- The paper introduces Hofstede’s Cultural Alignment Test (CAT) to quantify LLMs' cultural behaviors across six dimensions.
- It demonstrates that GPT-4 outperforms GPT-3.5 and Llama 2 in capturing cultural nuances, especially in Chinese contexts.
- The study shows that hyperparameter adjustments can improve cultural alignment, highlighting the need for culturally diverse datasets.
Cultural Alignment in LLMs
This essay explores the research paper titled "Cultural Alignment in LLMs: An Explanatory Analysis Based on Hofstede's Cultural Dimensions" (2309.12342). The research aims to address the cultural alignment challenge in LLMs by implementing Hofstede's cultural dimension framework, focusing on models like GPT-3.5, GPT-4, and Llama 2. The study assesses LLMs' cultural values, highlighting potential misalignments and developmental implications.
Methodology
The research introduces Hofstede's Cultural Alignment Test (Hofstede's CAT) to quantify the cultural alignment of LLMs based on Hofstede's six-dimensional framework: Power Distance (PDI), Uncertainty Avoidance (UAI), Individualism (IDV), Masculinity (MAS), Long-term Orientation (LTO), and Indulgence (IVR). This framework is visualized in a structured format (Figure 1).
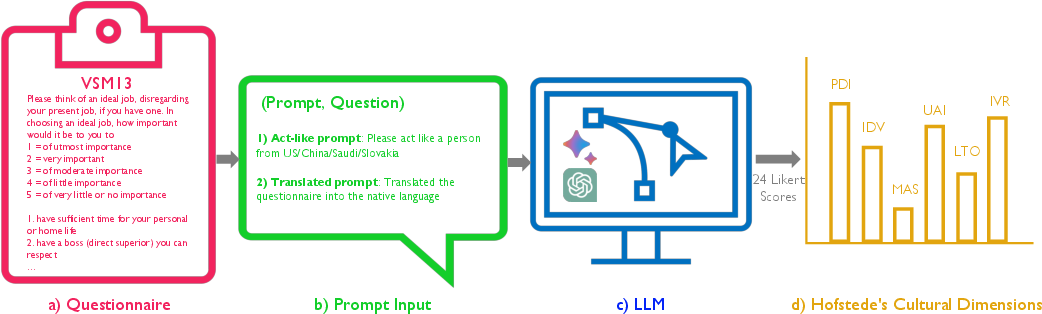
Figure 1: Our framework, Hofstede's Cultural Alignment Test (Hofstede's CAT) for LLMs, detailing the VSM13 questionnaire, the LLM prompts, the instructing LLMs, and the resulting cultural dimensions derived from the LLM's responses.
To evaluate the LLMs, four distinct prompting methods were used:
- Model Level Comparison: Evaluates the intrinsic cultural values of LLMs across different languages—English, Chinese, and Arabic.
- Country Level Comparison: Instructs LLMs to simulate personas from specific regions (United States, China, and Arab countries) and assesses the response alignment.
- Hyperparameter Comparison: Analyzes the effect of temperature and top-p settings on LLMs' responses to cultural dimensions.
- Language Correlation: Evaluates variations in responses of Llama 2 models fine-tuned on different languages.
The research utilizes the VSM13 survey questions, analyzing demographic assumptions due to the lack of inherent demographics in LLMs. Cultural dimensions are computed based on responses averaged across multiple seeds for statistical robustness.
Experimental Results
The study reveals varying levels of cultural alignment across the evaluated models. Notably, GPT-4 exhibits enhanced capability in understanding cultural nuances compared to its counterparts, particularly in the Chinese context.
