- The paper identifies that increased prompt formality and concreteness reduce hallucinations in LLMs, notably in advanced models like GPT-4.
- It employs a dataset of New York Times tweets with Mechanical Turk annotations to classify hallucination types including person, location, number, and acronym.
- Findings suggest that adjusting linguistic elements in prompt engineering can enhance LLM reliability by mitigating factual errors.
The paper "Exploring the Relationship between LLM Hallucinations and Prompt Linguistic Nuances: Readability, Formality, and Concreteness" investigates how specific linguistic features in prompts influence hallucinations in LLMs. This essay explores the study's findings, methodology, and implications for mitigating LLM hallucinations through linguistic adjustments.
Hallucination in LLMs: An Introduction
LLMs, including notable models like GPT-4 and DALL-E, possess capabilities in various applications, yet they face challenges, notably hallucinations—outputs containing factual inaccuracies. These disturbances hinder reliable use, particularly in sensitive domains like healthcare and finance. The paper identifies two primary techniques for addressing these issues: black-box methods that operate with limited external inputs and gray-box methods that integrate predefined knowledge.
Prompt engineering is emphasized as a mitigation strategy, framing prompts to guide models toward producing accurate information. The study leverages findings from previous work on how LLMs perform with information located at different positions within the input context, revealing performance disparities, especially concerning mid-context information retrieval (Figure 1).
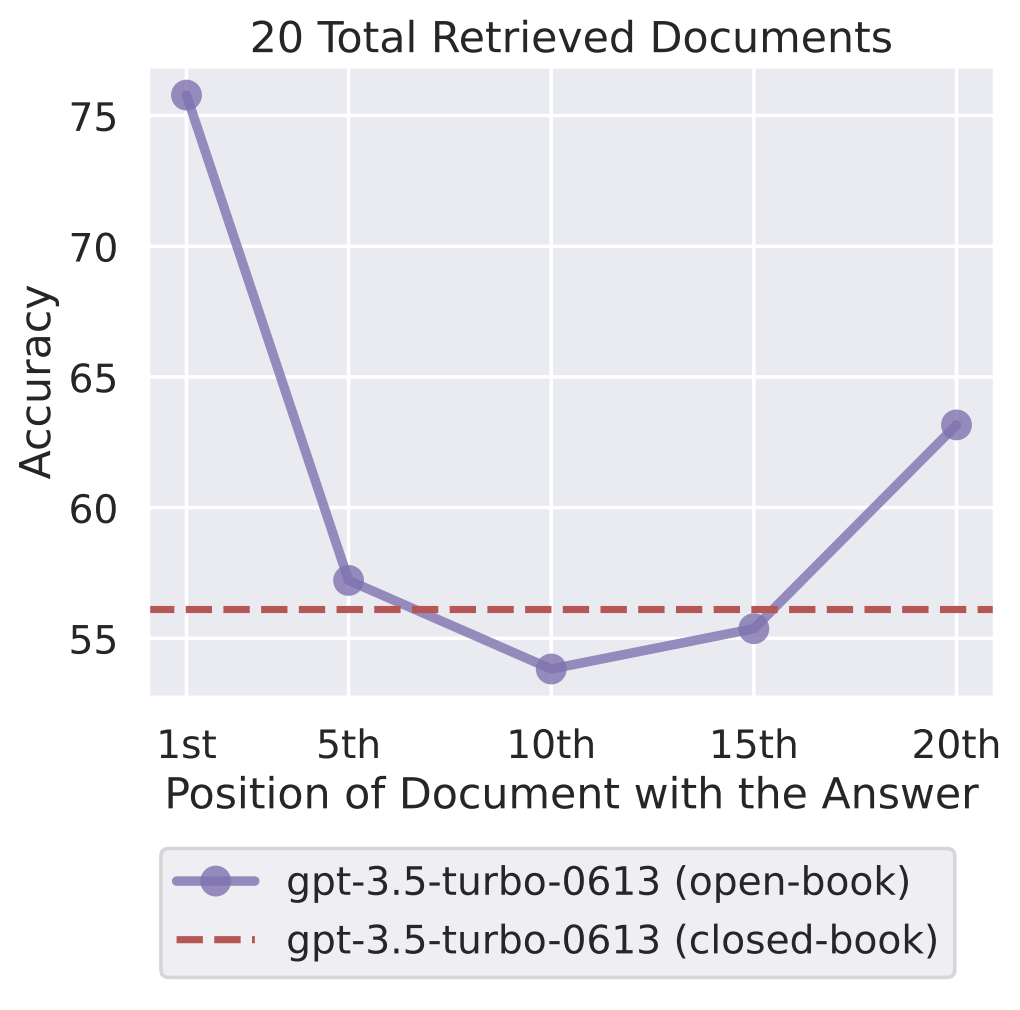
Figure 1: Empirical results indicating LLM performance relative to information positions within input contexts.
