Improved Baselines with Visual Instruction Tuning
Abstract: Large multimodal models (LMM) have recently shown encouraging progress with visual instruction tuning. In this note, we show that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient. With simple modifications to LLaVA, namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, we establish stronger baselines that achieve state-of-the-art across 11 benchmarks. Our final 13B checkpoint uses merely 1.2M publicly available data, and finishes full training in ~1 day on a single 8-A100 node. We hope this can make state-of-the-art LMM research more accessible. Code and model will be publicly available.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI systems to understand pictures and text together, so they can act like helpful assistants that “see” and “talk.” The authors show that you don’t need a super-complicated design or huge secret datasets to get great results. With a few simple tweaks to an existing system called LLaVA, they build an improved model (LLaVA-1.5) that performs at the top on many tests, trains quickly, and uses only public data.
What questions did the researchers ask?
They focused on clear, practical questions:
- Can a very simple way of connecting vision and language (a tiny neural layer) be strong and data-efficient?
- Can we get better answers by telling the model exactly how to format its reply (for example, “answer in one word” or “pick A/B/C/D”)?
- How much data and compute do we really need to reach top performance?
- Does using higher-resolution images help the model notice small details and hallucinate less (hallucination = making things up that aren’t in the image)?
- Can the model combine skills it learned separately (like reading text in images and following instructions) to handle more complex tasks?
How did they study it?
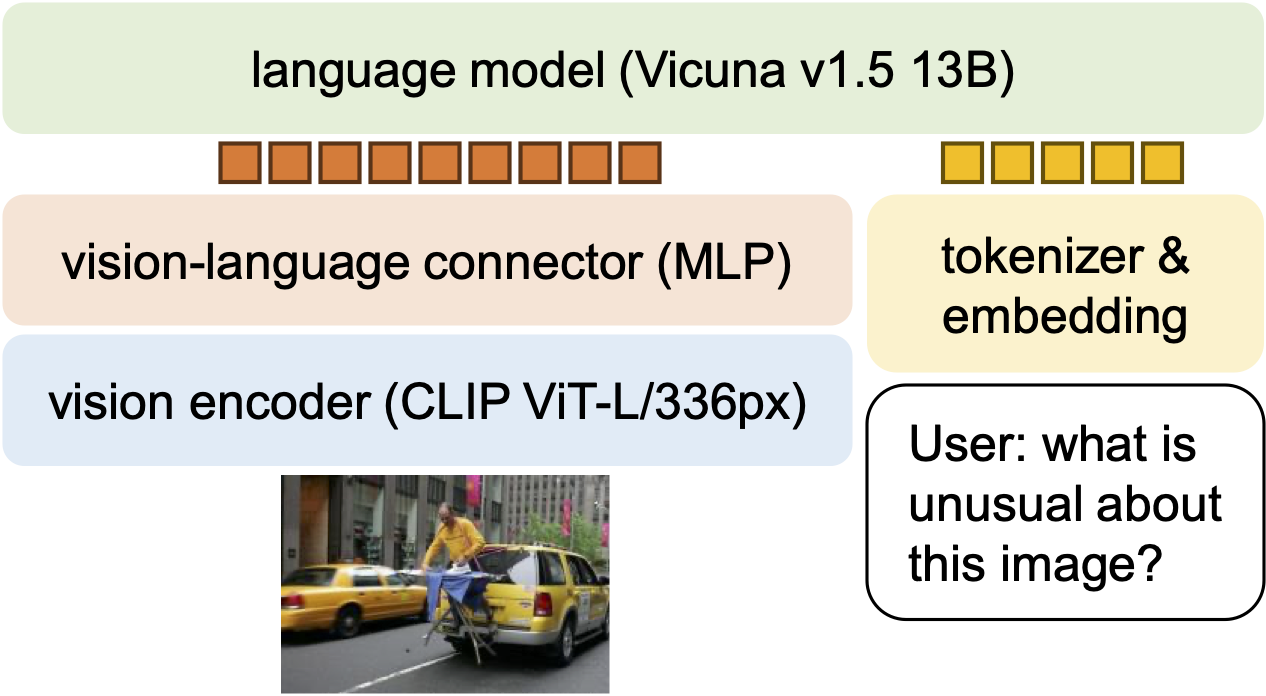
They started with LLaVA, a simple system that combines:
- A vision encoder (like CLIP) that turns an image into numbers a computer can understand.
- A LLM (Vicuna, based on LLaMA) that reads instructions and writes answers.
- A small “connector” that bridges vision features to the LLM.
Then they made small but powerful changes:
- A stronger connector: They replaced a single linear layer with a tiny two-layer MLP (a simple kind of neural network). Think of it as upgrading from a thin wire to a slightly thicker cable for better signal.
