- The paper demonstrates a pure attention-based Transformer model that significantly improves blind room volume estimation accuracy over CNN baselines.
- The approach employs Gammatone magnitude spectra and low-frequency phase features with transfer learning from ImageNet to robustly map acoustic signals to room volume.
- Extensive evaluations on real and synthetic datasets reveal superior performance metrics and enhanced generalization in noisy environments.
Introduction
The estimation of geometric room volume from reverberant audio is a fundamental task in modern acoustic environment parameterization. Applications range from speech dereverberation to audio augmented reality, where precise knowledge of the room's spatial properties enhances filter design and enables seamless integration of virtual sound sources. Traditional blind room parameter estimation frameworks have predominantly employed convolutional neural networks (CNNs) trained on spectro-temporal features. This paper proposes a paradigm shift, introducing a fully attention-based Transformer architecture for blind room volume estimation from single-channel noisy speech. The model leverages Gammatone magnitude spectra and low-frequency phase features, augmented by cross-modality transfer learning from large-scale vision data, and generates state-of-the-art regression results across both real and synthetic room datasets.
System Design
The proposed approach eschews convolutional structures in favor of a pure Transformer backbone, motivated by recent evidence from audio classification studies that self-attention models can overtake CNNs in pattern recognition tasks. The feature extraction pipeline produces a two-dimensional representation of input audio via a Gammatone filterbank, covering 20 spectral bands and providing both magnitude and phase information. Low-frequency phase and its first-order derivatives are concatenated to the magnitude features, resulting in 30 feature channels per frame.
Patches of 16×16 are extracted from the feature block with overlap in both dimensions, projected into high-dimensional embeddings, and augmented with learnable positional encodings. To counteract limited domain-specific data, weights from a Vision Transformer (ViT), pretrained on ImageNet, are repurposed using channel averaging and position encoding adjustment. The full sequence, prepended with a [CLS] token, is processed by a Transformer encoder; the model's output is linearly mapped to the scalar room volume label.
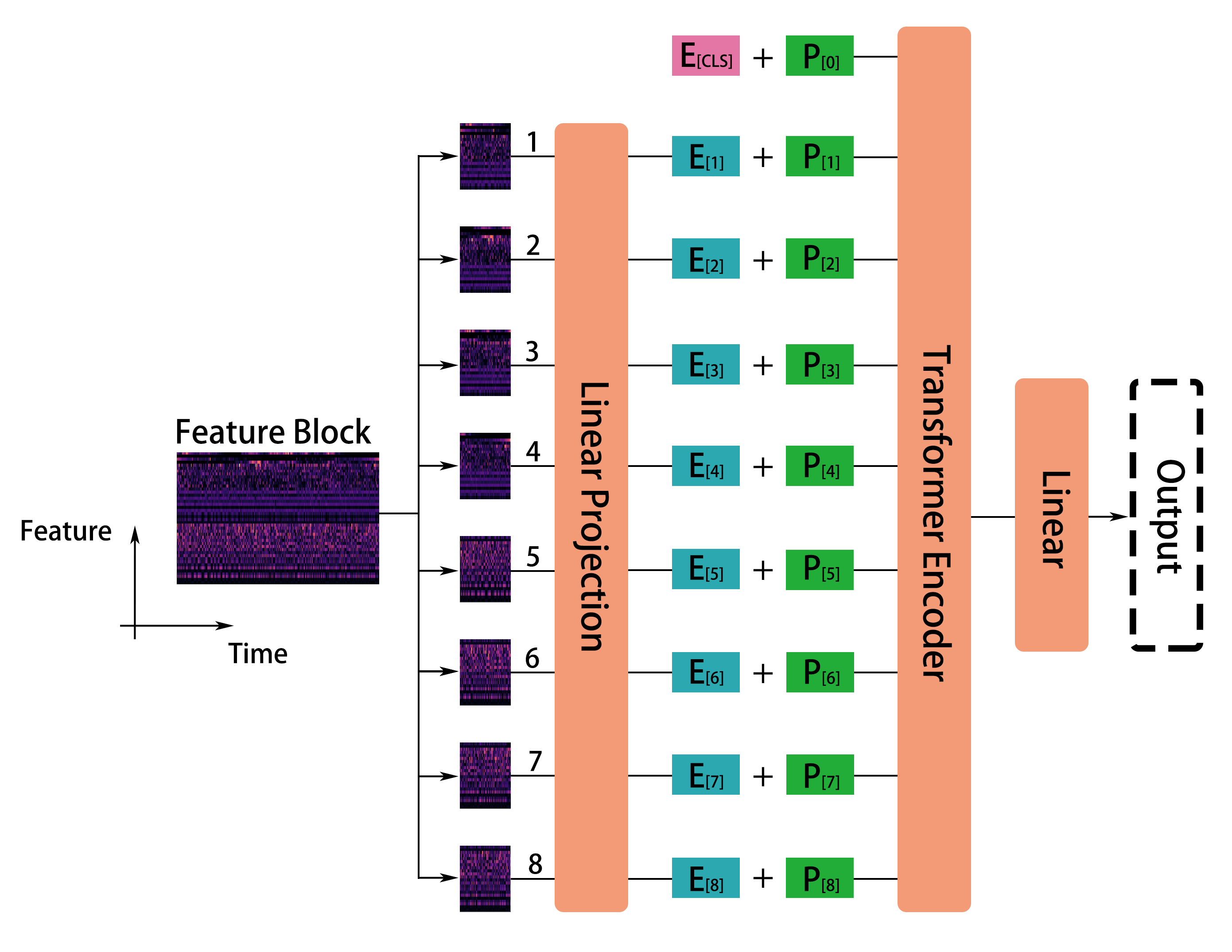
Figure 1: Schematic of the Transformer-based system for blind room volume estimation, highlighting the feature extraction and patch-wise embedding pipeline.
