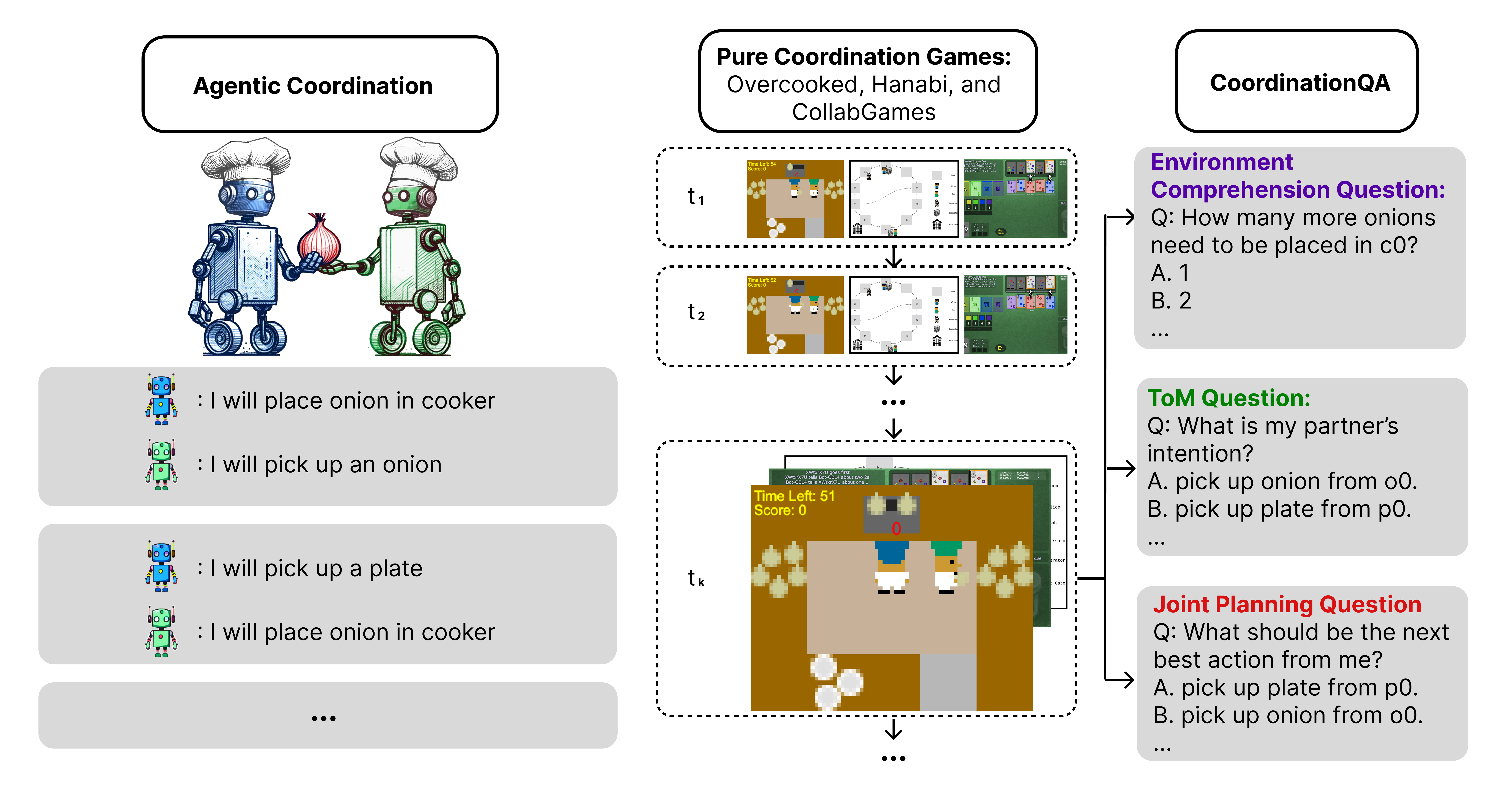
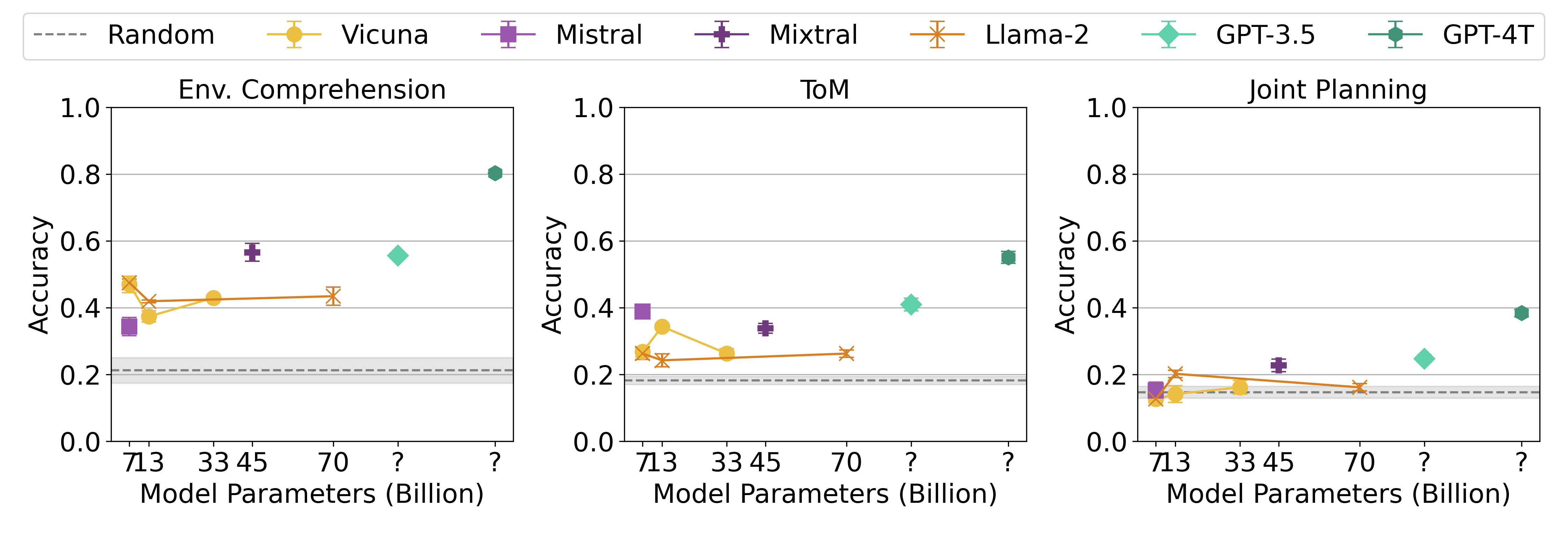
Abstract: LLMs have demonstrated emergent common-sense reasoning and Theory of Mind (ToM) capabilities, making them promising candidates for developing coordination agents. This study introduces the LLM-Coordination Benchmark, a novel benchmark for analyzing LLMs in the context of Pure Coordination Settings, where agents must cooperate to maximize gains. Our benchmark evaluates LLMs through two distinct tasks. The first is Agentic Coordination, where LLMs act as proactive participants in four pure coordination games. The second is Coordination Question Answering (CoordQA), which tests LLMs on 198 multiple-choice questions across these games to evaluate three key abilities: Environment Comprehension, ToM Reasoning, and Joint Planning. Results from Agentic Coordination experiments reveal that LLM-Agents excel in multi-agent coordination settings where decision-making primarily relies on environmental variables but face challenges in scenarios requiring active consideration of partners' beliefs and intentions. The CoordQA experiments further highlight significant room for improvement in LLMs' Theory of Mind reasoning and joint planning capabilities. Zero-Shot Coordination (ZSC) experiments in the Agentic Coordination setting demonstrate that LLM agents, unlike RL methods, exhibit robustness to unseen partners. These findings indicate the potential of LLMs as Agents in pure coordination setups and underscore areas for improvement. Code Available at https://github.com/eric-ai-lab/llm_coordination.
- The hanabi challenge: A new frontier for ai research. Artificial Intelligence, 280:103216, 2020. ISSN 0004-3702. doi: https://doi.org/10.1016/j.artint.2019.103216. URL https://www.sciencedirect.com/science/article/pii/S0004370219300116.
- On the Utility of Learning about Humans for Human-AI Coordination. Curran Associates Inc., Red Hook, NY, USA, 2019a.
- overcooked_ai. https://github.com/HumanCompatibleAI/overcooked_ai/tree/master, 2019b.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Threedworld: A platform for interactive multi-modal physical simulation, 2021.
- Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. arXiv preprint arXiv:2201.07207, 2022.
- Population based training of neural networks, 2017.
- Two body problem: Collaborative visual task completion. In CVPR, 2019. first two authors contributed equally.
- A cordial sync: Going beyond marginal policies for multi-agent embodied tasks. In ECCV, 2020. first two authors contributed equally.
- Michal Kosinski. Theory of mind might have spontaneously emerged in large language models, 2023.
