- The paper introduces a unified diffusion-based framework that controls foreground illumination and pose using a novel 2D indicator vector.
- The methodology employs a hierarchical encoder and a two-stage fusion mechanism to integrate global semantic and local detailed features for robust compositing.
- Experimental results on COCOEE and FOSCom benchmarks demonstrate state-of-the-art quality with improved foreground fidelity and explicit attribute controllability.
Introduction and Motivation
The problem of image composition, i.e., synthesizing a realistic composite image from a provided foreground and background, poses significant technical challenges arising from discrepancies in illumination, pose, and boundary integration. Traditional modular approaches treat sub-problems such as image blending, harmonization, and view synthesis with separate models, requiring sequential application and leading to inefficiencies and limited practical applicability. Previous diffusion-based generative composition methods unify these tasks, but they lack fine-grained controllability over foreground attributes and often fail to robustly preserve instance identity and localized visual details.
ControlCom introduces a unified diffusion-based framework that enables fine-grained, user-controllable adjustment over key foreground attributes—specifically illumination and pose—via a novel 2D indicator vector. The model is trained in a self-supervised multi-task regime to simultaneously handle blending, harmonization, view synthesis, and generative composition. A two-stage fusion mechanism (global then local) conditions the diffusion process on hierarchical foreground representations, yielding improved fidelity in complex compositing scenarios.
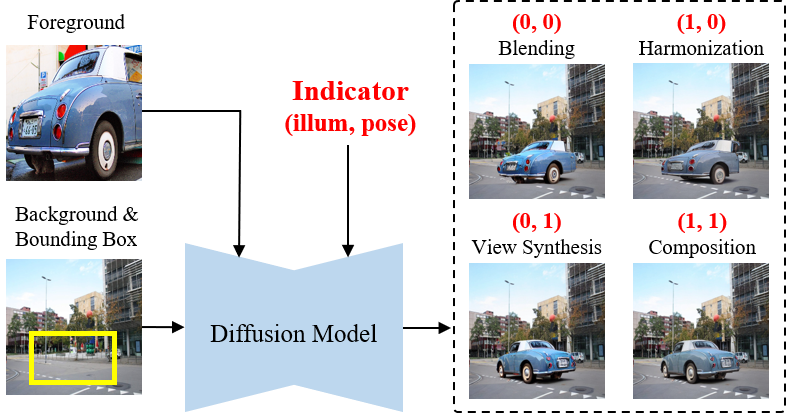
Figure 1: Overview of the ControlCom framework unifying four compositing tasks through a single model with control over foreground illumination and pose via a 2-dimensional indicator.
Methodology
Architecture
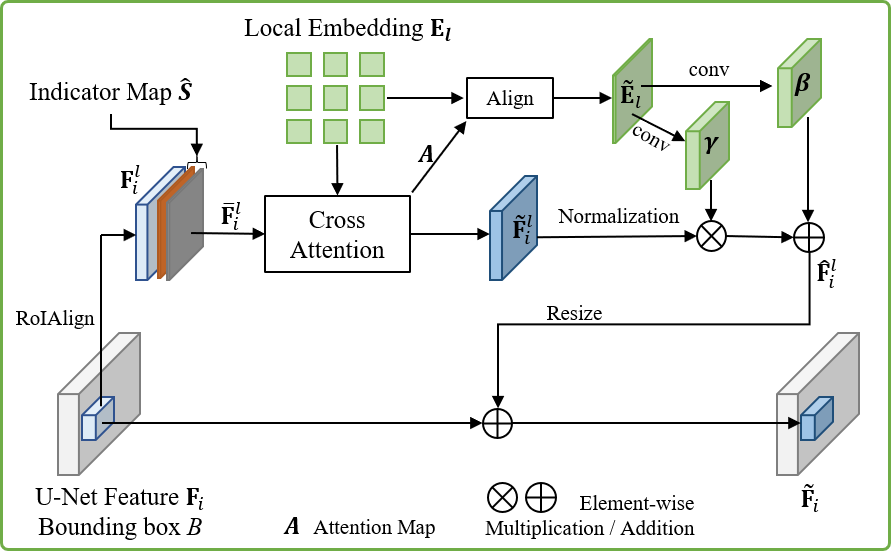
The ControlCom architecture consists of two principal components: a hierarchical foreground encoder and a controllable generator implemented as a conditional latent diffusion model. The encoder extracts both a global embedding (high-level semantic vector) and local embeddings (patch-level features) from the input foreground image via a CLIP ViT-L/14 backbone. These hierarchical representations are uniquely fused into the diffusion process in two stages, forming the basis for high-fidelity, attribute-controllable synthesis.