Types of Hallucination
The paper categorizes hallucinations into four types: Person, Location, Number, and Acronym, providing examples for each. Person and Location hallucinations involve fictional characters and places, respectively [Ladhak et al., 2023]. Number hallucinations generate incorrect numerical data, while Acronym hallucinations involve incorrect expansions in context. The categorization offers a foundation for measuring how linguistic nuances in prompts relate to these hallucination types.
Dataset and Annotation
The study constructed a dataset from New York Times news tweets, providing a factual baseline for LLM outputs. The selection of 15 state-of-the-art LLMs, from GPT-4 to less complex models like T0, facilitates a comprehensive examination of hallucination phenomena across architectures. Annotation was performed using Amazon Mechanical Turk to classify hallucinations, organizing data into the four categories previously mentioned.
Linguistic Characteristics of Prompts
The paper examines three core linguistic properties: Readability, Formality, and Concreteness, proposing specific research questions for each. Readability assesses comprehension ease using the Flesch Reading Ease Score (FRES), exploring whether complex or lengthy prompts influence hallucination likelihood. Formality reflects linguistic decorum, potentially impacting hallucination through sophisticated or casual language use. Concreteness evaluates tangibility in language, assessing if detailed prompts mitigate hallucinations.
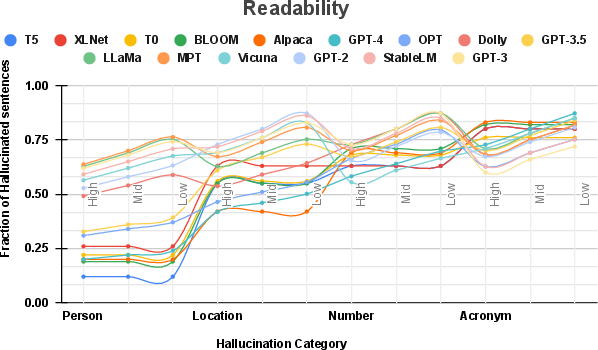
Figure 2: Relationship between prompt readability and hallucination rates.
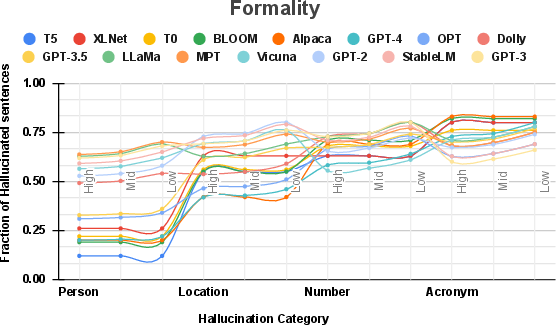
Figure 3: Influence of prompt formality on hallucination incidence.
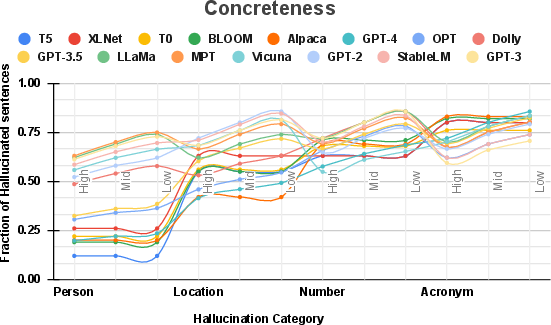
Figure 4: Effect of concreteness in prompts on hallucination likelihood.
Findings
The study reveals that increased prompt formality and concreteness generally reduce hallucination incidence, with less conclusive findings regarding readability. These results are illustrated in Figures 3, 4, and 5, highlighting complexities and variations in LLM responses across differing linguistic dimensions. Formal language and specific, concrete prompts were more effective in mitigating hallucinations, specifically in more advanced models like GPT-4 and OPT.
Conclusion
This research advances understanding of how linguistic nuances in prompts affect hallucination generation in LLMs. By targeting readability, formality, and concreteness, the study provides critical insights for optimizing LLM applications. Future investigations could extend these findings by considering additional linguistic properties and exploring adaptation across varying LLM architectures. This work contributes substantially to the refinement of LLM prompt engineering techniques, opening avenues for enhanced deployment in real-world scenarios.

