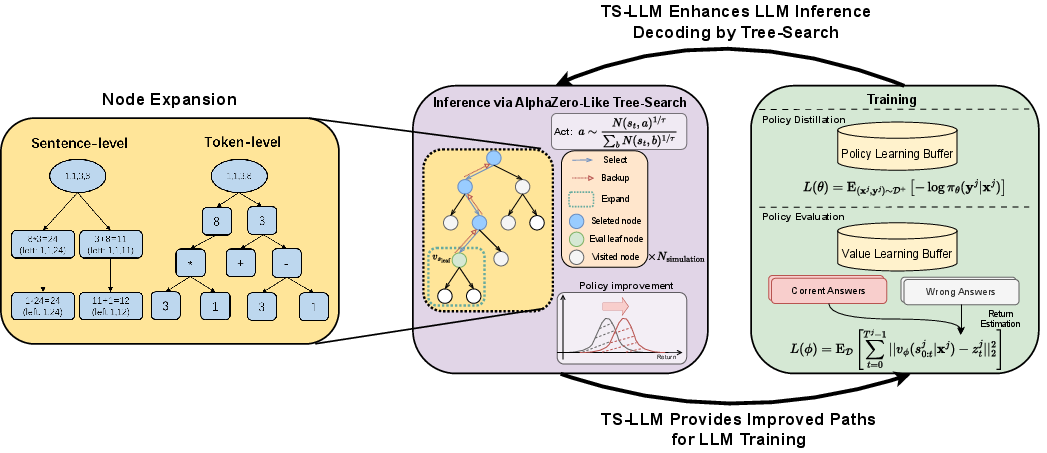
Alphazero-like Tree-Search can Guide Large Language Model Decoding and Training
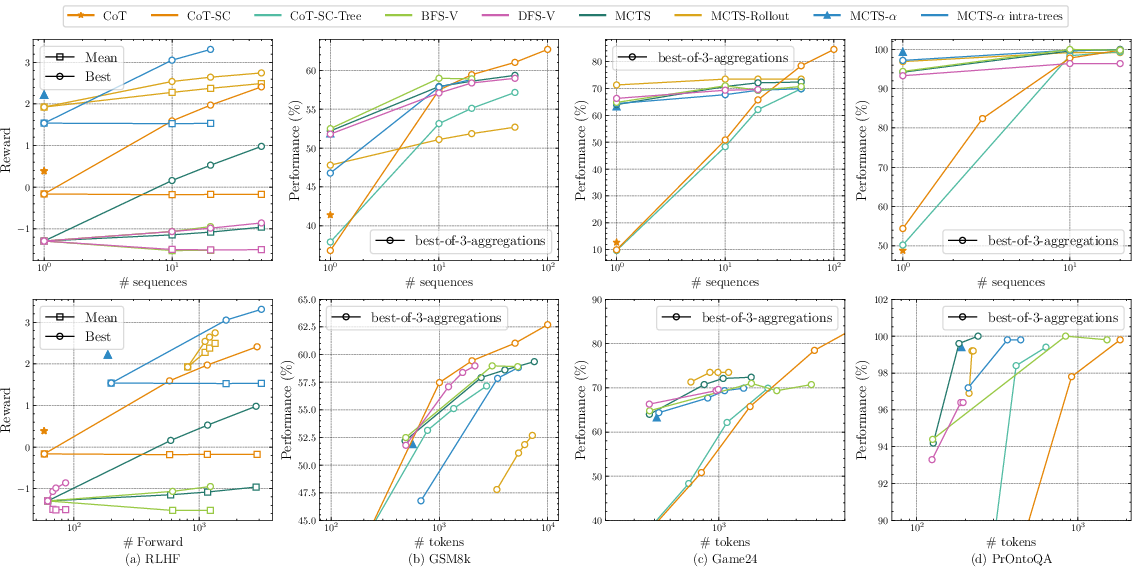
Abstract: Recent works like Tree-of-Thought (ToT) and Reasoning via Planning (RAP) aim to augment the reasoning capabilities of LLMs by using tree-search algorithms to guide multi-step reasoning. These methods rely on prompting a pre-trained model to serve as a value function and focus on problems with low search depth. As a result, these methods will not work in domains where the pre-trained LLM does not have enough knowledge to serve as an effective value function or in domains that require long-horizon planning. To address these limitations, we present an AlphaZero-like tree-search learning framework for LLMs (termed TS-LLM), systematically illustrating how tree-search with a learned value function can guide LLM decoding. TS-LLM distinguishes itself in two key ways. (1) Leveraging a learned value function and AlphaZero-like algorithms, our approach can be generally adaptable to a wide range of tasks, LLMs of any size, and tasks of varying search depths. (2) Our approach can guide LLMs during both inference and training, iteratively improving the LLM. Empirical results across reasoning, planning, alignment, and decision-making tasks show that TS-LLM outperforms existing approaches and can handle trees with a depth of 64.
- Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Rémi Coulom. Efficient selectivity and backup operators in monte-carlo tree search. In International conference on computers and games, pp. 72–83. Springer, 2006.
- Selection-inference: Exploiting large language models for interpretable logical reasoning. arXiv preprint arXiv:2205.09712, 2022.
- Dahoas. Synthetic-instruct-gptj-pairwise. https://huggingface.co/datasets/Dahoas/synthetic-instruct-gptj-pairwise.
- Raft: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767, 2023.
- Chessgpt: Bridging policy learning and language modeling. arXiv preprint arXiv:2306.09200, 2023.
- Specializing smaller language models towards multi-step reasoning. arXiv preprint arXiv:2301.12726, 2023.
- Reinforced self-training (rest) for language modeling. arXiv preprint arXiv:2308.08998, 2023.
- Textbooks are all you need. arXiv preprint arXiv:2306.11644, 2023.
- Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992, 2023.
- Learning and planning in complex action spaces. In International Conference on Machine Learning, pp. 4476–4486. PMLR, 2021.
- Maieutic prompting: Logically consistent reasoning with recursive explanations. arXiv preprint arXiv:2205.11822, 2022.
- Bandit based monte-carlo planning. In European conference on machine learning, pp. 282–293. Springer, 2006.
- Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213, 2022.
- Machine translation decoding beyond beam search. arXiv preprint arXiv:2104.05336, 2021.
- Solving quantitative reasoning problems with language models. Advances in Neural Information Processing Systems, 35:3843–3857, 2022.
- Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.
- Making ppo even better: Value-guided monte-carlo tree search decoding, 2023.
- Jieyi Long. Large language model guided tree-of-thought. arXiv preprint arXiv:2305.08291, 2023.
- Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651, 2023.
- Nadia Matulewicz. Inductive program synthesis through using monte carlo tree search guided by a heuristic-based loss function. 2022.
- OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
- Christopher D Rosin. Multi-armed bandits with episode context. Annals of Mathematics and Artificial Intelligence, 61(3):203–230, 2011.
- Abulhair Saparov and He He. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. arXiv preprint arXiv:2210.01240, 2022.
- Mastering atari, go, chess and shogi by planning with a learned model. Nature, 588(7839):604–609, 2020.
- Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Reflexion: an autonomous agent with dynamic memory and self-reflection. arXiv preprint arXiv:2303.11366, 2023.
- Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017a.
- Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017b.
- Reinforcement learning: An introduction. MIT press, 2018.
- Galactica: A large language model for science. arXiv preprint arXiv:2211.09085, 2022.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022.
- Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Decomposition enhances reasoning via self-evaluation guided decoding. arXiv preprint arXiv:2305.00633, 2023.
- Haotian Xu. No train still gain. unleash mathematical reasoning of large language models with monte carlo tree search guided by energy function. arXiv preprint arXiv:2309.03224, 2023.
- Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601, 2023.
- Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825, 2023a.
- Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825, 2023b.
- Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488, 2022.
- Planning with large language models for code generation. arXiv preprint arXiv:2303.05510, 2023.
- Lima: Less is more for alignment. arXiv preprint arXiv:2305.11206, 2023.
- Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022.
- Solving math word problem via cooperative reasoning induced language models. arXiv preprint arXiv:2210.16257, 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

