Selenite: Scaffolding Online Sensemaking with Comprehensive Overviews Elicited from Large Language Models
Abstract: Sensemaking in unfamiliar domains can be challenging, demanding considerable user effort to compare different options with respect to various criteria. Prior research and our formative study found that people would benefit from reading an overview of an information space upfront, including the criteria others previously found useful. However, existing sensemaking tools struggle with the "cold-start" problem -- it not only requires significant input from previous users to generate and share these overviews, but such overviews may also turn out to be biased and incomplete. In this work, we introduce a novel system, Selenite, which leverages LLMs as reasoning machines and knowledge retrievers to automatically produce a comprehensive overview of options and criteria to jumpstart users' sensemaking processes. Subsequently, Selenite also adapts as people use it, helping users find, read, and navigate unfamiliar information in a systematic yet personalized manner. Through three studies, we found that Selenite produced accurate and high-quality overviews reliably, significantly accelerated users' information processing, and effectively improved their overall comprehension and sensemaking experience.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What’s this paper about?
This paper introduces Selenite, a helpful tool you add to your web browser. Its goal is to make it easier to understand new, complicated topics online—like choosing the best baby stroller or comparing different coding tools—by giving you a clear, organized “big-picture” overview right away. It uses a very smart AI (a LLM, or LLM, like GPT-4) to suggest what’s most important to look for and then guides you as you read so you don’t get lost or waste time.
The key questions the researchers asked
The paper asks three simple questions:
- Can an AI quickly give people a useful “map” of a topic—what options exist and which qualities (criteria) matter most—so they start off with good guidance?
- Can this map help people read smarter, by pointing out what’s in each page and paragraph so they can jump to the parts they care about?
- Does this actually help people understand faster and make better decisions?
How did they do the research? (Methods and approach)
Think of learning a new topic like exploring a new city:
- A “big-picture map” helps you see the main neighborhoods and landmarks (the important criteria).
- Street signs and summaries help you navigate each block (paragraph) without wandering aimlessly.
- Suggestions for where to go next help you discover new places you haven’t visited yet.
Selenite gives you all three:
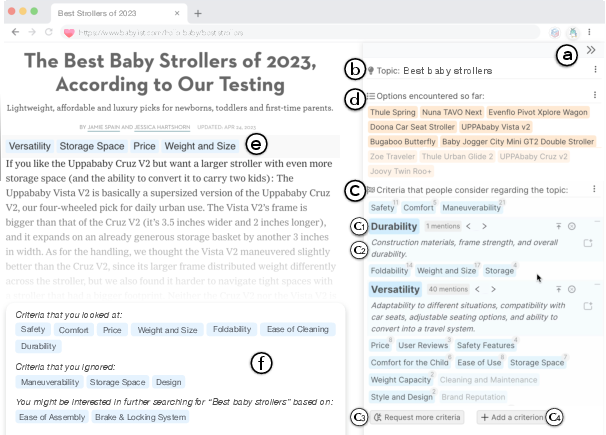
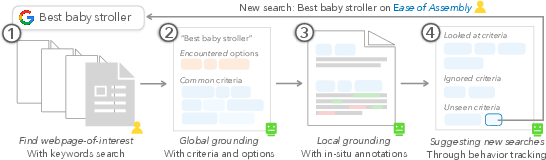
- It creates a global overview: When you open a page about a topic (say, “best baby strollers”), Selenite’s sidebar shows common criteria people care about (like safety, maneuverability, durability) and the options mentioned on the page.
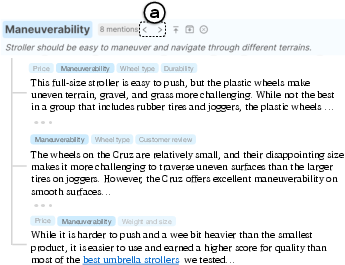
- It helps at the page and paragraph level: It highlights which criteria each paragraph talks about and lets you jump between all the paragraphs that discuss the same thing (like maneuverability) across the page.
