- The paper introduces GR-T, a backpropagation-free approach using forward gradients to reduce the memory and computational burdens of LLM training.
- It integrates parameter-efficient techniques like LoRa and Adapter, achieving up to 132.7x faster convergence on resource-limited devices.
- GR-T employs adaptive perturbation pacing and discriminative sampling to optimize gradient updates in federated learning scenarios.
Efficient FedLLM Using Forward Gradient
Introduction and Motivation
The paper "FwdLLM: Efficient FedLLM using Forward Gradient" introduces GR-T, an innovative approach to Federated Learning (FL) designed to enhance the fine-tuning efficiency of LLMs on resource-constrained mobile devices. Traditional FL methods struggle with the high memory and computation demands of LLMs, necessitating new strategies for efficient deployment.
Challenges in Federated Learning of LLMs
One of the primary challenges in deploying LLMs through federated learning is the dichotomy between model complexity and device limitations. The paper identifies key obstacles: large memory footprint, incompatibility with mobile NPUs designed primarily for inference rather than training, and limited device scalability in federated settings. These challenges inhibit effective deployment and utilization of LLMs on consumer devices.
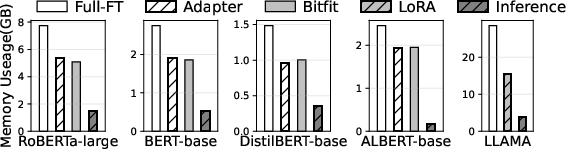
Figure 1: Peak memory footprint of different training methods and inference. Batch size: 8.
GR-T: Backpropagation-Free Training
GR-T offers an elegant solution by eliminating backpropagation in favor of a forward gradient approach, employing "perturbed inferences" to compute gradients. This methodology significantly reduces memory consumption and harnesses the processing capabilities of mobile NPUs, enabling multiple devices to contribute to the training process simultaneously, thereby improving convergence speed.
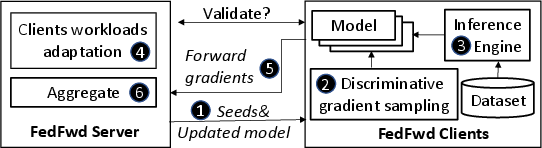
Figure 2: GR-T workflow.
Technical Design and Innovation
The paper proposes three main innovations to address specific challenges in federated LLM training:
- Parameter-Efficient Forward Gradients: By integrating parameter-efficient fine-tuning methods (e.g., LoRa, Adapter) with forward gradient techniques, GR-T reduces the number of trainable parameters, thus minimizing resource demands while maintaining model adaptability.
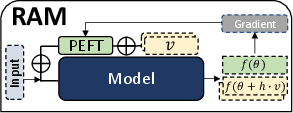
Figure 3: GR-T is memory-efficient. Dotted block will be released sequentially after computation.
- Adaptive Strategy for Perturbation Pacing: GR-T introduces a variance-controlled mechanism to automatically adjust the number of perturbations per round, optimizing the trade-off between computational cost and model convergence speed.
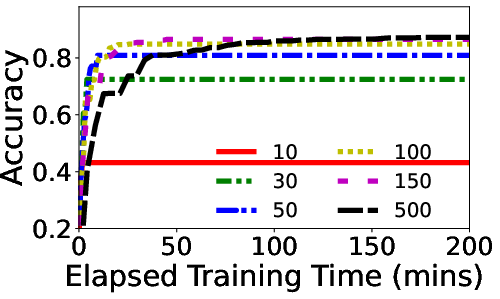
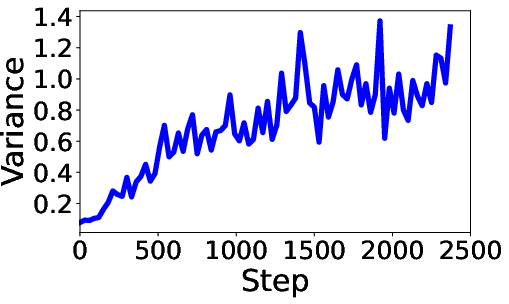
Figure 4: Optimal Global-PS varies across training.
- Discriminative Perturbation Sampling: Instead of random sampling, GR-T employs a discriminative approach to identify perturbations that contribute significantly to gradient updates, thereby enhancing convergence and reducing computation.
