- The paper presents a comprehensive NL2SQL pipeline incorporating data collection, model training, and automated deployment to convert natural language queries to SQL in low-code platforms.
- It utilizes a T5-based generator paired with a CodeBERT ranker and constrained decoding to ensure valid SQL generation and superior performance metrics.
- Experimental results demonstrate significant improvements with a 240% boost in adoption, 220% increased engagement, and a 90% drop in failure rates compared to baseline models.
The paper "Natural language to SQL in low-code platforms" (2308.15239) introduces a comprehensive pipeline for converting NL queries into SQL queries within low-code platforms, addressing the challenges faced by developers with limited SQL expertise. The pipeline encompasses data collection, model training, and deployment, incorporating a feedback loop for continuous improvement. The solution leverages crowdsourcing and production data to train a T5-based model with constrained decoding, enhancing adoption, engagement, and reducing failure rates compared to baseline models.
Methodological Pipeline
The pipeline consists of three primary components: data collection, model training, and model deployment (Figure 1).
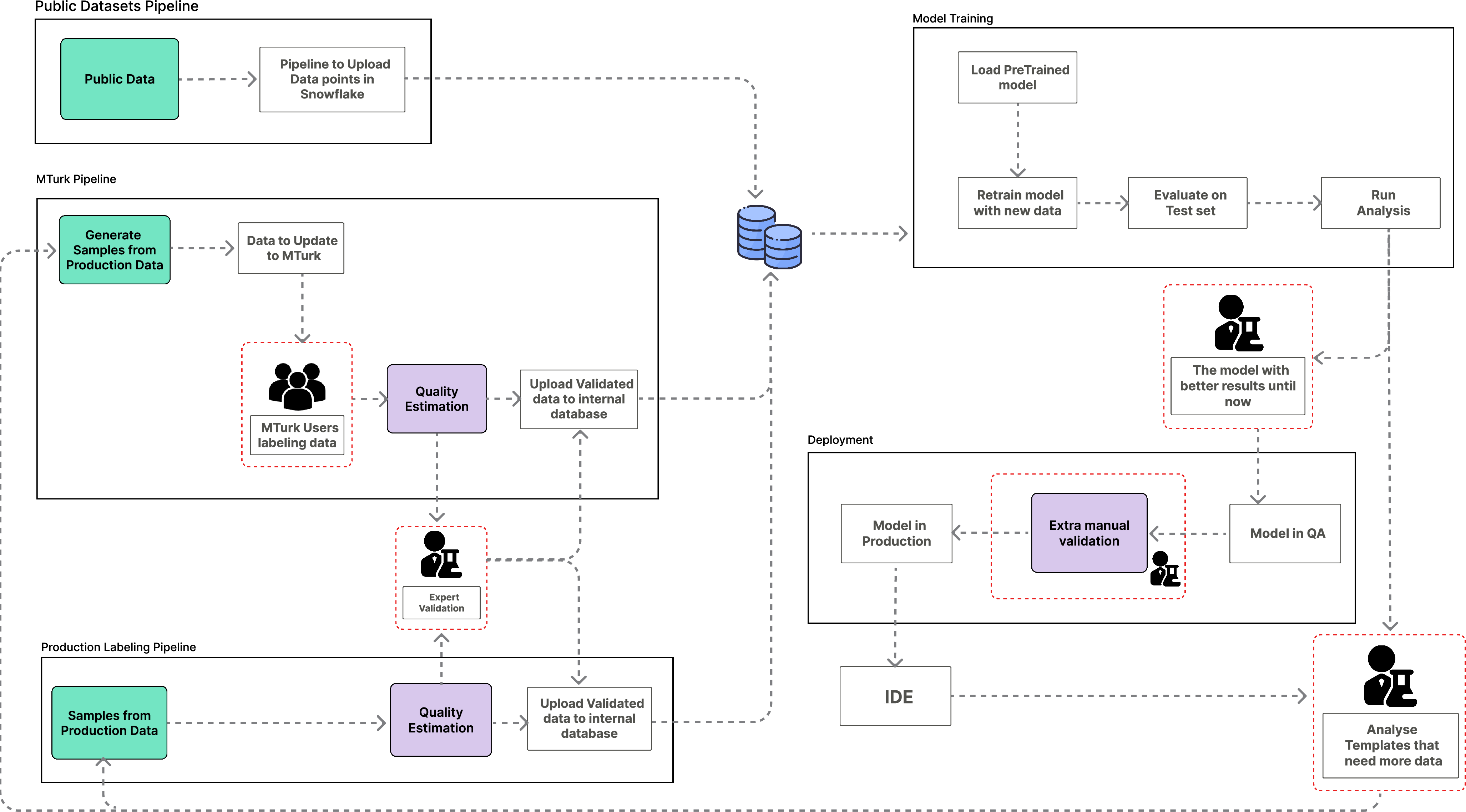
Figure 1: Machine Learning pipeline that comprises the three main components, data collections (on the left), model training (top right corner), and model deployment (bottom right corner).
