- The paper introduces Themis, a framework that augments reward models by integrating external tools like calculators and search engines.
- Themis achieves a 19.2% performance boost on complex tasks such as arithmetic operations, factual lookups, and code execution compared to conventional reward models.
- Its multi-stage implementation enhances transparency and interpretability in RLHF, with human evaluations showing a 32% win rate over baseline models.
The paper "Tool-Augmented Reward Modeling" (2310.01045) introduces an innovative enhancement to traditional Reward Models (RMs) used in Reinforcement Learning from Human Feedback (RLHF) by integrating capabilities for dynamic tool invocation. This novel framework, named Themis, empowers RMs with the capability to perform complex tasks by leveraging external tools such as calculators and search engines, addressing critical limitations encountered by traditional RMs in tasks demanding arithmetic computation, factual lookup, and code execution.
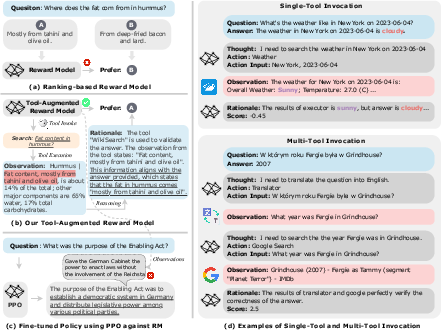
Figure 1: A diagram illustrating the pipeline of (a) Vanilla reward models (RMs); (b) Tool-augmented RMs, namely {Themis} and its tool use process.
Motivations and Themis Framework
Within the landscape of LLMs, RMs have been utilized for optimizing these models to predict and align with human preferences. However, conventional RMs utilize static internal representations which are limited in handling real-time updates, arithmetic operations, or complex reasoning tasks. The Themis model is presented as a robust alternative by enriching RMs with the capability for dynamic interaction with external tools.
The Themis framework consists of stages that span thought formulation, action specification for tool invocation, collection of observations from the tools, synthesis of acquired information, and generation of a scalar reward score. This step-by-step reasoning enhances transparency and interpretability in the decision-making process, mitigating the "black box" nature of conventional RMs and fostering trustworthiness.
To accommodate the training of Themis, the authors created the Tool-Augmented Reward dAtaset (TARA) which represents a diverse compilation of data spanning multiple domains. TARA integrates interactions with seven distinct external tools, providing a comprehensive set of instances for each. The dataset construction pipeline leverages a combination of high-quality open-source data and multi-agent interactions for the generation of tool-invocation processes, as demonstrated in an illustration of this data creation pipeline.
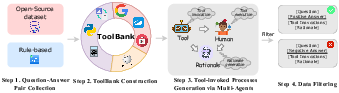
Figure 2: An illustration of data creation pipeline for the Tool-Augmented Reward dAtaset (TARA).
Implementation of Themis
The Themis framework operates by orchestrating tool engagements broken into distinct stages: Thought, Action, Observation, Rationale, and finally Reward, predicting a scalar output encapsulating human preference for a given task. The integration of external tools facilitates a dynamic reasoning process within the RM, thereby allowing it to contemplate and execute tool invocations where necessary, enhancing the RM's use of API calls to gather pertinent information from the environment.
During implementation, Themis uses a reward loss function, closely related to a pairwise ranking loss, which aligns with previously established loss formulations by \cite{summarize_feedback}. The reward modeling process is designed within both single-tool and mixed-tool settings, offering a comprehensive suite of seven distinct external tools.
Experimental Findings
The experimental results from the study reveal that Themis consistently outperforms its conventional RM counterparts, RM (Bert-Large) and RM (Vicuna-7B). In single-tool settings, Themis achieved an average improvement of 19.2% across eight distinct tasks evaluated against traditional RMs, demonstrating a particularly notable enhancement in tasks requiring access to real-time information, arithmetic operations, and low-resource languages.
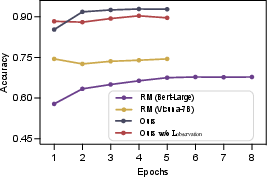
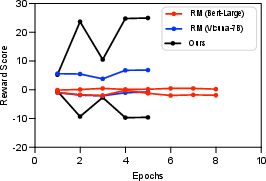
Figure 3: Left: Model performance for various training epoch numbers; Right: Visualization of the change of average reward scores with training epochs. The top reward score line of each model corresponds to the positive answer, while the bottom line corresponds to the negative answer.
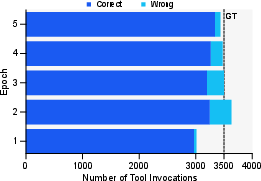
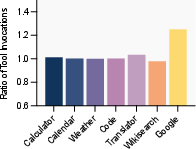
Figure 4: Left: The variations in the number of correctly invoked tools and incorrectly invoked tools. The dashed line is the total number of invoked tools in TARA. And the pentagram refers to the best performance epoch. Right: Comparison of the number of invoked different tools.
Further investigation highlights the benefit of scaling Themis to larger model sizes such as Vicuna-33B, confirming the trend that larger models with tool augmentation demonstrate superior performance, aligning with conventional scaling laws. The integration of tools is further supported by the human evaluation results, where Themis attains an average 32% win rate compared to baselines across four distinct tasks.
Implications and Future Directions
The implications of this study are multifaceted. Practically, Themis provides an approach that bridges the gap between LLMs and real-time information retrieval, arithmetic tasks, and other challenging functionalities, securing a broader applicability in real-world scenarios. Moreover, the transparency in the reasoning process may enhance the interpretability and, consequently, the trustworthiness of AI systems.
The framework's application in RLHF showcases its potential for reformulating reward systems to incorporate external insights effectively. As automated negative generation agents simulate adverse examples, RMs can generalize beyond traditional constraints, particularly in multi-tool configurations, addressing various real-world challenges like truthfulness and intricate problem-solving.
Future research could encompass the expansion of the toolbank to include a larger range of tool APIs and experimentation with models possessing more than 100B parameters. Probing the dynamics of multi-turn interactions represents an additional avenue of interest, potentially enabling a deeper understanding and development of RMs in conversational AI contexts. Additionally, the investigation of latency and robustness considerations across diverse network conditions and tool capabilities will be essential for practical applications.
Conclusion
In conclusion, the "Tool-Augmented Reward Modeling" approach offers a methodologically robust expansion of the RM paradigm by incorporating external tools. This integration allows RMs to perform dynamic reasoning and interact with real-world environments, thus addressing the intrinsic limitations encountered by traditional RMs in RLHF settings. The superior performance of Themis, particularly when assessed against vanilla reward modeling baselines, underscores its potential for enhancing task-specific efficacy, reliability, and truthfulness. The comprehensive tool-augmented reward dataset, TARA, underscores the broader implications for the field of RLHF, opening vistas for further research into the integration of diverse tool APIs and the exploration of multi-turn dialogues.