- It guides your next steps: At the end of a page, it summarizes what you’ve covered and suggests smart search ideas to find new information you haven’t seen yet.
To build this, the researchers used:
- LLMs, such as GPT-4, which are computer programs trained on lots of text and can generate helpful summaries and lists. They asked GPT-4 to:
- Recognize the topic of a page.
- List commonly important criteria for that topic (like a checklist).
- Help explain tricky paragraphs (what’s positive, negative, or neutral about each criterion).
- A classification model (think “smart tagger”) that can read a paragraph and decide which criteria it discusses, so Selenite can label paragraphs and help you navigate.
- A Chrome extension interface so everything appears alongside the page you’re reading.
They ran three types of studies:
- A formative study (interviews) to learn what people struggle with when reading unfamiliar topics online.
- An intrinsic evaluation to check if the AI-generated overviews were accurate and high-quality.
- Usability and case studies to see if Selenite actually helped people read faster and understand better.
They also used techniques to make the AI’s results more reliable, like “Self-Refine,” which asks the AI to improve its own answers, and grounding the AI’s summaries in the actual page content you’re reading, so it’s easier to verify.
What did they find and why it matters
The main results were positive:
- Selenite’s overviews were accurate and high-quality: The criteria lists and summaries were reliable enough to be useful right away.
- It sped up reading and decision-making: People got to the important parts faster because they knew what to look for and where to find it.
- It improved comprehension: By labeling paragraphs and providing quick summaries, readers better understood complicated sections and didn’t miss important details.
- It made the whole experience less overwhelming: Starting with a clear overview and having smart navigation kept people focused and reduced confusion.
Why this matters: When you don’t know much about a topic, it’s easy to miss key ideas or get stuck reading repetitive, unhelpful content. Selenite acts like a friendly guide—it shows you the big picture, points out the valuable parts, and helps you move on to find new information. That can lead to better choices, whether you’re buying something, learning a skill, or researching for school.
What does this mean for the future? (Implications)
This research suggests that future reading and research tools should do more than store notes—they should help you understand from the start. Tools like Selenite could:
- Help students and professionals quickly build a strong mental model of a new topic.
- Reduce wasted time on duplicate or low-value pages by previewing what matters.
- Support better decision-making with clear criteria and side-by-side comparisons.
- Be integrated into browsers or search engines to make exploring new topics easier for everyone.
There’s still room to improve—AI can make mistakes (called “hallucinations,” where it says something that isn’t true), so it’s important that tools keep grounding their answers in real page content and make verification easy. But overall, Selenite shows that AI can be a powerful reading companion: it gives you a map, guides your steps, and helps you discover more—all while keeping you in control.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored based on the paper’s current scope and evidence.
- External validity across domains: Assess how Selenite performs beyond consumer-style comparisons (e.g., scientific literature reviews, health/medical, legal, political, civic information) where stakes, ambiguity, and domain conventions differ.
- Non-English and cross-lingual robustness: Evaluate topic recognition, criteria retrieval, and paragraph classification for non-English content and mixed-language pages; replace/extend English-centric models (e.g., BART-large-MNLI) with multilingual alternatives.
- Recency and world-knowledge limits: Quantify how GPT-4’s knowledge cutoff affects criteria completeness for rapidly evolving domains; compare against retrieval-augmented generation (RAG) or web-grounded evidence for up-to-date criteria.
- Hallucinations and factuality: Systematically measure hallucination/falsehood in criteria lists and paragraph-level explanations; test mitigation strategies (Self-Refine, citations, RAG) and quantify their impact.
- Bias and fairness in criteria: Identify demographic, cultural, and topical biases in LLM-elicited “commonly considered” criteria; study how criteria differ across cultures and contexts, and design methods to surface multiple, pluralistic framings.
- Anchoring and confirmation effects: Test whether top-down criteria prime/anchor users, narrow exploration, or reinforce confirmation bias; design and evaluate countermeasures (e.g., alternative framings, randomized exposure, “explore outside the list” prompts).
- Provenance and auditability: Add explicit citations and source links for each generated criterion and paragraph-level claim; study how provenance affects trust, verification behavior, and error correction.
