- The paper demonstrates that GPT-4 evaluators consistently score high, especially in low-resource languages, highlighting a bias that requires careful calibration.
- It compares single-call prompting and compound-call prompting approaches, finding that single-call prompting aligns more closely with human evaluations.
- The study provides a framework for mitigating biases in multilingual evaluation, emphasizing the importance of native speaker judgments for reliable assessments.
Scaling Multilingual Evaluation with LLM-based Evaluators
The paper "Are LLM-based Evaluators the Solution to Scaling Up Multilingual Evaluation?" (2309.07462) investigates the potential of using LLMs, specifically GPT-4, as evaluators for multilingual text generation tasks. It addresses the challenges of scaling multilingual evaluation due to the limitations of existing benchmarks, metrics, and the difficulty of obtaining human annotations in diverse languages. The study calibrates GPT-4 based evaluators against a dataset of 20K human judgments across three text-generation tasks, five metrics, and eight languages, revealing biases and offering recommendations for future work.
Experimental Design
The research utilizes three text generation tasks: Open Prompt, Continue Writing, and Summarize. These tasks are evaluated across eight languages: English, French, German, Spanish, Chinese, Japanese, Italian, Brazilian Portuguese, and Czech, representing varying resource levels and script types. The evaluation considers five dimensions: Linguistic Acceptability (LA), Output Content Quality (OCQ), Task Quality (TQ), Problematic Content (PC), and Hallucinations (H). Human evaluation is conducted using native speakers, and their judgments are compared against those of GPT-4. (Figure 1) shows the pipeline of experiments, including generation, evaluation and calibration.
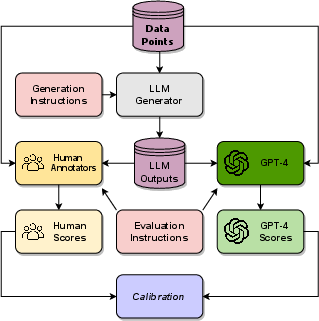
Figure 1: Pipeline of our experiments involving generation, evaluation, and calibration.
Key Findings and Analysis
The study reveals a significant bias in GPT-4 based evaluators towards higher scores, particularly in lower-resource languages and non-Latin script languages. This bias underscores the need for calibration with native speaker judgments to ensure accurate evaluation of LLM performance across diverse languages. The paper explores various prompting strategies, including single-call (evaluating one metric at a time) and compound-call (evaluating all metrics in a single prompt) approaches. Single-call prompting demonstrates better agreement with human annotators compared to compound-call prompting. Detailed instructions did not eliminate the bias toward high scores.
Inter-annotator agreement (IAA) is measured using Percentage Agreement (PA) and Fleiss' Kappa (κ). The IAA between human annotators is generally high, but the agreement between human annotators and GPT-4 is lower, especially for Japanese and Czech. The class distribution analysis indicates that GPT-4 tends to assign a score of 2 (the highest score) in most cases, even when human annotators disagree. (Figure 2) shows PA by language for the full dataset.
