- The paper proposes a novel approach to reduce hallucinations by verifying LLM-generated answers through retrieving supporting evidence.
- It utilizes both sparse (BM25) and dense retrieval methods, achieving an 80% accuracy in self-verifying answers in an open-domain setting.
- The findings highlight limitations in retrieval efficiency and prompt design, suggesting further research is needed to enhance LLM reliability.
Retrieving Supporting Evidence for Generative Question Answering
The paper "Retrieving Supporting Evidence for Generative Question Answering" (2309.11392) addresses a significant challenge in the advancement of LLMs - their tendency to produce hallucinated answers which can appear convincing even when incorrect. This research explores whether LLMs can self-verify their generated answers against an external corpus using retrieval methods. Specifically, it examines the degree to which LLMs hallucinate answers in an open-domain setting and proposes methodologies for automatic answer validation using sparse and dense retrieval pipelines.
Introduction and Background
Recent improvements in NLP via transformer-based LLMs, such as BERT and GPT-3, have significantly advanced text generation tasks, including question answering. Despite these advancements, LLMs are prone to generating convincing yet inaccurate information, known as hallucinations. This paper tackles the critical issue of hallucination, especially in sensitive domains like healthcare, by validating LLM-generated answers against external sources.
The authors utilize information retrieval (IR) approaches, which rapidly locate relevant documents from large corpora, to address hallucinations. The retrieval-augmented generation approach conditions text generation on retrieved documents, but this method still suffers from hallucinations. This research explores retrieval after generation, where the LLM verifies its output against supporting evidence.
Methodology
The study employs two experiments conducted on the MS MARCO (V1) test collection, utilizing questions and passages therein for validation. The first experiment assesses generated answers in their entirety by querying a combination of questions and answers against a corpus using sparse and dense retrieval techniques. The setup involves two retrieval methods: the Okapi BM25 ranking function for sparse retrieval and a neural retrieval pipeline for dense retrieval. Validation occurs as the LLM compares generated answers with retrieved passages.
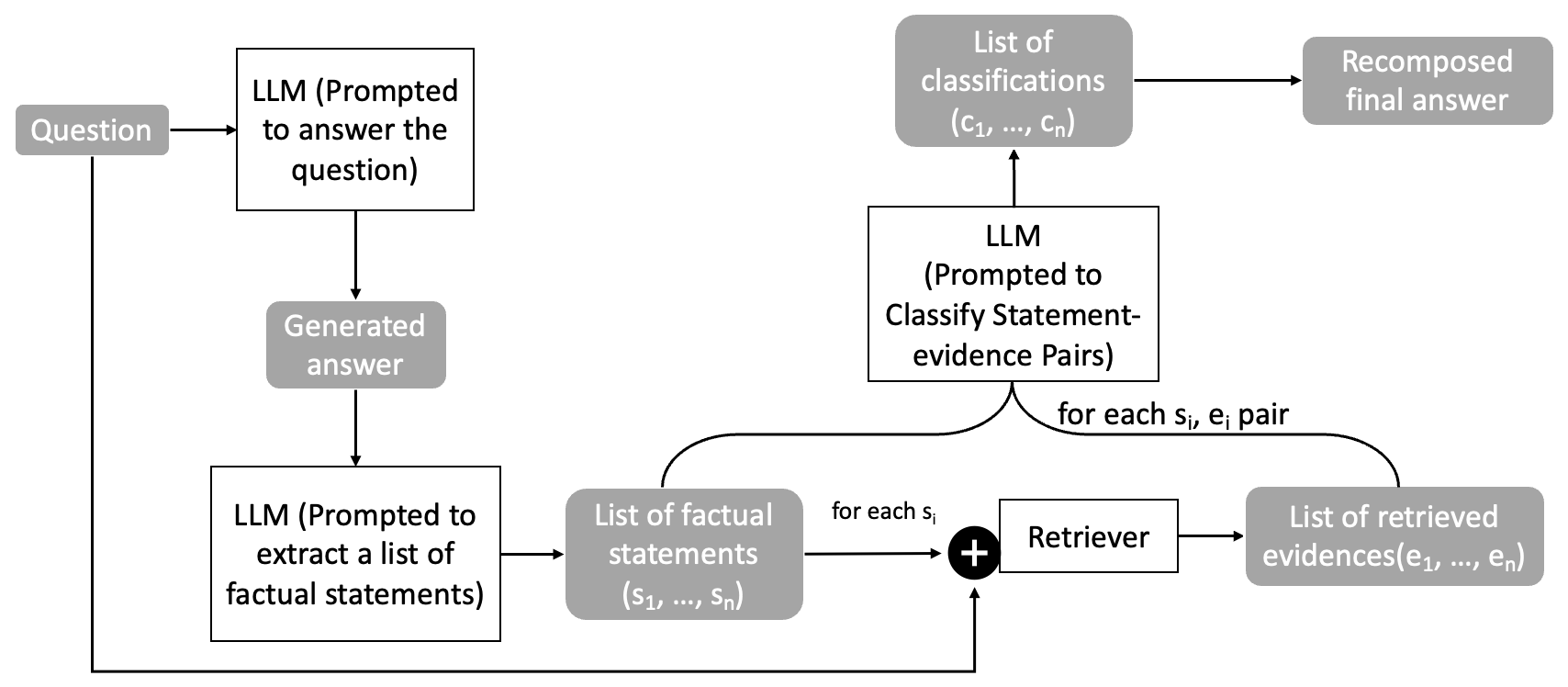
Figure 1: Self-detecting hallucination in LLMs.