Data Preparation and Augmentation
Room Impulse Response (RIR) data were sourced from six established datasets, including ACE Challenge, AIR, BUT ReverbDB, OpenAIR, C4DM, dechorate, and extended with 30 simulated RIRs generated via pyroomacoustics to supplement volume distribution in sparse regions. All RIRs were resampled uniformly to 16kHz. Volume annotations span from 12 m3 to 21,000 m3, encompassing regular and irregular geometries.
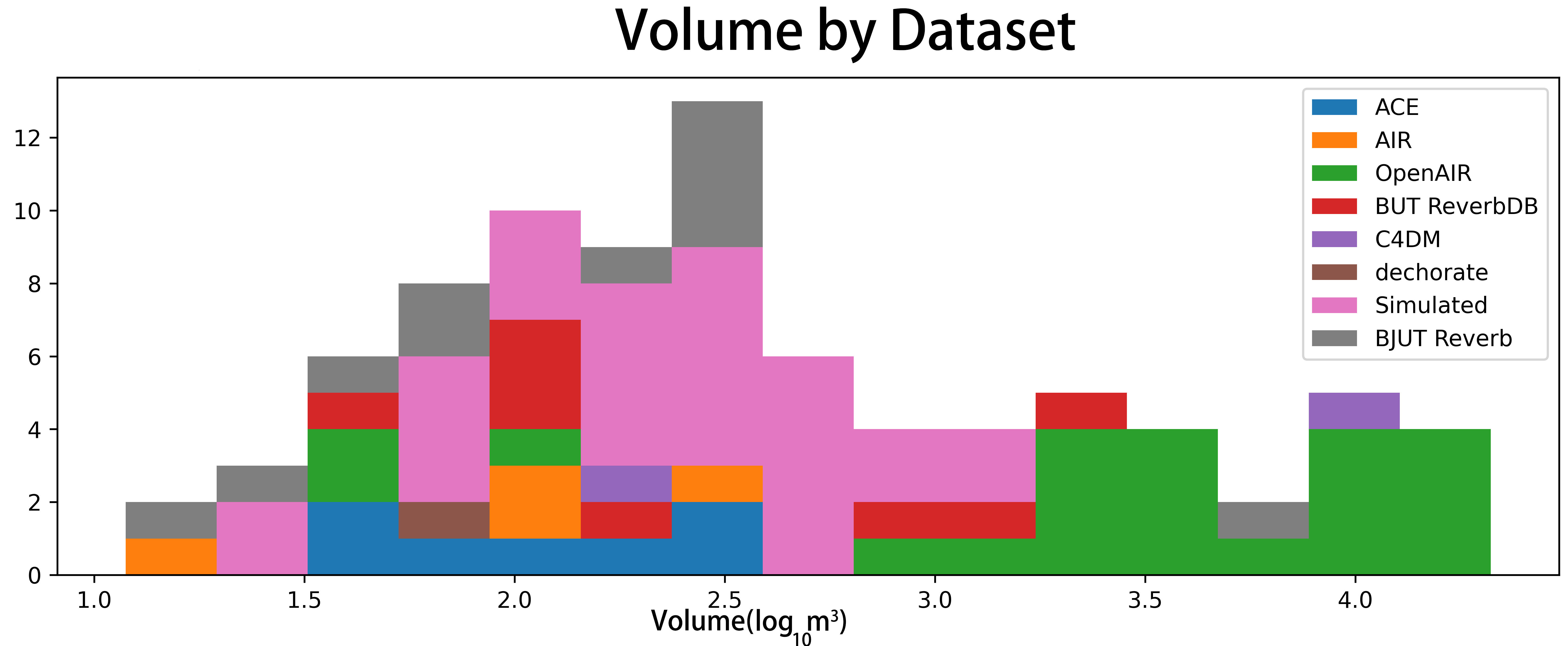
Figure 2: Histogram of RIR volume distribution across diverse public and in-house datasets.
To create reverberant speech, anechoic utterances were convolved with RIRs, and both white and babble noise were injected at varying SNRs to test noise invariance. Data augmentation included SpecAugment operations applied to the mel spectrogram domain, introducing frequency/time masking and warping to expand generalization capacity. This resulted in two primary training corpora: Dataset I (basic augmentation) and Dataset II (SpecAugment-enhanced).