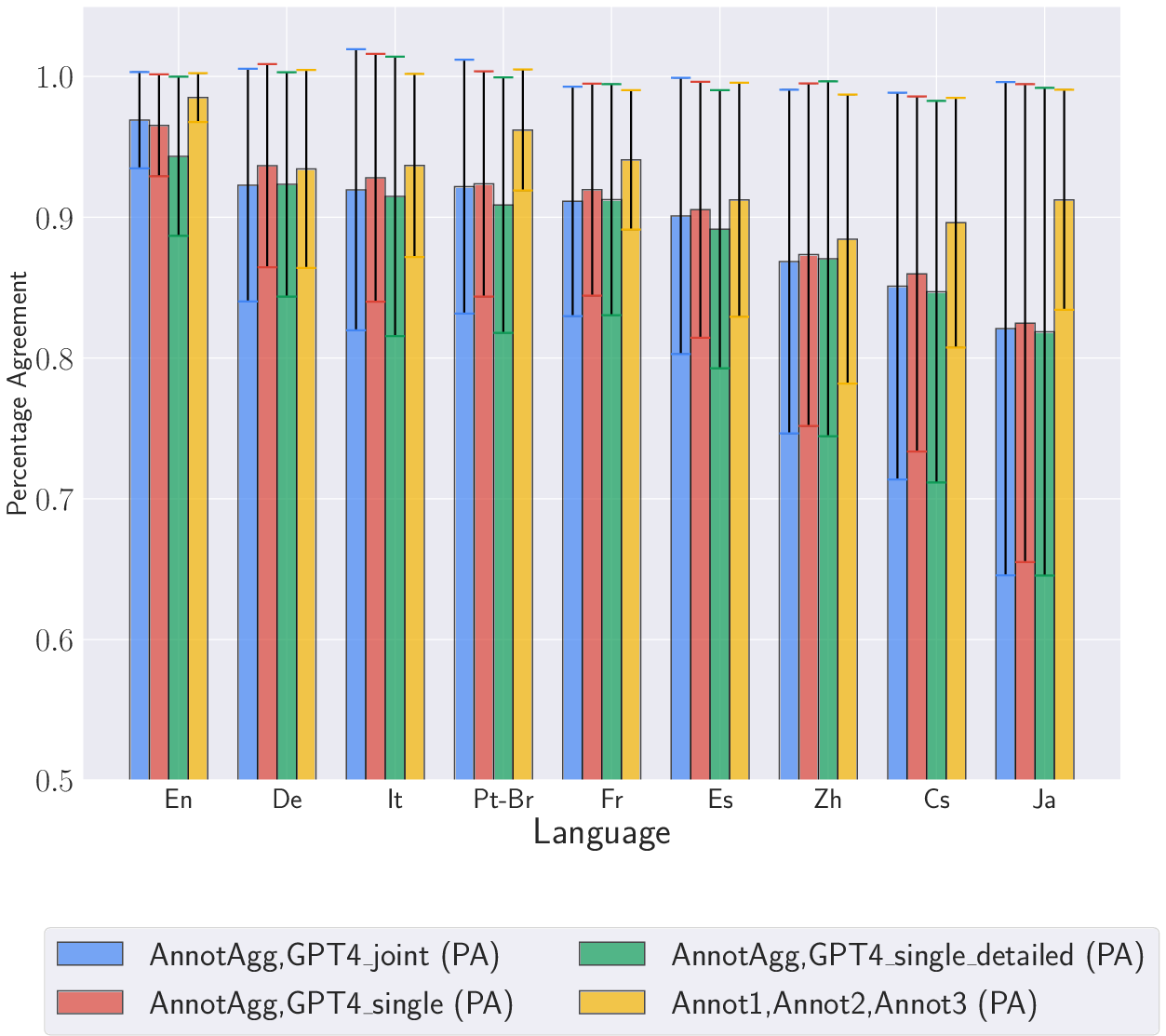
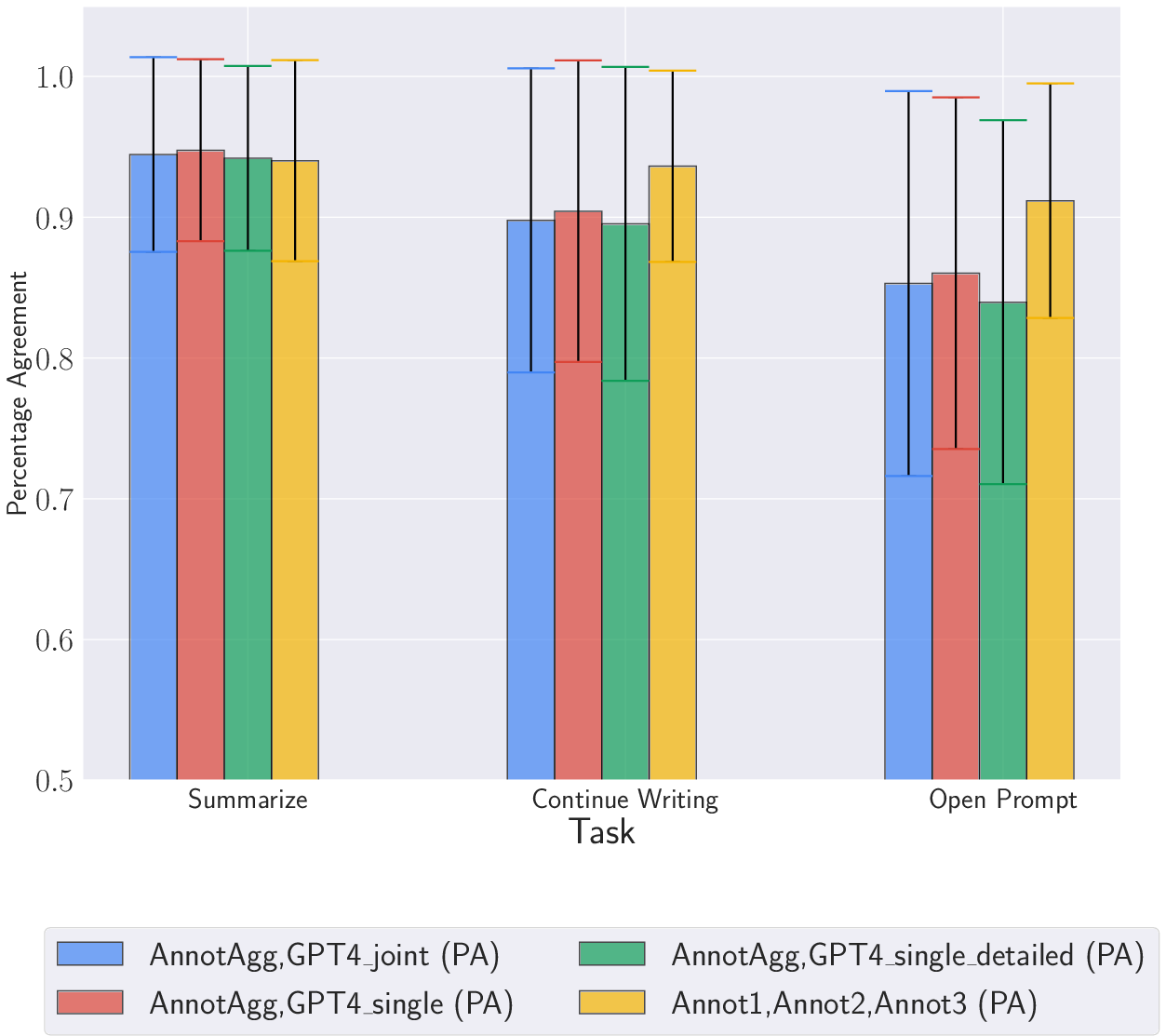
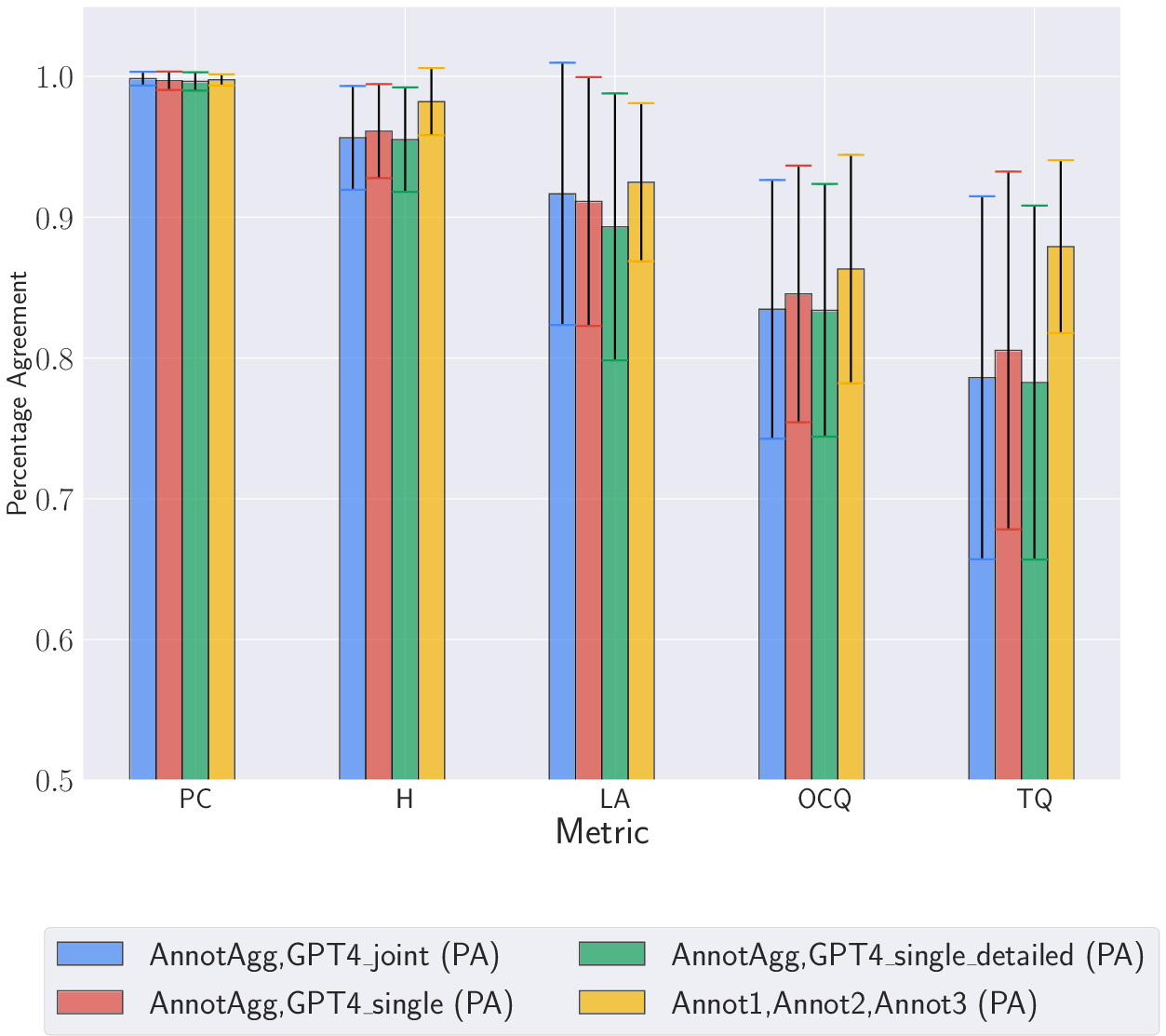
Figure 2: PA by language: Full dataset
Implications and Future Directions
The findings suggest that while LLMs hold promise as multilingual evaluators, they cannot replace human evaluation, especially in languages beyond the high-resource set. LLM-based evaluations should be calibrated with human-labeled judgments in each language before deployment. The study highlights the importance of considering linguistic acceptability, task accomplishment, and safety in multilingual evaluation.
Future research directions include:
- Exploring the use of smaller models for evaluation or models trained with better coverage of non-English data.
- Prompt engineering and automatic prompt tuning.
- Creating balanced datasets with good language coverage and multiple annotators per data point.
- Developing evaluator personas to represent diverse perspectives of human evaluators.
Sensitivity Analysis and Ablation Experiments
Sensitivity analysis, involving the perturbation of word order in sentences, reveals that the LLM-based evaluator is sensitive to input variations, particularly for the Summarization task. However, Chinese and Japanese show less sensitivity, potentially due to their flexible word order. Ablation experiments, including consistency checks, few-shot prompting, and temperature variation, provide additional insights. Consistency checks show high consistency, while few-shot prompting does not significantly improve performance. Temperature variation indicates that a temperature of 0 should be used for LLM-based evaluators.
Conclusion
The paper makes a strong case that while LLMs like GPT-4 can assist in multilingual evaluation, they exhibit biases that necessitate careful calibration with human judgments. The study offers valuable insights into the challenges and opportunities of using LLMs for multilingual evaluation, providing a framework for future research and development in this area. The results of the study call for a cautious approach when using LLM-based evaluators for non-English languages.