- Transparency and uncertainty communication: Expose calibrated confidence or uncertainty for topic labels, criteria presence, and sentiment; evaluate how such signals influence user decisions and error handling.
- Topic recognition accuracy and scope: Rigorously benchmark GPT-4–based topic inference and SentenceBERT clustering across diverse, ambiguous, or multi-topic pages; define thresholds, handling of multi-label topics, and user override workflows.
- Options extraction robustness: Evaluate extraction across heterogeneous web structures (boilerplate-heavy pages, dynamic content, tables, lists, carousels, comments, ads); compare against DOM-aware and boilerplate-removal baselines.
- Paragraph-level classification validity: Provide ablations and benchmarks for the 0.96 NLI threshold, precision–recall tradeoffs, latency, and cost; compare zero-shot vs. fine-tuned, domain-adapted models.
- Adversarial robustness and prompt injection: Analyze how untrusted web content can manipulate LLM prompts/outputs; implement and evaluate sanitization and isolation strategies for safe prompting.
- Privacy and data handling: Specify and evaluate policies for sending page content to remote APIs (PII handling, data retention, on-device alternatives), and assess user perceptions of privacy.
- Latency, scalability, and cost: Measure end-to-end performance and cost at scale (many tabs/pages), caching strategies, batching, offline modes, and feasibility on lower-resource devices.
- Accessibility: Assess color schemes (red/green sentiment), keyboard navigation, screen-reader compatibility, and cognitive load; provide accessible alternatives to color-coded annotations.
- UI overload and attentional impact: Quantify cognitive load from sidebars, annotations, and “zoom-in” views; study attention fragmentation and optimal granularity/levels-of-detail controls.
- Personalization and adaptive learning: Explore models that learn user-specific criteria importance, vocabulary/jargon preferences, and reading goals over time without reinforcing pre-existing biases.
- Longitudinal and field evaluations: Move beyond short lab/usability studies to longitudinal, in-the-wild deployments measuring learning, knowledge retention, decision quality, satisfaction, and sustained adoption.
- Collaboration and social transparency: Extend to multi-user sensemaking (shared criteria sets, provenance/versioning, conflict resolution) and study how group dynamics affect bias, coverage, and trust.
- Novelty and de-duplication in search suggestions: Define algorithms and metrics for “novel information gain”; evaluate end-of-page query suggestions for diversity, redundancy reduction, and avoidance of filter bubbles.
- Handling multimodal and non-HTML sources: Extend to PDFs, videos, slides, code repositories, and datasets; evaluate extraction/annotation quality for multimodal content and structured data.
- Quantitative attribute extraction: Support accurate extraction/normalization of numeric data (units, ranges, uncertainty), and evaluate automatic table generation and consistency checking across sources.
- Failure handling and recoverability: Design interactions to flag, correct, and learn from system errors (misclassified criteria, missed options) and measure how quickly users detect and fix issues.
- Ethical impacts on critical reading: Examine whether overviews and annotations reduce independent critical reading, exploration breadth, or critical thinking; design nudges for balanced skepticism and verification.
- Cultural adaptation of criteria: Investigate how “commonly considered” criteria vary by region, culture, and norms; incorporate locale-aware templates and user-selectable cultural profiles.
- Evaluation benchmarks and gold standards: Create open, expert-annotated benchmarks for “criteria comprehensiveness” and paragraph-level mappings to support reproducible comparisons across methods.
- Integration and interoperability: Study export/import, APIs, and integration with note-taking, reference managers, and search engines; assess friction, data provenance, and workflow fit.
- Security and extension threat model: Define and test a browser-extension security model, required permissions, local storage policies, and defenses against malicious pages and XSS-style attacks.
- Vendor dependence and reproducibility: Address reliance on proprietary GPT-4; compare with open models, distillation/on-device variants, and report reproducible pipelines and hyperparameters.
- Metrics for “comprehensiveness” and “quality”: Operationalize and validate metrics for overview coverage, diversity, and usefulness; relate them to downstream decision outcomes and user satisfaction.