Data Collection
Data collection involves three sources: public datasets (Spider), crowdsourced labeled data (MTurk), and production data. Public datasets like Spider are used as a starting point but are augmented with MTurk data to better reflect real-world scenarios. MTurk is employed to label SQL queries with corresponding NL utterances, ensuring a representative set of examples that mimic users' SQL usage distribution. Production data is gathered to analyze model performance and collect SQL queries edited by users, further refining the training data.
Quality Estimation
To ensure the quality of the data, a quality estimation system is implemented. This system filters out incorrect pairs of SQL queries and utterances using both rule-based systems and an ML-based estimator. The ML-based estimator, fine-tuned with CodeBERT, detects whether a SQL query matches an utterance, improving the accuracy of the training data.
SQL Generation
SQL generation is achieved using T5QL, a Seq2Seq method that converts NL queries into SQL queries (Figure 2). T5QL comprises a generator (T5 model) and a ranker (CodeBERT model). The generator is trained to output SQL queries corresponding to the input sequence, while the ranker re-ranks the generator's candidates to improve performance. Constrained decoding, using a CFG of SQL statements, ensures that only valid SQL is generated.
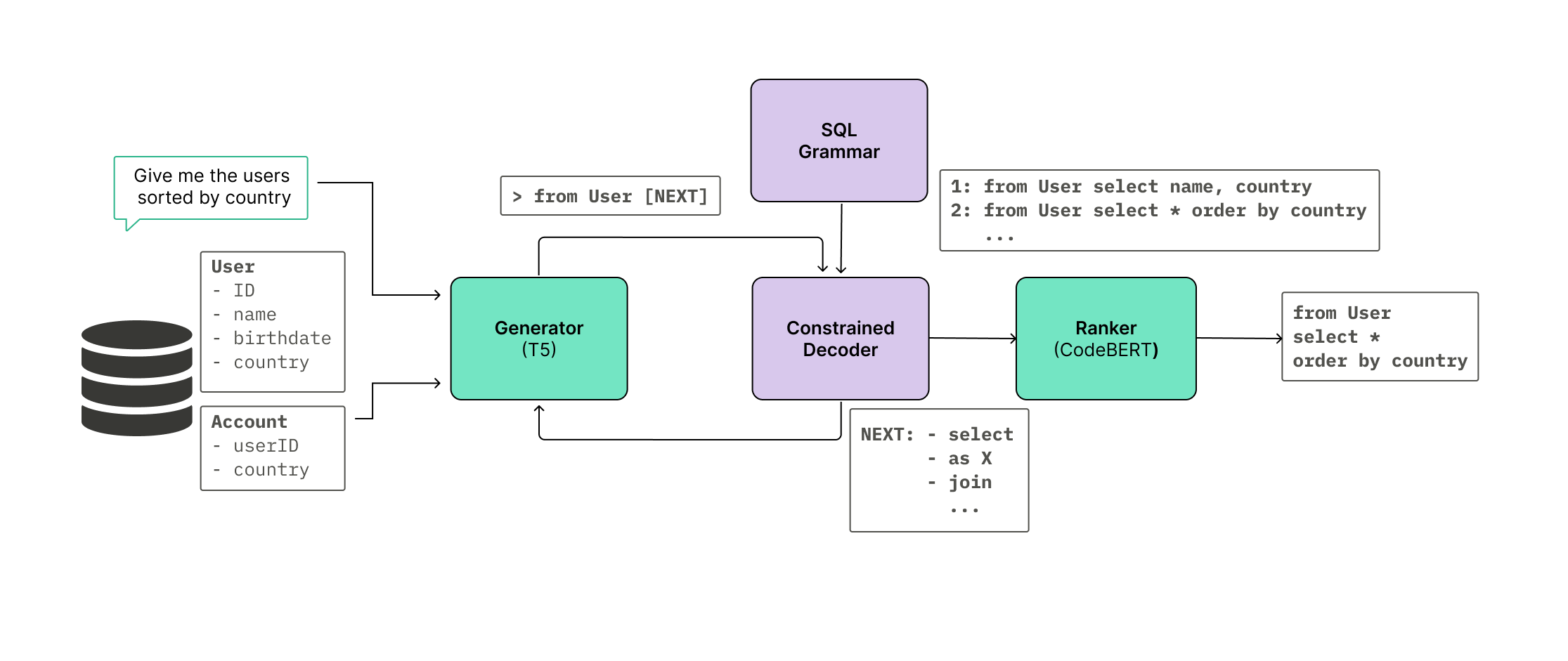
Figure 2: T5QL model architecture (from \citet{arcadinho2022t5ql}).
Model Training
The model is retrained iteratively, incorporating new data points from SQL templates where the model performed poorly. Active learning, using clustering on the predicted SQL template, guides the selection of data to improve the model's performance. Model performance is evaluated using exact match, execution match, and TED between the ASTs of gold and predicted SQL queries. Server performance is also monitored to ensure minimal impact on response time.
Deployment