- Clear answer-format instructions: They added short phrases to training prompts like “Answer with a single word” or “Choose the letter of the correct option.” This teaches the model when to be brief and when to write more.
- Focused training data: They added academic-style vision datasets (like VQA for short answers, OCR for reading text in images, and region-level tasks to focus on specific parts of images). All data was publicly available.
- Reasonable scaling: They used CLIP with 336×336 images and also tried a 13B-parameter LLM (a bigger brain) in addition to a 7B one.
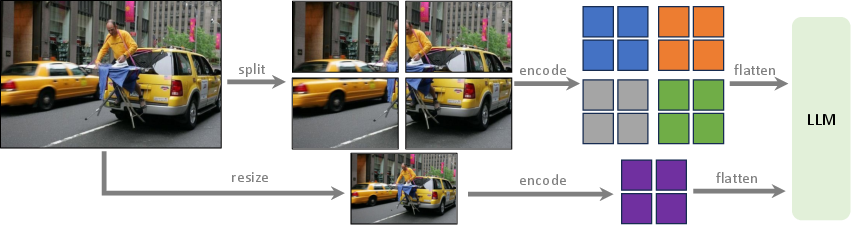
- High-resolution trick (HD): To see more detail without retraining the vision encoder from scratch, they split a large image into tiles (like a photo mosaic), ran the encoder on each tile, stitched the features back together, and added a small low-res overview for global context. This boosts detail understanding and reduces mistakes.
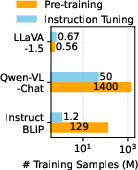
- Efficiency: They trained with about 1.2 million public examples and finished full training in about one day on a single machine with 8 A100 GPUs.
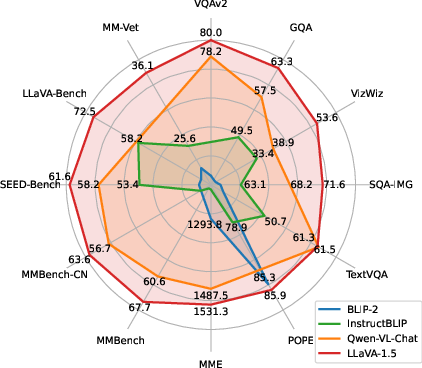
They tested on many public benchmarks (like VQAv2, GQA, TextVQA, MM-Vet, MMBench, POPE, and more) that check short answers, detailed conversations, reading text in images, and avoiding hallucinations.
What did they find?
Big picture: Simple changes worked surprisingly well.
- The simple MLP connector is enough (and great): You don’t need fancy vision “resampler” modules. A tiny MLP worked very well and was data-efficient.
- Format prompts fix answer length problems: Telling the model exactly how to answer (one word vs. detailed explanation) helped it balance short academic answers and conversational replies. It also reduced overfitting to super-short answers.
- Less data, strong results: Using only around 1.2M public training examples, the improved model reached state-of-the-art on 11+ benchmarks. Training took about a day on standard research hardware.
- Higher resolution helps details and honesty: The tiling method (HD) made the model better at fine details (like reading small text) and reduced hallucinations, because it could actually “see” more.
- Bigger LLM helps conversations: Moving from a 7B to a 13B LLM improved performance on open-ended, real-world visual chats.
- Compositional skills emerge: Training on separate skills (e.g., short-answer VQA + long-form language tasks) helped the model write better, more grounded long answers to visual questions.
- Very data-efficient: Randomly using only 50% of their training mix kept about 98% of full performance. That suggests we might compress training data even more without losing much quality.
- Some multilingual generalization: Even though visual training was in English, the model picked up some ability to follow non-English instructions (likely thanks to multilingual text-only data from ShareGPT).
Why are these results important?
- Simple, open, and reproducible: The model uses a clear design, only public data, and modest compute. That makes cutting-edge research more accessible to more people and labs.
- Strong real-world capability: It handles both short academic answers and natural conversations about images—important for assistants that can “see.”
- Guidance for the field: The work challenges the idea that you must pretrain complex vision-language modules on billions of pairs. It shows that careful instruction tuning, simple connectors, and higher-resolution inputs can go a long way.
- Fewer hallucinations with better vision: Improving how clearly the model “sees” reduces made-up details—key for trustworthiness.
Final takeaway
This paper shows that you can build a top-tier vision-and-language assistant with:
- A simple architecture (vision encoder + tiny MLP connector + LLM),
- Clear instructions about answer format,
- Carefully chosen, public datasets,
- A practical high-resolution trick (tiling + global view),
- And modest compute.
This makes high-quality multimodal AI more practical and opens the door to faster, fairer progress—while also pointing to future work on even better data choices, further reducing hallucinations, and improving skills like multi-image reasoning.
Collections
Sign up for free to add this paper to one or more collections.

