- The paper presents the Qwen series advancement with specialized LLMs optimized via SFT and RLHF for enhanced language understanding.
- The paper demonstrates that Qwen-14B achieves state-of-the-art performance across 12 datasets, outperforming comparable open-source models.
- The paper highlights effective encoding efficiency and tool use, including code interpretation and data visualization through ReAct prompting.
"Qwen Technical Report" (2309.16609): An Extensive Exploration of the Qwen Model Series
The Qwen series of LLMs, as presented in the "Qwen Technical Report" (2309.16609), offers an expansive insight into the development and capabilities of cutting-edge LLMs at Alibaba Group. This series features models designed with various parameter counts and aligned using sophisticated techniques to enhance natural language processing tasks across multiple domains.
Overview of Qwen Models
The Qwen model series encompasses a comprehensive range of LLMs, all pretrained on massive datasets consisting of trillions of tokens. The Qwen base models exhibit robust performance across a multitude of tasks. Special emphasis is placed on Qwen-Chat models, particularly those finetuned with Supervised Finetuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). These models are developed to align with human preferences and demonstrate advanced competencies in tool-use and complex task execution such as code interpretation and mathematics.
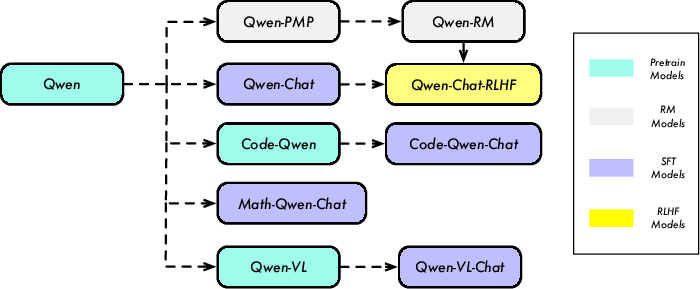
Figure 1: Model Lineage of the Qwen Series, highlighting the progression from Qwen to Code-Qwen, Code-Qwen-Chat, and Math-Qwen-Chat models.
The Qwen-14B model, a flagship member of the Qwen series, outperforms previous state-of-the-art (SOTA) open-source models at similar scales, offering a competitive edge against proprietary models like GPT-3.5 across 12 diverse datasets. Notably, the Qwen models significantly excel in tasks related to language understanding and reasoning, positioning themselves as robust competitors in the LLM landscape.
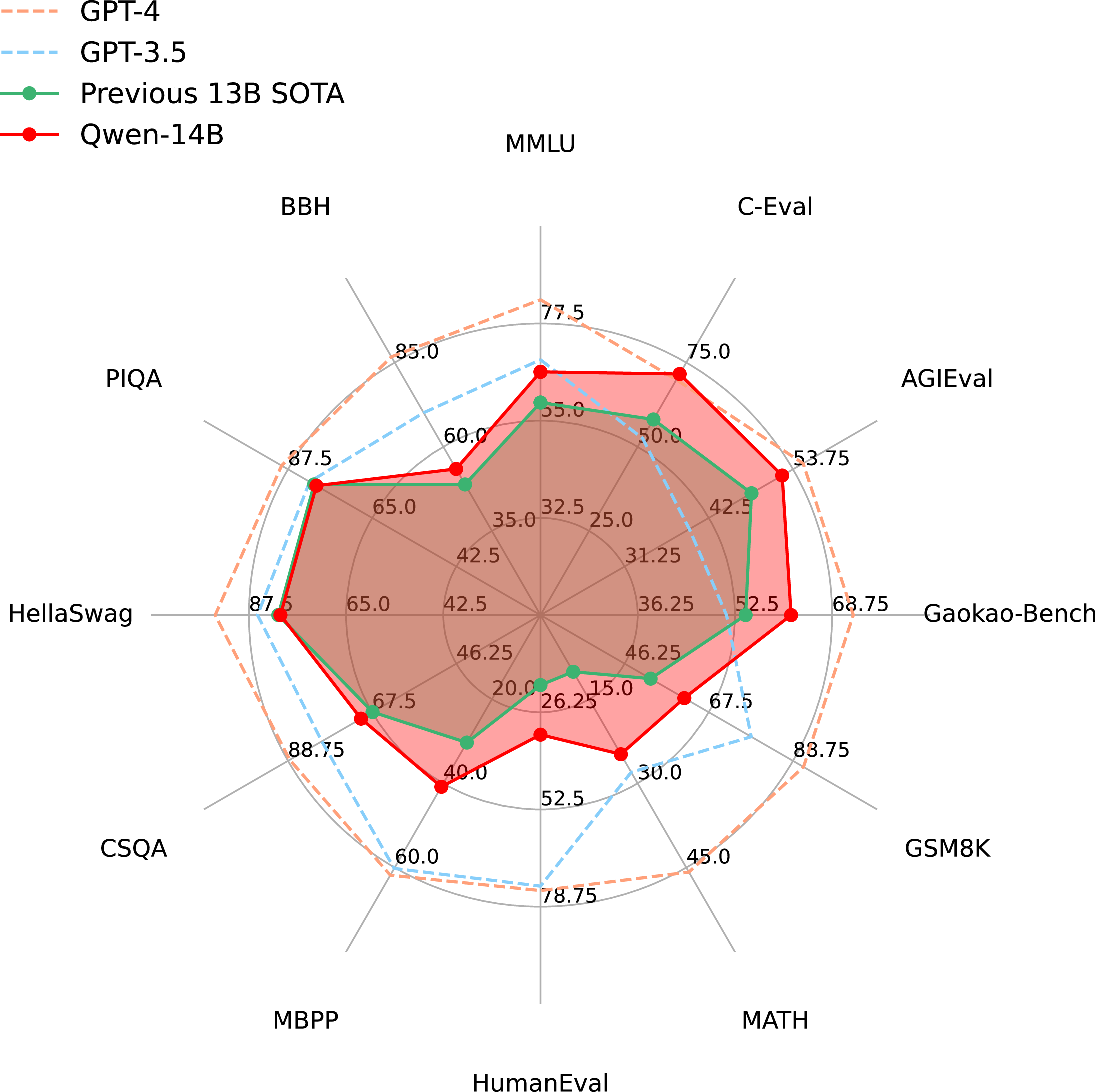
Figure 2: Performance comparison of GPT-4, GPT-3.5, previous 13B SOTA, and Qwen-14B.
Encoding Efficiency and Human Evaluation
The efficiency of Qwen's tokenizer demonstrates superior encoding compression rates across multiple languages, optimizing both training and inference processes.
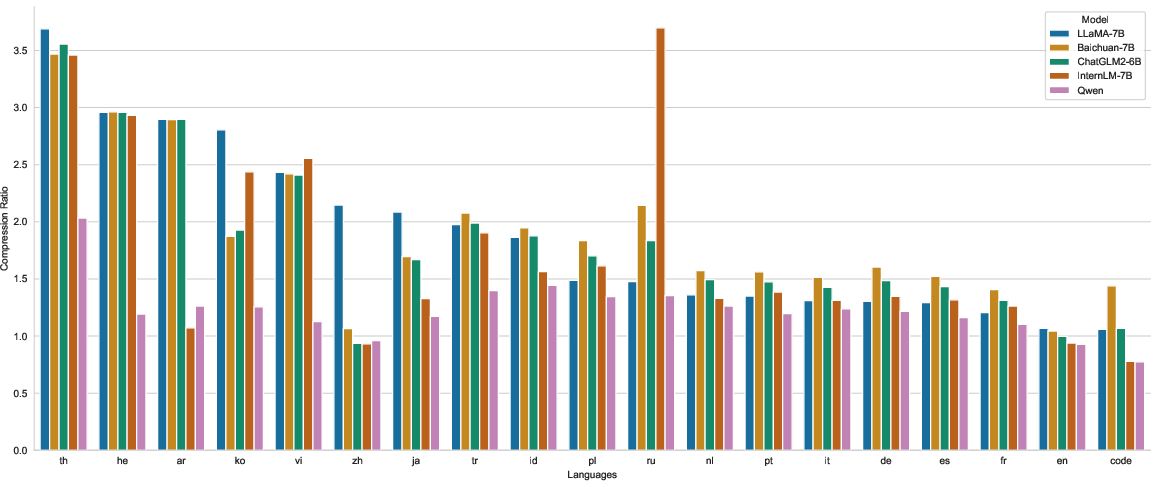
Figure 3: Encoding compression rates of different models, illustrating Qwen's high efficiency across languages.