Practical Applications
Immediate Applications
These applications can be deployed today using Selenite’s approach (LLM-elicited criteria, automatic topic/option extraction, paragraph-level annotations, and end-of-page progress cues) with modest engineering and governance.
- Consumer decision support browser extension (Daily life, E-commerce)
- Use case: Shoppers researching complex purchases (e.g., strollers, mattresses, cameras) get an upfront criteria overview, page previews by aspect, and non-linear navigation across reviews.
- Tools/products/workflows: Chrome/Edge/Firefox extension; retailer plug-ins; comparison-site widgets that surface “commonly considered criteria” and “what this page adds.”
- Assumptions/dependencies: Acceptable LLM API costs/latency; consent to send page text to cloud services; human-in-the-loop verification to mitigate hallucinations; English-first coverage.
- Developer technology selection companion (Software/IT)
- Use case: Engineers comparing frameworks, libraries, cloud services leverage criteria like stability, community, integration effort; navigate docs/issues by criterion.
- Tools/products/workflows: IDE/browser add-on for docs sites and GitHub; integration with internal architectural decision records (ADRs); team-onboarding reading companion.
- Assumptions/dependencies: Corporate privacy controls; domain prompts tuned to software; retrieval augmentation for up-to-date releases.
- Literature review and paper-reading companion (Academia, R&D)
- Use case: Students and researchers get “criteria” for a topic (e.g., evaluation metrics, datasets, methods), paragraph annotations, and suggestions for “what to read next” that reduce redundancy.
- Tools/products/workflows: Plugins for PDF readers (e.g., Acrobat), reference managers (e.g., Zotero/Mendeley), and academic browsers; courseware integrations for reading assignments.
- Assumptions/dependencies: Accurate PDF parsing/OCR; discipline-specific prompts; clear disclaimers about LLM limitations.
- Editorial research and fact-check triage (Media/Journalism)
- Use case: Reporters preview pages by aspects (e.g., methodology, conflicts of interest, counterarguments) and jump among aspect mentions; end-of-page cues to find novel angles.
- Tools/products/workflows: Newsroom browser extension; CMS sidepanels that show covered vs. missing angles; de-duplication guidance for source gathering.
- Assumptions/dependencies: Mandatory source verification policies; model governance to avoid over-reliance on LLM “knowledge.”
- Policy analysis and stakeholder brief preparation (Policy/Government/NGOs)
- Use case: Analysts exploring proposals gain an instant criteria scaffold (e.g., cost, equity impact, enforceability), navigate long PDFs/webpages by aspect, and receive targeted next-query suggestions.
- Tools/products/workflows: Secure in-browser tool for government intranets; integration with document repositories and regulatory portals.
- Assumptions/dependencies: Compliance (GDPR, records retention), on-prem or vetted LLMs; careful framing to avoid normative bias in “criteria.”
- Customer support knowledge-base navigator (Customer success/Enterprise)
- Use case: Agents and users scan troubleshooting pages by aspect (e.g., prerequisites, steps, error conditions), jump between relevant sections, and identify missing coverage.
- Tools/products/workflows: Help center sidebar; CRM integration; agent co-pilot showing per-article aspect coverage.
- Assumptions/dependencies: Access to page text; multi-language support for global KBs; performance under high ticket volume.
- Product management competitive analysis (Industry/Product)
- Use case: PMs collect “options encountered” and compare by common criteria (price, integrations, SLAs), with paragraph-level evidence annotations.
- Tools/products/workflows: Browser extension + export to spreadsheets/Notion; workflow to turn reading trails into structured comparison docs.
- Assumptions/dependencies: Organizational acceptance of evidence capture; sensitivity to vendor content licensing.
- Internal onboarding and SOP discovery (Enterprise Knowledge Management)
- Use case: New hires get a big-picture map of internal docs by criteria (e.g., policy scope, approval steps), enabling faster ramp-up.
- Tools/products/workflows: Intranet sidebar; SharePoint/Confluence plugin; “what to read next” suggestions focused on gaps.