The second experiment evaluates the generated answers at a more granular level, extracting factual statements from the generated answers and verifying each statement individually. This involves decomposing text into atomic assertions and validating each against retrieved evidence.
Figure 2: Overview of fact-based self-detecting hallucination in LLMs.
Results
The paper reports an 80% accuracy of LLMs in verifying their own answers when given supporting passages. However, the verification process only reduces hallucination but does not eliminate it. The experiments demonstrate the efficacy of combining generation with post-generation verification, suggesting that LLMs can self-detect hallucinations by leveraging retrieval systems.
Figure 3 illustrates the classification steps involved in validating answers, emphasizing that the overall structure of the original text is maintained despite contradictions during post-editing.
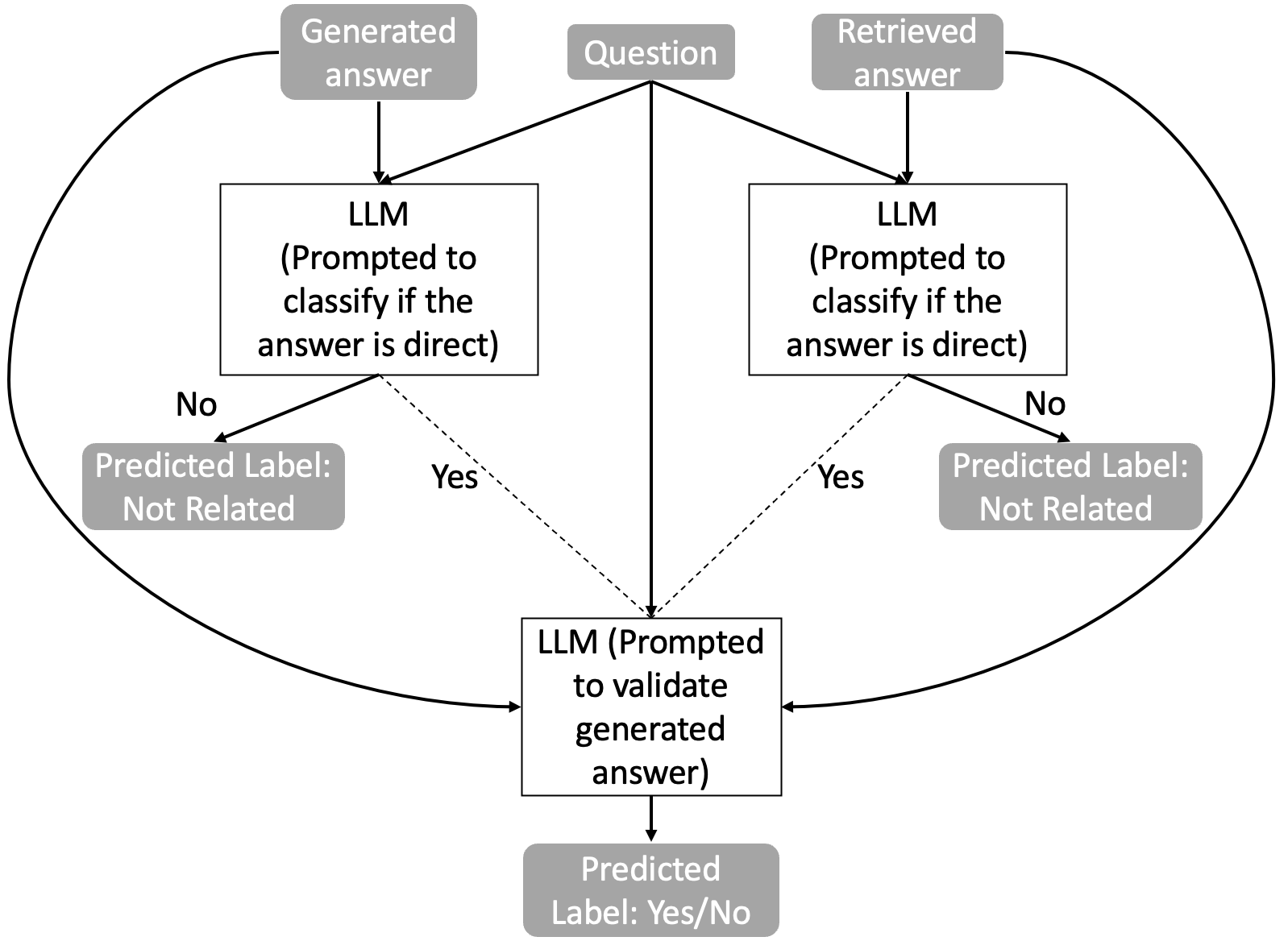
Figure 3: Stepped classification of a question-answers pair.