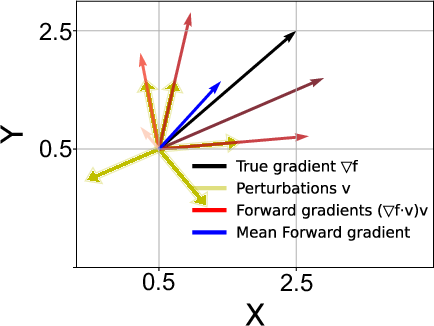
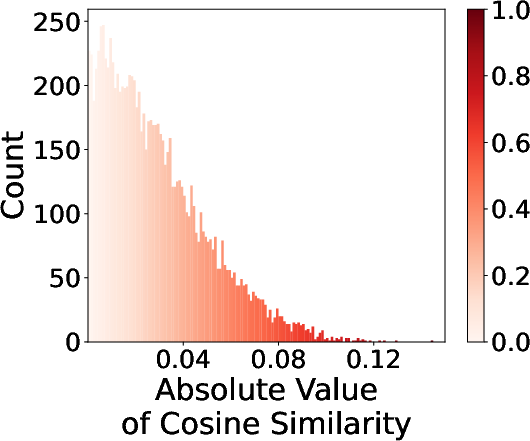
Figure 5: Most of the gradients are nearly orthogonal to target gradients thus contributing little.
In rigorous evaluations involving models like ALBERT, BERT, and LLaMA, GR-T demonstrated impressive improvements in training efficiency and scalability. It consistently outperformed traditional backpropagation-based methods, achieving up to 132.7x faster convergence and drastic reductions in memory and energy costs.

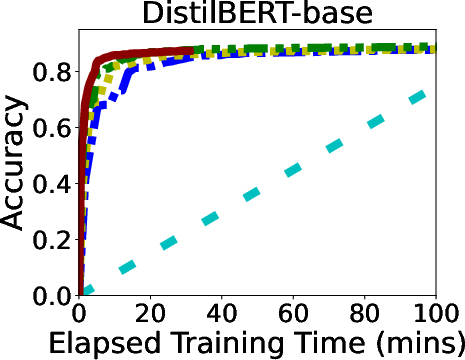
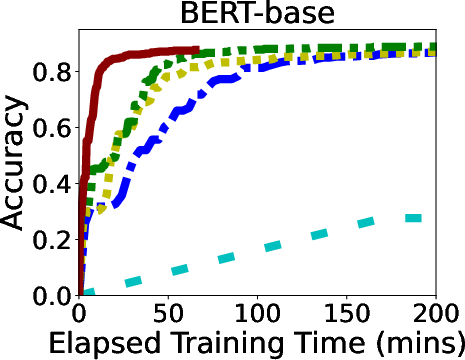
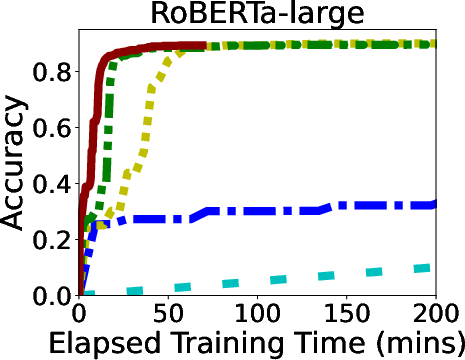
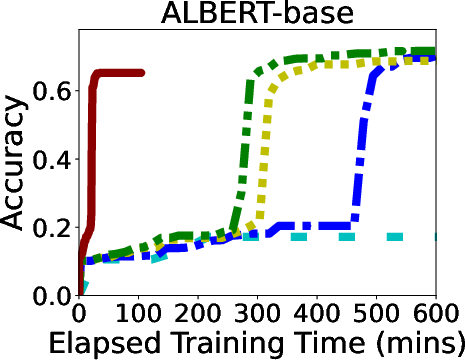
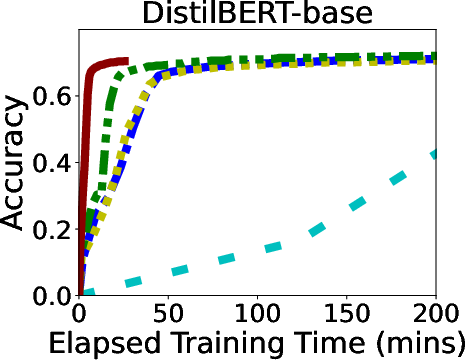
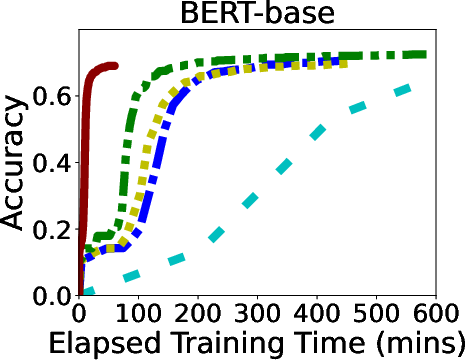
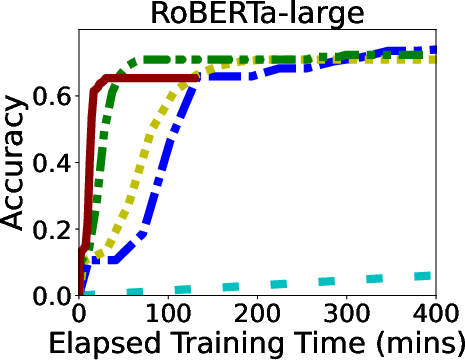
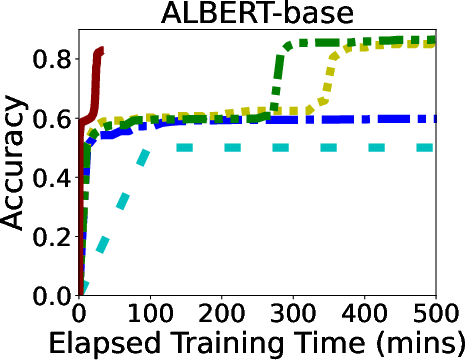
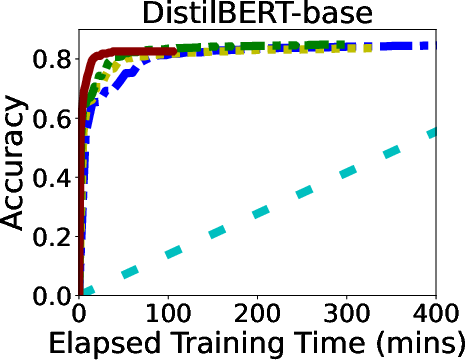