Human evaluations further validate the alignment and capability of the Qwen-Chat models. These assessments reveal that RLHF-finetuned models outperform their SFT counterparts on average, offering responses that align closely with human preferences.
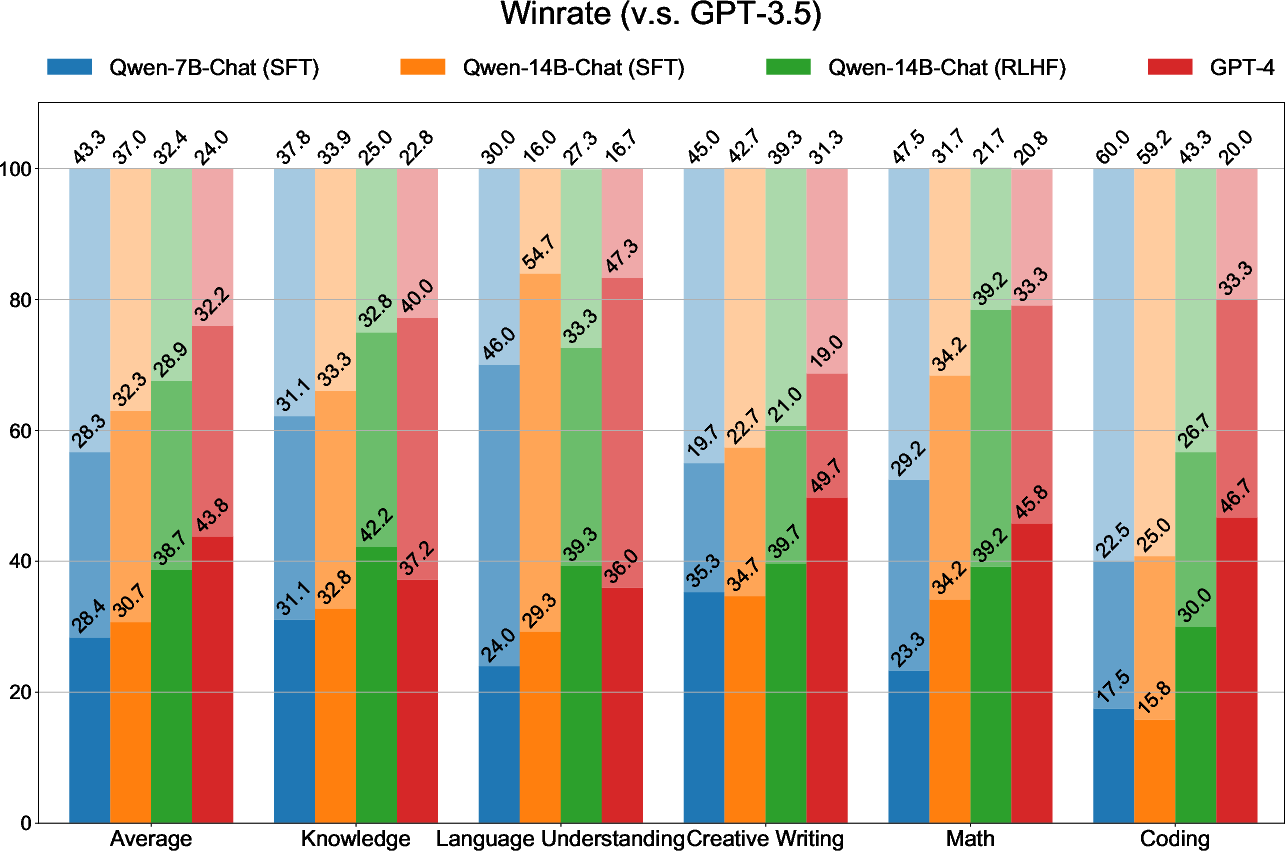
Figure 4: Results from human evaluations comparing Qwen-7B and Qwen-14B models, showing the superior performance of RLHF versions.
The Qwen series integrates capabilities to utilize tools effectively via ReAct prompting and supports the use of code interpreters for advanced task execution. Qwen-Chat models adeptly engage in data manipulation and visualization tasks, as demonstrated by their effective use of Python interpreters to resolve complex math problems and data analysis tasks.