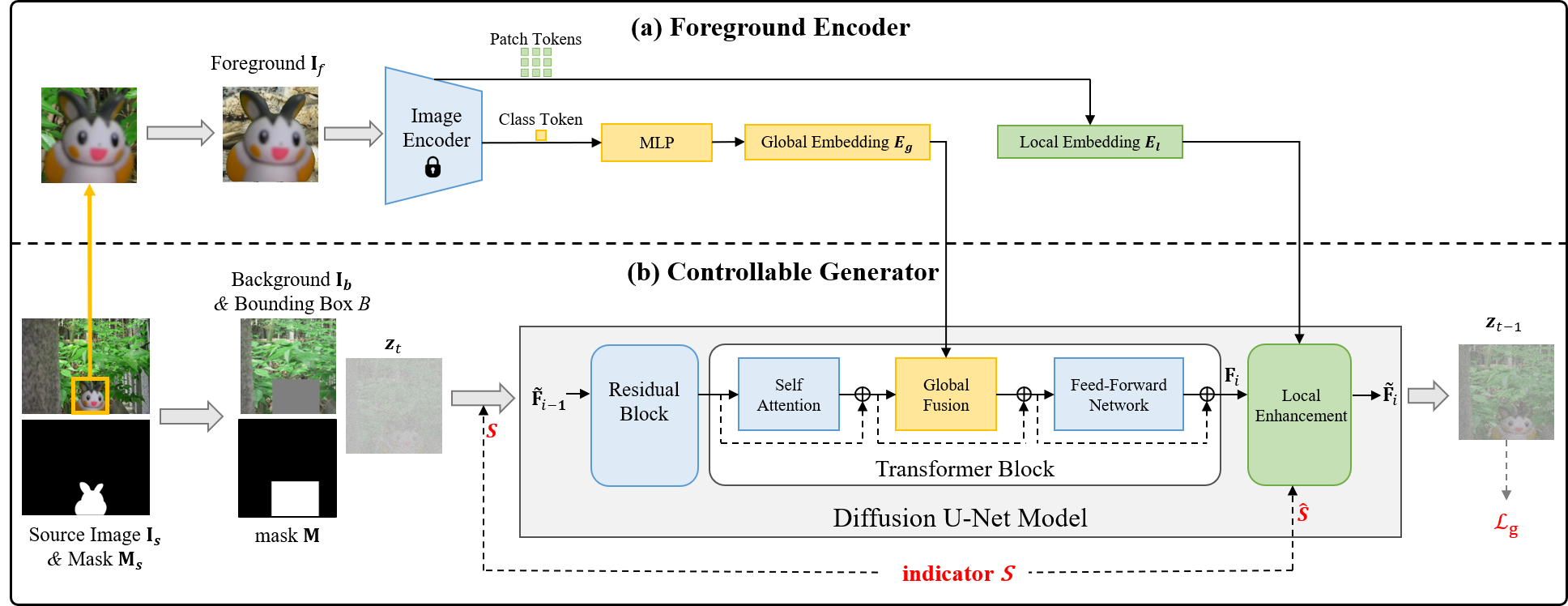
Figure 2: ControlCom architecture with (a) a hierarchical foreground encoder for global and local features, and (b) a controllable generator incorporating indicator-based conditioning.