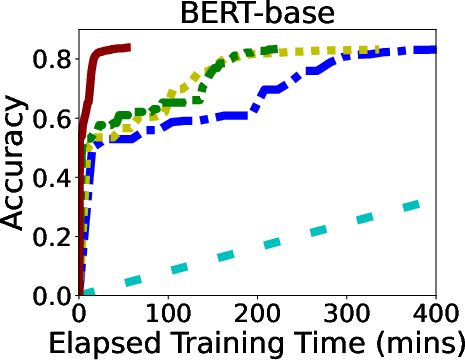
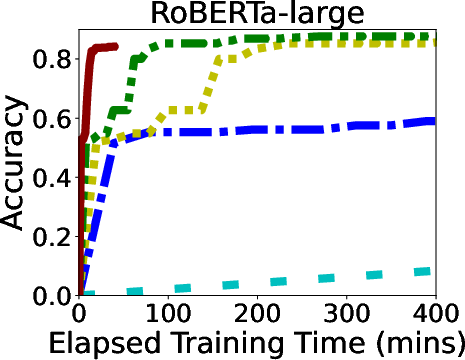
Figure 6: Overall Performance of GR-T and baselines. Processor: NPU for GR-T and CPU for others.
GR-T's scalability is evidenced by its ability to effectively utilize a large number of clients, achieving substantial improvements in non-iid data distribution scenarios, which underscores its robustness in real-world applications.
Conclusion
The introduction of GR-T establishes a new paradigm in federated learning for LLMs by leveraging backpropagation-free training methods. This approach not only addresses the significant barriers of memory and computation but also demonstrates adaptability and efficiency through novel variance-controlled and discriminative techniques. Future work could explore further enhancements and broader applications of GR-T in diverse settings within AI.

