- The paper introduces a robust framework that automates preprocessing by enhancing speech quality, segmenting audio, and assigning speaker labels.
- It employs state-of-the-art models like BSRNN for noise reduction and TDNN-based VAD with spectral clustering for effective segmentation and speaker diarization.
- Experimental results validate improved transcription accuracy and speaker similarity, supporting advancements in ASR, TTS, and speaker verification tasks.
AutoPrep: An Automatic Preprocessing Framework for In-the-Wild Speech Data
The paper "AutoPrep: An Automatic Preprocessing Framework for In-the-Wild Speech Data" presents an innovative framework that addresses the challenges of preprocessing large-scale in-the-wild speech data to improve its usability for various speech technologies. This paper introduces AutoPrep, which automates the enhancement of speech quality, the generation of annotations, and the production of transcription labels.
Introduction
The processing of large-scale speech data typically involves challenges due to poor quality and a lack of annotations such as speaker labels or transcriptions. Traditional approaches to handling these issues require extensive human annotation, which is resource-intensive and costly. The AutoPrep framework aims to alleviate these challenges by automating the preprocessing of speech data collected from diverse, real-world sources like podcasts and audiobooks. The framework comprises several components, including speech enhancement, voice activity detection-based segmentation, speaker clustering, target speech extraction, quality filtering, and automatic speech recognition.
Framework Components
Speech Enhancement
AutoPrep employs the BSRNN model for speech enhancement, which is particularly adept at dealing with varying sampling rates and offers state-of-the-art performance in noise reduction. The model is utilized to reduce background noise and improve the clarity of speech data, ensuring that subsequent tasks such as segmentation and ASR are performed on high-quality audio.
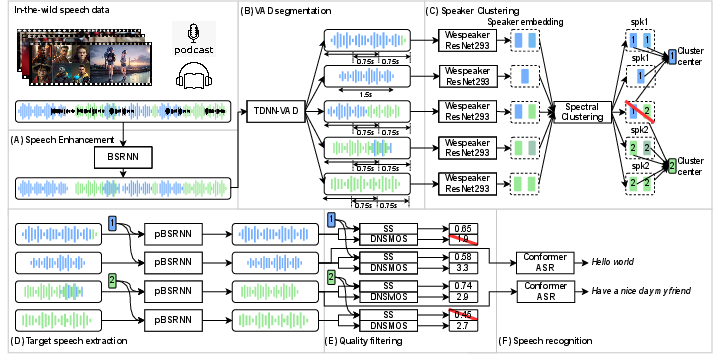
Figure 1: The diagram of the proposed full-band AutoPrep framework.
Speech Segmentation and Speaker Clustering
Using a TDNN-based VAD model, AutoPrep segments speech data to exclude non-speech parts. This ensures that only effective speech segments are retained for further processing. The framework then uses a spectral clustering algorithm to assign speaker labels to each segment, leveraging speaker embeddings computed by the ResNet293 model. This clustering step is critical for applications requiring speaker-specific data, such as multi-speaker TTS systems.
Target Speech Extraction and Quality Filtering
Target speech extraction is achieved through a modified personalized BSRNN model, cleaning up overlaps in speech and isolating individual speaker tracks. The framework employs filtering metrics such as DNSMOS to ensure output quality, discarding segments with low speech quality scores.
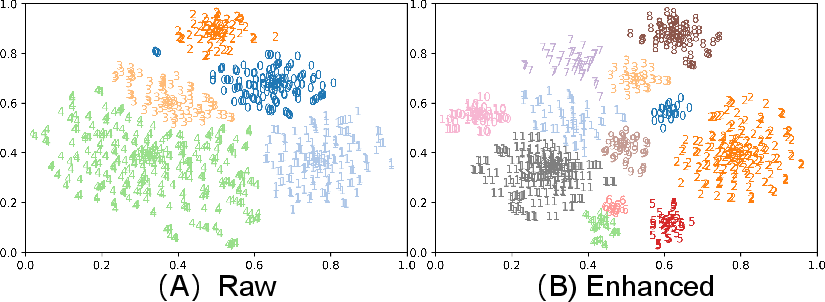
Figure 2: T-SNE Visualization of speaker clustering for utterance "Y0000007481_J1rSmaVd4aE" in WenetSpeech.
Automatic Speech Recognition
The framework culminates in the application of a conformer-based RNN-T ASR system to generate text transcriptions for the processed speech data, supporting multilingual capabilities and high accuracy in transcription.
Experimental Results
Significant improvements were observed in both speech quality and annotation accuracy across WenetSpeech and AutoPrepWild datasets when processed through AutoPrep. The preprocessed data demonstrated comparable or superior quality to other open-source datasets, reflected in metrics such as DNSMOS and PDNSMOS scores. Furthermore, application of AutoPrep on multi-speaker TTS models showed enhanced speaker similarity and MOS results, underscoring the utility of AutoPrep as a preprocessing tool.
Conclusion
AutoPrep presents a robust framework for preprocessing in-the-wild speech data, addressing annotation and quality challenges comprehensively and automatically. This automation holds significant potential for advancing speech model training in applications such as TTS, SV, and ASR by streamlining data preparation processes. The framework not only improves data quality but also generates essential annotations, facilitating more effective development of speech technologies. As future work, enhancing the transcription accuracy and expanding the framework's applications remain promising avenues for further research.