- Cooperative open-ended learning framework for zero-shot coordination. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pp. 20470–20484. PMLR, 2023. URL https://proceedings.mlr.press/v202/li23au.html.
- Code as policies: Language model programs for embodied control. In arXiv preprint arXiv:2209.07753, 2022.
- Pecan: Leveraging policy ensemble for context-aware zero-shot human-ai coordination. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, AAMAS ’23, pp. 679–688, Richland, SC, 2023. International Foundation for Autonomous Agents and Multiagent Systems. ISBN 9781450394321.
- Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pp. 6382–6393, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964.
- Roco: Dialectic multi-robot collaboration with large language models, 2023.
- OpenAI. Gpt-4 technical report, 2023.
- Training language models to follow instructions with human feedback, 2022.
- Generative agents: Interactive simulacra of human behavior, 2023.
- Watch-and-help: A challenge for social perception and human-{ai} collaboration. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=w_7JMpGZRh0.
- Planning with large language models via corrective re-prompting, 2022.
- Proximal policy optimization algorithms, 2017.
- Llm-planner: Few-shot grounded planning for embodied agents with large language models. arXiv preprint arXiv:2212.04088, 2022.
- Collaborating with humans without human data. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems, volume 34, pp. 14502–14515. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/paper/2021/file/797134c3e42371bb4979a462eb2f042a-Paper.pdf.
- Voyager: An open-ended embodied agent with large language models, 2023.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Too many cooks: Bayesian inference for coordinating multi-agent collaboration. Topics in Cognitive Science, 13(2):414–432, 2021. doi: https://doi.org/10.1111/tops.12525. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/tops.12525.
- Spring: Gpt-4 out-performs rl algorithms by studying papers and reasoning, 2023.
- Learning zero-shot cooperation with humans, assuming humans are biased. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=TrwE8l9aJzs.
- Building cooperative embodied agents modularly with large language models, 2023.
- Maximum entropy population-based training for zero-shot human-ai coordination. Proceedings of the AAAI Conference on Artificial Intelligence, 37(5):6145–6153, Jun. 2023. doi: 10.1609/aaai.v37i5.25758. URL https://ojs.aaai.org/index.php/AAAI/article/view/25758.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.