ConsistencyTTA: Accelerating Diffusion-Based Text-to-Audio Generation with Consistency Distillation
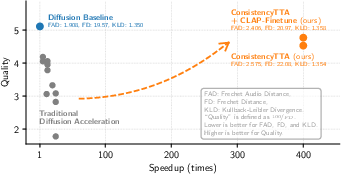
Abstract: Diffusion models are instrumental in text-to-audio (TTA) generation. Unfortunately, they suffer from slow inference due to an excessive number of queries to the underlying denoising network per generation. To address this bottleneck, we introduce ConsistencyTTA, a framework requiring only a single non-autoregressive network query, thereby accelerating TTA by hundreds of times. We achieve so by proposing "CFG-aware latent consistency model," which adapts consistency generation into a latent space and incorporates classifier-free guidance (CFG) into model training. Moreover, unlike diffusion models, ConsistencyTTA can be finetuned closed-loop with audio-space text-aware metrics, such as CLAP score, to further enhance the generations. Our objective and subjective evaluation on the AudioCaps dataset shows that compared to diffusion-based counterparts, ConsistencyTTA reduces inference computation by 400x while retaining generation quality and diversity.
- “Text-to-audio generation using instruction-tuned llm and latent diffusion model,” arXiv preprint arXiv:2304.13731, 2023.
- “Diffsound: Discrete diffusion model for text-to-sound generation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023.
- “AudioLDM: Text-to-audio generation with latent diffusion models,” arXiv preprint arXiv:2301.12503, 2023.
- “AudioLDM 2: Learning holistic audio generation with self-supervised pretraining,” arXiv preprint arXiv:2308.05734, 2023.
- “Make-an-Audio: Text-to-audio generation with prompt-enhanced diffusion models,” arXiv preprint arXiv:2301.12661, 2023.
- “Make-an-Audio 2: Temporal-enhanced text-to-audio generation,” arXiv preprint arXiv:2305.18474, 2023.
- “Any-to-any generation via composable diffusion,” arXiv preprint arXiv:2305.11846, 2023.
- “AudioGen: Textually guided audio generation,” in International Conference on Learning Representations, 2023.
- “Riffusion - stable diffusion for real-time music generation,” URL https://riffusion.com, 2022.
- “High-resolution image synthesis with latent diffusion models,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
- “Consistency models,” in International Conference on Machine Learning, 2023.
- “Classifier-free diffusion guidance,” in NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021.
- “Deep unsupervised learning using nonequilibrium thermodynamics,” in International Conference on Machine Learning, 2015.
- “Denoising diffusion probabilistic models,” in Advances in Neural Information Processing Systems, 2020.
- “Elucidating the design space of diffusion-based generative models,” in Advances in Neural Information Processing Systems, 2022.
- “Noise2Music: Text-conditioned music generation with diffusion models,” arXiv preprint arXiv:2302.03917, 2023.
- “U-Net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention, 2015.
- “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020.
- Leonhard Euler, Institutionum calculi integralis, vol. 1, impensis Academiae imperialis scientiarum, 1824.
- “DPM-solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps,” in Advances in Neural Information Processing Systems, 2022.
- “DPM-solver++: Fast solver for guided sampling of diffusion probabilistic models,” arXiv preprint arXiv:2211.01095, 2022.
- “Pseudo numerical methods for diffusion models on manifolds,” in International Conference on Learning Representations, 2022.
- “Progressive distillation for fast sampling of diffusion models,” in International Conference on Learning Representations, 2021.
- “On distillation of guided diffusion models,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023.
- “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,” in Advances in Neural Information Processing Systems, 2020.
- “Efficient diffusion training via min-snr weighting strategy,” arXiv preprint arXiv:2303.09556, 2023.
- “CLAP: learning audio concepts from natural language supervision,” in IEEE International Conference on Acoustics, Speech and Signal Processing, 2023.
- “AudioCaps: Generating captions for audios in the wild,” in Conference of the North American Chapter of the Association for Computational Linguistics, 2019.
- “Scaling instruction-finetuned language models,” arXiv preprint arXiv:2210.11416, 2022.
- “CNN architectures for large-scale audio classification,” in IEEE International Conference on Acoustics, Speech and Signal Processing, 2017.
- “PANNs: Large-scale pretrained audio neural networks for audio pattern recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020.
- “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” in IEEE International Conference on Acoustics, Speech and Signal Processing, 2023.
- “Audio set: An ontology and human-labeled dataset for audio events,” in IEEE International Conference on Acoustics, Speech and Signal Processing, 2017.
- Brian McFee, “ResamPy: efficient sample rate conversion in python,” Journal of Open Source Software, vol. 1, no. 8, pp. 125, 2016.
- “TorchAudio: Building blocks for audio and speech processing,” arXiv preprint arXiv:2110.15018, 2021.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