- Assumptions/dependencies: On-prem deployment or secure API gateways; role-based access controls.
- Education: reading scaffolds for non-linear comprehension (Education)
- Use case: Learners skim dense materials with aspect summaries (e.g., theorem assumptions, proofs, applications) and track which aspects they’ve mastered.
- Tools/products/workflows: LMS integration; adaptive reading guides; formative assessment linked to aspects.
- Assumptions/dependencies: Instructor oversight; alignment with curriculum; accommodations for accessibility.
- Research-ops and horizon scanning (Strategy/Corporate foresight)
- Use case: Analysts synthesize a domain quickly using criteria (market drivers, risks, regulatory landscape), avoid duplicate sources, and log coverage gaps.
- Tools/products/workflows: Sensemaking sidebar + export to brief templates; query-suggestion module for novelty-seeking.
- Assumptions/dependencies: Domain-specific prompt libraries; governance for confidential topics.
- E-commerce comparison pages and review UX (Retail/Marketplaces)
- Use case: Surfaces “commonly considered criteria” and per-product evidence highlights from reviews/Q&A.
- Tools/products/workflows: Merchant and marketplace widgets; per-product aspect coverage meters; “compare by aspect” navigation.
- Assumptions/dependencies: Review parsing quality; moderation to avoid misclassification; platform performance constraints.
Long-Term Applications
These applications require further research, domain adaptation, large-scale integration, or stronger guarantees (accuracy, privacy, compliance) before broad deployment.
- Search engine and browser-level “overview of criteria” (Software/Search)
- Use case: SERPs show domain criteria, per-result aspect coverage, and de-dup suggestions; users jump directly to the most novel sources.
- Tools/products/workflows: Native browser sidebars; search provider APIs; ranking models that incorporate “novelty by aspect.”
- Assumptions/dependencies: Large-scale indexing of aspect coverage; robust anti-hallucination pipelines; UX validation at web scale.
- Regulated-domain decision support (Healthcare, Legal, Finance)
- Use case: Clinicians/lawyers/analysts get aspect scaffolds (e.g., contraindications, precedent factors, risk metrics) tied to verified sources.
- Tools/products/workflows: RAG pipelines over trusted corpora; signed citations; audit trails; ISO/IEC-compliant AI governance.
- Assumptions/dependencies: Near-zero hallucinations; domain-tuned models; privacy/security (HIPAA, GDPR); liability frameworks; expert oversight.
- Organization-wide sensemaking fabric over private corpora (Enterprise)
- Use case: Unified “aspect-aware” navigation across emails, tickets, docs, and code; dynamic gap analysis for knowledge assets.
- Tools/products/workflows: Connectors to DMS/EDRMS, wikis, code repos; embeddings infra; policy-compliant data pipelines.
- Assumptions/dependencies: Data governance and access control; content deduplication at scale; multi-tenant isolation.
- Contract and case-law analysis with aspect extraction (LegalTech)
- Use case: Extract covenant types, obligations, exceptions, and case factors; intra-document navigation by aspect with sentiment/stance labels.
- Tools/products/workflows: Secure doc viewers; clause libraries; continuous learning from attorney feedback.
- Assumptions/dependencies: High-precision models; jurisdictional variance; confidential processing.
- Scientific synthesis at scale (Academia/Pharma)
- Use case: Cross-paper aspect maps (e.g., methods, datasets, outcome measures, limitations) with confidence scores and contradiction flags.
- Tools/products/workflows: Domain ontologies; evidence grading; living reviews auto-updated with new literature.
- Assumptions/dependencies: Standardized metadata; citation grounding; contradiction detection; inter-annotator-agreement benchmarks.
- Personalized reading tutors and metacognitive coaching (Education/EdTech)
- Use case: Adaptive guidance on what to read and how, with aspect-driven strategies and reflection prompts based on student progress.
- Tools/products/workflows: AI tutors integrated with LMS; analytics on aspect mastery; formative feedback loops.
- Assumptions/dependencies: Learning science validation; bias/fairness audits; privacy protections for student data.