Furthermore, discrepancies in manual labeling revealed that retrieval inefficiencies and prompt limitations can lead to missed hallucinations, necessitating further research into improved methodologies for self-verification.
Conclusion
This research identifies and tests methodologies for verifying LLM-generated answers, marking a step towards reducing hallucination in generative question answering. While the paper's proposed techniques effectively reduce hallucinations, they do not entirely eliminate them. Future work could involve more sophisticated prompt engineering, fine-tuning LLMs, and experimenting with various retrieval systems.
The implications of this study extend to enhancing the reliability of LLMs in critical applications. Continued research in this area is vital to developing high-assurance generative models that consistently produce accurate and trustworthy outputs.
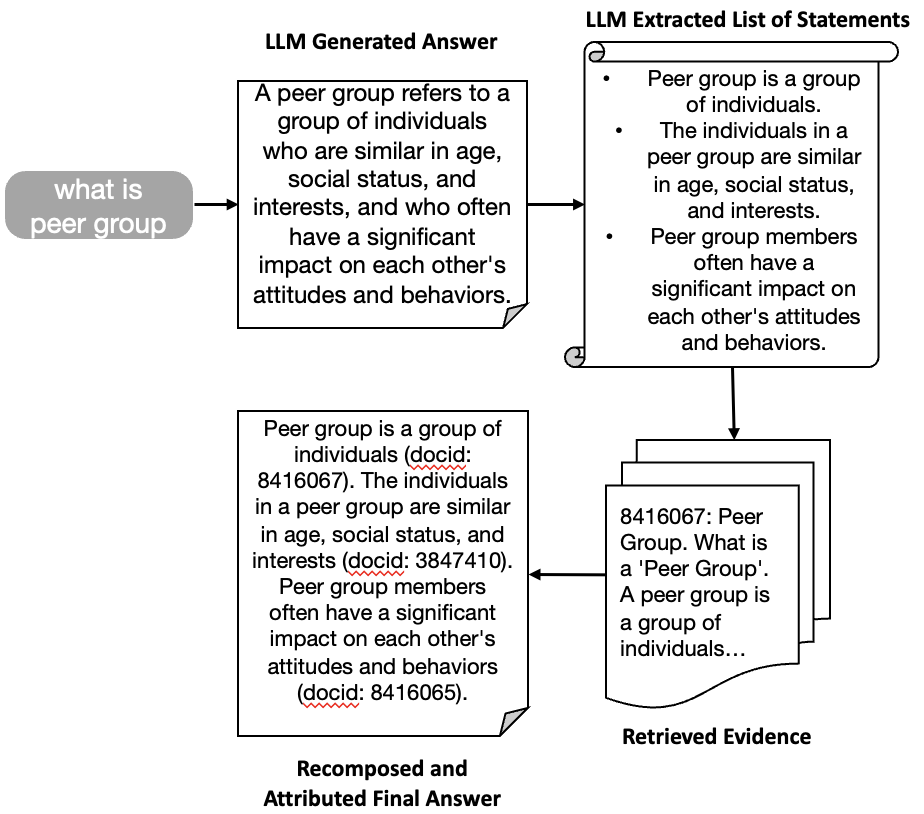
Figure 4: Example of fact-based self-detecting hallucination in LLMs.