Control Mechanism
User control over foreground illumination and pose is exposed through a binary 2D indicator vector S (first dimension: illumination, second: pose). Each indicator bit signals whether the corresponding attribute should be modified ($1$) or preserved ($0$). This enables the model to perform:
- Image blending (S=(0,0))
- Image harmonization (S=(1,0))
- View synthesis (S=(0,1))
- Generative composition (S=(1,1))
Conditioning and Fusion
Self-supervised Data Pipeline
A comprehensive synthetic data pipeline is established to enable supervised training across all tasks using large-scale image collections (Open Images). This involves extracting objects, applying attribute-specific augmentations (illumination, geometric), and recomposing foregrounds onto backgrounds. This pipeline generates pseudo ground-truth identifiers and composite images for all task variants, with precise assignment of the control vector for each instance.

Figure 4: Flowchart of synthetic training data creation with background, foreground, and task-specific augmentation for multi-task supervision.
Experimental Validation
Datasets and Metrics
- COCOEE: A public benchmark providing 3,500 background/foreground pairs for compositing.
- FOSCom: Introduced for this work to provide realistic background-foreground pairs (640 samples) with manual bounding boxes in natural open areas.
Performance is evaluated along:
- Foreground fidelity (CLIP score)
- Background preservation (SSIM, LPIPS)
- Authenticity and generative quality (FID, Quality Score/QS)
Comparative Results
ControlCom demonstrates strong numerical gains:
- Highest overall Quality Score on COCOEE ($77.84$)
- Substantial CLIP foreground similarity across tasks ($90.63$ for blending/harmonization)
- Competitive FID to existing SoTA diffusion-based approaches
ControlCom is distinguished by superior controllability of foreground attributes and consistency across both synthetic (COCOEE) and real-world (FOSCom) scenarios.

Figure 5: Side-by-side qualitative results on COCOEE and FOSCom, highlighting ControlCom’s superior visual realism and foreground preservation compared to prior baselines.
Task-specific Analysis
Visualization of indicator-based control confirms robust, independent manipulation of illumination and pose. Qualitative examples illustrate seamless attribute preservation or modification according to S, with realistic boundary blending and minimal artifact formation. User studies (provided in supplementary material) further support the practical utility of fine-grained control.
Theoretical and Practical Implications
From a theoretical perspective, ControlCom advances conditional generation by demonstrating hierarchical semantic-appearance fusion and parallelization of multiple, traditionally sequential, image manipulation tasks within a single generative model. The controllable generator structure, particularly the indicator-conditioning and local enhancement, sets a precedent for further research in explicit attribute disentanglement in diffusion models.
Practically, ControlCom enables more flexible and user-driven image editing pipelines, facilitating applications in creative design, visual effects, and content generation with minimal manual intervention. The generalizable self-supervised data strategy lowers annotation costs and extends to compositional tasks with different foreground/background domains.
Future Directions
Several avenues for future research arise:
- Extending the attribute control interface (e.g., continuous-valued or multi-attribute indicators)
- Generalizing to multi-object and layered compositing scenarios
- Improving robustness to real-world distributional shifts or occlusions
- Applying the hierarchical fusion paradigm to text-guided or multi-modal compositional synthesis
- Investigating theoretical bounds of fidelity and controllability under self-supervised data generation
Conclusion
ControlCom presents a substantial methodological advance for controllable, high-fidelity image composition using diffusion models. By unifying four key composition tasks and introducing a succinct, yet flexible, indicator-controlled interface, the approach achieves state-of-the-art performance in both quantitative and qualitative evaluations. Its two-stage foreground conditioning and self-supervised multi-task training pipeline represent significant innovations with broad applicability in vision systems that require precise, user-driven content integration.