- Accessibility-forward intelligent readers (Accessibility/Assistive tech)
- Use case: Voice and screen-reader companions that announce aspect summaries and enable voice navigation by aspect across documents.
- Tools/products/workflows: ARIA-compliant sidebars; speech interfaces; low-vision optimized layouts.
- Assumptions/dependencies: Robust multi-modal parsing; latency constraints for real-time TTS; multilingual support.
- Collaborative sensemaking and consensus-building platforms (Civic tech/Policy)
- Use case: Stakeholders co-construct aspect maps for proposals; system highlights underrepresented aspects and biases.
- Tools/products/workflows: Multi-user dashboards; provenance tracking; deliberation support tools.
- Assumptions/dependencies: Methods for bias detection/mitigation; moderation; civic process integration.
- Autonomous research agents with novelty-seeking loops (Software/AI agents)
- Use case: Agents that read, extract options/aspects, identify gaps, and autonomously search for non-redundant new evidence.
- Tools/products/workflows: Agent frameworks; novelty scoring; safe exploration policies; human approval checkpoints.
- Assumptions/dependencies: Reliable long-horizon planning; cost controls; guardrails against error cascades.
- Multilingual, cross-cultural sensemaking (Global markets/Education)
- Use case: Aspect scaffolds and annotations across languages, tuned to cultural norms and region-specific criteria.
- Tools/products/workflows: Multilingual NLI/LLMs; locale-aware prompting; cross-lingual retrieval.
- Assumptions/dependencies: High-quality multilingual models; culturally sensitive design; evaluation across locales.
- Content management systems with aspect-aware authoring (Software/CMS)
- Use case: Authors get feedback on aspect coverage, redundancy, and missing sections during writing; readers see aspect previews out-of-the-box.
- Tools/products/workflows: CMS plugins (WordPress, Drupal); editor sidebars; writer-quality metrics.
- Assumptions/dependencies: Adoption by authors; alignment with editorial standards; compute costs during authoring.
- Platform-level knowledge integrity (Misinformation/Platform policy)
- Use case: Platforms label articles with aspect coverage and encourage diversification of sources in feeds; users discover less redundant, more comprehensive views.
- Tools/products/workflows: Ranking signals for aspect diversity; transparency dashboards.
- Assumptions/dependencies: Policy alignment; risk of gaming; fairness and viewpoint diversity considerations.
Notes on feasibility across applications
- Dependencies: Stable access to high-quality LLMs; prompt libraries; Self-Refine or equivalent to reduce hallucination; optional RAG for grounding; paragraph-level NLI classifiers.
- Risks/assumptions: Hallucination and outdated model knowledge (mitigated by local grounding and RAG); privacy/compliance when sending content off-device; domain adaptation needed for specialized areas; English-centric performance unless multilingual models are added.
- UX integration: Browser extensions are low-friction for immediate deployment; large-scale or regulated use requires secure, audited infrastructures and human oversight.
Glossary
- Anchoring bias: A cognitive bias where initial information disproportionately influences subsequent judgments; in prompting, early outputs can bias later ones. "To minimize potential anchoring biases, we strive to achieve a balance between relevance and diversity in our prompting strategy."
- BART-large-MNLI: A BART model fine-tuned on Multi-Genre Natural Language Inference, commonly used for zero-shot classification tasks. "We used the bart-large-mnli model"
- Chain-of-thought prompting: A prompting technique that elicits step-by-step reasoning in LLMs to improve problem solving. "It also aligns with the idea of Chain-of-thought prompting proposed by \cite{wei_chain--thought_2023}"
- Context window size: The maximum number of tokens an LLM can process in a single input, affecting how much text it can consider at once. "and expansive context window size \cite{openai_gpt-4_2023} to directly extract options from the entire text content of a web page."
- Cosine distance: A measure of dissimilarity between vectors based on the cosine of the angle between them, often used with embeddings. "based on the cosine distances on topic semantic embeddings computed using SentenceBERT~\cite{reimers_sentence-bert_2019}."