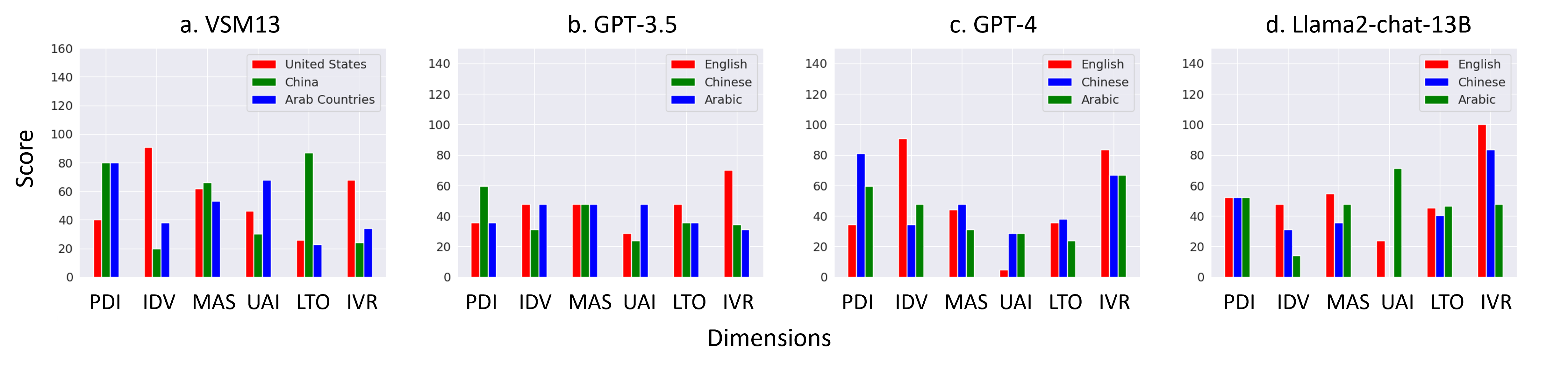
Figure 2: Display of real-world VSM13 scores and normalized scores from models GPT-3.5, GPT-4, and Llama 2 for the countries in focus.
The model-level comparison shows GPT-4 achieving a positive average Kendall Tau correlation coefficient (0.11), indicating better performance in capturing cultural nuances without a specific persona. In contrast, GPT-3.5 and Llama 2 show significant challenges.
Country-level comparison also highlights GPT-4's adaptive capability. However, the research notes significant misalignments, especially for the United States and Arab countries, with performance better in representing Chinese cultural aspects. Mis-ranked cultural dimensions highlight the difficulty of reflecting societal complexities accurately.
Hyperparameter variations demonstrate the significance of configurations on cultural expression. Adjustments in temperature and top-p settings show improved alignment under specific conditions, emphasizing the influence of model configurations on cultural sensitivity.
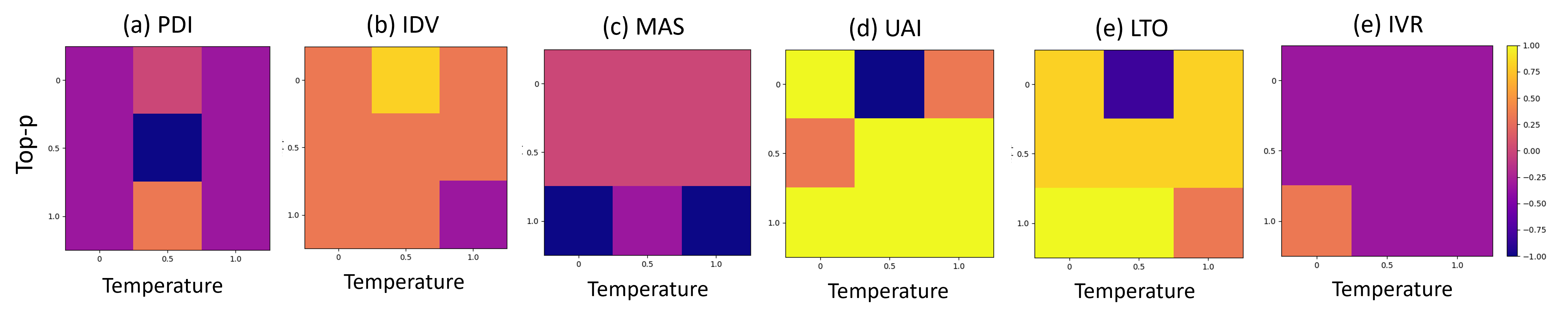
Figure 3: The changes in cultural dimensions upon changing the temperature and top-p settings in GPT-3.5.
Conclusion
This research addresses a critical gap in evaluating cultural alignment within LLMs through Hofstede's CAT, proposing an insightful framework for model assessment. The analysis indicates GPT-4's relative superiority in cultural adaptation among the tested models, albeit with disparities across regions. The findings underscore the necessity for culturally diverse datasets and fine-tuning approaches to enhance global acceptance of AI models.
The research also highlights the limitations of current LLM capabilities in capturing cultural nuances faithfully, necessitating further investigation into bias mitigation techniques. Future explorations could expand the cultural scope and incorporate additional tuning methodologies to enhance AI systems' sensitivity and inclusivity across diverse societal frameworks.