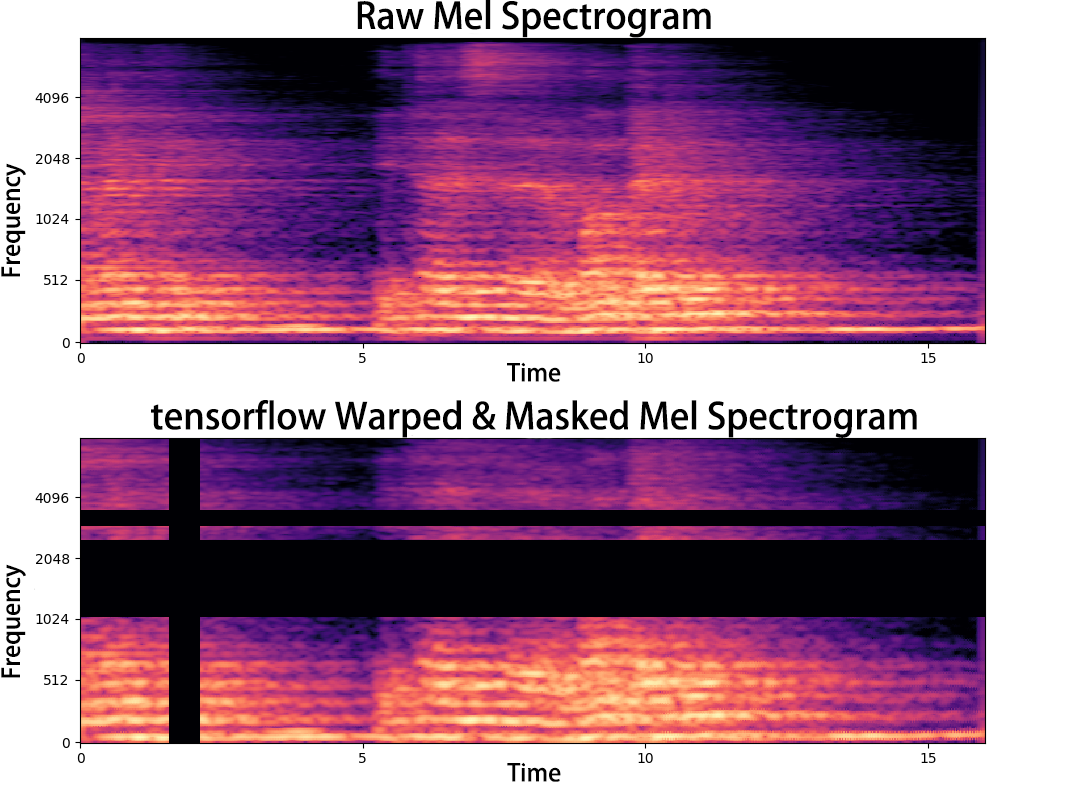
Figure 3: Depiction of SpecAugment data augmentation procedures on reverberant speech spectrograms.
Experimental Evaluation
The accuracy of the room volume predictors was validated under extensive conditions, comparing the proposed Transformer against a recent CNN-based baseline ("+Phase" model). Evaluation metrics comprise MSE, MAE, Pearson correlation (ρ), and MeanMult (MM): the geometric mean of absolute log ratio between estimated and reference volumes.
Without transfer learning, the attention-based model already surpasses the CNN baseline: on Dataset I, MSE drops from 0.3863 (CNN) to 0.2650, MAE from 0.4837 to 0.3432, and MM from 3.0532 to 2.2039, with ρ improving from 0.6984 to 0.8077. Further improvements are noted through ImageNet pretraining and SpecAugment—MAE is reduced to 0.2423 and MM to 1.7470, corresponding to median and mean absolute errors of 155 m3 and 1219 m3 respectively (over volumes up to 21,000 m3), significantly outperforming the CNN system even after aggressive data augmentation.
The confusion analysis reveals tighter prediction distributions near ground truth volumes for the Transformer system, indicating robust generalization over complex acoustic domains.
Implications and Future Directions
This study provides conclusive evidence that pure attention-based architectures—when combined with domain-appropriate input features and transfer learning—can supersede CNN-based schemes for audio regression tasks. The exploitation of global context via self-attention enables more effective learning of indirect acoustic-geometry mappings from speech, especially in heterogeneous, noisy conditions.
Practically, these models offer improved accuracy and domain transferability for tasks such as room fingerprinting, speech dereverberation, and immersive audio rendering in AR/VR settings. Theoretically, they reinforce the argument for attention-centric models in regression domains previously considered the preserve of convolutional methods.
Further work should extend evaluation to dynamic conditions (e.g., changing room geometry, variable-length utterances) and explore joint estimation of multiple acoustic parameters. The scalability of transfer learning across modalities also invites investigation into unsupervised pretraining schemes.
Conclusion
This paper establishes that convolution-free Transformers, endowed with suitable features and pretrained weights, constitute a powerful framework for blind room volume estimation from single-channel speech. The results demonstrate not only marked improvements over CNNs but also the feasibility of leveraging large, cross-modal vision datasets for audio parameter regression tasks, engendering robust acoustic analysis systems applicable to wide-reaching domains.