- Crowdsourcing: Collecting information or work from a large distributed group of people, often via online platforms. "or crowdsourcing \cite{chang_alloy:_2016,chilton_cascade_2013,hahn_knowledge_2016}."
- Duplicate detection algorithms: Techniques that identify and filter out duplicate or near-duplicate documents in retrieval systems. "despite the extensive use of duplicate detection algorithms in modern search engines \cite{plegas_reducing_2013}."
- Entailment (in NLI): A relation where a hypothesis logically follows from a premise, used as a label in NLI tasks. "The entailment and contradiction probabilities are then converted into label probabilities"
- Grounding (LLMs): Linking model outputs to external sources or user-provided content to improve accuracy and verifiability. "2) grounding LLM generations with the content that users would actually read, enabling natural verification."
- Hallucination (LLMs): The tendency of LLMs to generate plausible-sounding but incorrect or fabricated information. "However, LLMs face well-known challenges like hallucination and falsehood \cite{thorp_chatgpt_2023,bang_multitask_2023,terry_ai_2023}"
- In-situ annotations: Inline annotations presented directly within the reading context (e.g., at paragraph starts) to summarize or tag content. "Selenite provided {in-situ annotations} of mentioned criteria at the beginning of each paragraph"
- Knowledge graph: A structured representation of entities and their relationships used for reasoning and retrieval. "making them potentially valuable for tasks like knowledge graph querying and retrieving common sense information"
- Knowledge retriever: A component that identifies and supplies relevant knowledge to support downstream tasks or generation. "Selenite leverages GPT-4, an LLM developed by OpenAI, as a knowledge retriever"
- LLMs: Very large neural LLMs trained on massive text corpora with broad capabilities in generation and reasoning. "leverages LLMs as reasoning machines and knowledge retrievers"
- Natural Language Inference (NLI): The task of determining whether a hypothesis is entailed by, contradicts, or is neutral with respect to a premise. "following a natural language inference (NLI) paradigm \cite{yin_benchmarking_2019}"
- Oracle (in prompting): An idealized source of authoritative answers used conceptually to obtain ground-truth or comprehensive guidance. "we directly query an ``oracle'' for a globally applicable and comprehensive set of criteria."
- Retrieval-Augmented Generation (RAG): A technique that augments generation by retrieving relevant external documents to ground model outputs. "such as retrieval-augmented generation (RAG) \cite{lewis_retrieval-augmented_2020}"
- Semantic embeddings: Vector representations that capture the meaning of text, enabling similarity comparison and clustering. "topic semantic embeddings computed using SentenceBERT~\cite{reimers_sentence-bert_2019}"
- Semantic web standards: Conventions and best practices for adding machine-interpretable meaning to web content (e.g., semantic HTML). "web pages frequently disregard semantic web standards and best practices \cite{mendes_toward_2018,henschen_using_2009}"
- Self-Refine: An iterative prompting technique where the model critiques and improves its own outputs. "reducing hallucination through techniques such as Self-Refine \cite{madaan_self-refine_2023};"
- SentenceBERT: A model that produces high-quality sentence embeddings for semantic similarity and clustering. "computed using SentenceBERT~\cite{reimers_sentence-bert_2019}"
- Sensemaking: The process of building a mental model to interpret and act within an information space. "Sensemaking in unfamiliar domains can be challenging, demanding considerable user effort to compare different options with respect to various criteria."
- Topic recognition: Automatically identifying and labeling the subject or theme of a document or web page. "Automatically recognizing topics."
- Transformer models: Neural architectures based on self-attention mechanisms, foundational to modern LLMs. "recent advances in large pre-trained transformer models \cite{vaswani_attention_2017,devlin_bert_2019,lewis_bart_2019}"
- World knowledge (LLMs): Factual and commonsense information implicitly stored in model parameters during pretraining. "the world knowledge of an LLM is out-of-date"
- Zero-shot text classification: Classifying text into categories without task-specific labeled training data, often via NLI prompts. "fine-tuned to perform zero-shot text classification tasks"
Collections
Sign up for free to add this paper to one or more collections.