Model deployment is automated using a GitOps-based CI/CD approach. The service is containerized and runs in a Kubernetes infrastructure. Deployment strategies include rolling updates, progressive rollouts, and A/B testing, ensuring minimal downtime and allowing for thorough evaluation of new models in production.
Feedback Loop
A feedback loop is established to continuously improve the model. User feedback, collected through product telemetry data, is used to identify areas for improvement and retrain the model. This loop creates a virtuous cycle, where better models lead to increased usage and more feedback.
Experimental Results
The paper presents both offline and online experiments to evaluate the effectiveness of the proposed pipeline. Offline experiments on an internal test set demonstrated significant improvements using T5QL with constrained decoding and FP16 precision. The maximum input size was increased, and response times were reduced while maintaining a low TED. Online experiments, conducted through A/B testing, showed a 240% increase in adoption, a 220% increase in engagement rate, and a 90% reduction in failure rate compared to the baseline model (RATSQL).
The paper references several key works in the areas of A/B testing and NL2SQL. A/B testing has been widely used for website development and is increasingly being applied to ML model deployment. NL2SQL research has explored various approaches, including enhancing schema representation, generating code from fragments, and using intermediate representations with relation-aware self-attention. Constrained decoding with LLMs has also been shown to improve accuracy by reducing hallucinations.
Conclusion
The work presents a comprehensive NL2SQL pipeline for low-code platforms, emphasizing data-driven model training and a user-centric approach. The pipeline leverages crowdsourcing, production data, and active learning to continuously improve model performance. The experimental results demonstrate significant improvements in adoption, engagement, and failure rates, highlighting the effectiveness of the proposed approach. Future work involves exploring model shadowing to estimate model performance without premature deployment.