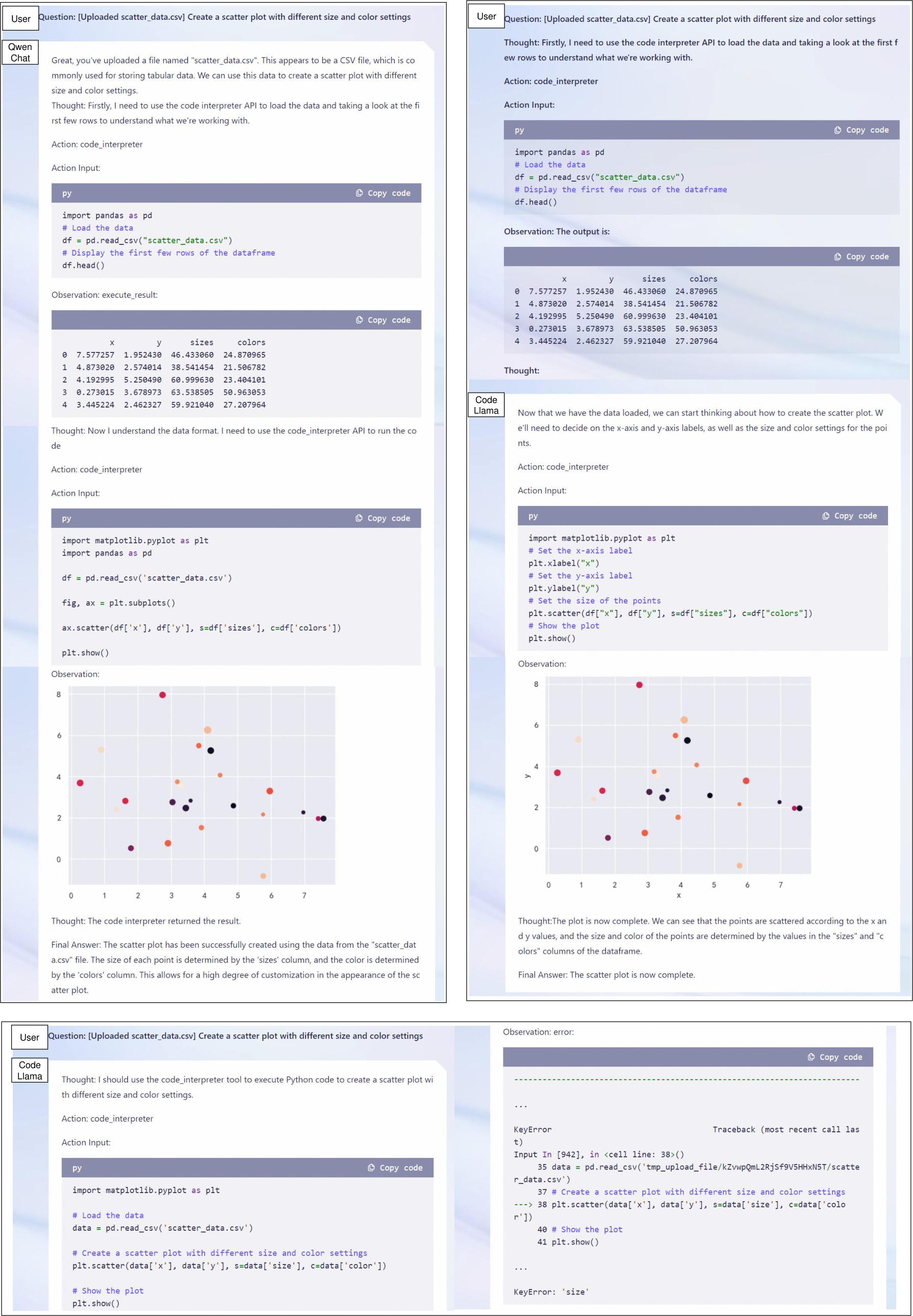
Figure 5: Qwen-Chat's execution of code interpretation showcased through ReAct prompting; highlighting its ability to address CSV data effectively.
Conclusion
The Qwen series represents a pivotal advancement in the development of LLMs, integrating extensive training datasets with cutting-edge alignment techniques such as SFT and RLHF. The specialized models for coding and mathematics equip Qwen to tackle domain-specific challenges with proficiency close to proprietary models. These innovations set a precedent for future LLM developments, with the Qwen series offering a robust foundation for further exploration and application in expansive AI domains.