- The paper introduces Reinforcement Learning from Evol-Instruct Feedback (RLEIF), combining supervised fine-tuning, reward models, and PPO to enhance LLM mathematical reasoning.
- It demonstrates significant performance gains with a +24.8 improvement on GSM8k and +9.2 on MATH, outperforming several state-of-the-art models.
- The study presents a scalable framework that blends instruction-based reward models with reinforcement learning to advance AI-driven problem-solving capabilities.
WizardMath: Empowering Mathematical Reasoning for LLMs via Reinforced Evol-Instruct
Introduction
The paper "WizardMath: Empowering Mathematical Reasoning for LLMs via Reinforced Evol-Instruct" presents an innovative approach to enhancing the mathematical reasoning capabilities of LLMs such as Llama-2. The method, Reinforcement Learning from Evol-Instruct Feedback (RLEIF), integrates reinforcement learning with novel instructional strategies to augment LLMs with advanced mathematical reasoning skills. This approach focuses on optimizing mathematical reasoning through specialized instruction and reinforcement mechanisms, achieving significant performance improvements over existing models.
Methodology
The RLEIF methodology involves three key phases: Supervised Fine-Tuning (SFT), Instruction Reward Model (IRM) and Process-supervised Reward Model (PRM) training, and reinforcement learning using Proximal Policy Optimization (PPO). These steps are designed to refine the model's understanding and processing of mathematical instructions, thereby boosting its reasoning capabilities.
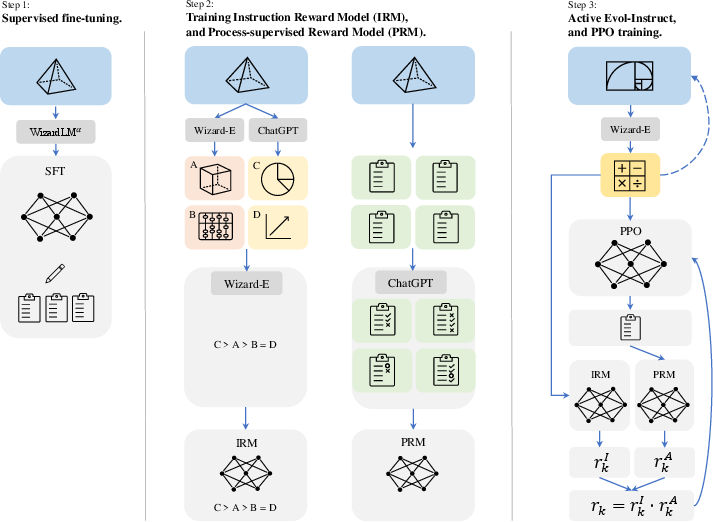
Figure 1: A diagram illustrating the three steps of our Reinforcement Learning from Evol-Instruct Feedback (RLEIF): (1) supervised fine-tuning (SFT), (2) Instruction Reward Model (IRM) training and Process-supervised Reward Model (PRM) training, and (3) Active Evol-Instruct and reinforcement learning via proximal policy optimization (PPO).
Supervised Fine-Tuning
The initial phase involves fine-tuning the base LLM with supervised instruction-response pairs. This step enhances the model's ability to process complex mathematical instructions and provides a robust baseline for subsequent reinforcement learning phases.
Instruction and Process-supervised Reward Models
The IRM and PRM are trained to evaluate the quality of mathematical instructions and the correctness of step-by-step reasoning processes, respectively. This dual model approach allows the system to internally assess and improve its instruction-following and reasoning processes, akin to feedback loops that refine the model's outputs over time.
Reinforcement Learning via PPO
The final step employs PPO to iteratively improve the model's performance. This approach leverages both instruction and process supervision to guide the reinforcement learning phase, ensuring that the model learns to apply mathematical reasoning effectively and robustly.
Results
WizardMath demonstrated superior performance on established mathematical benchmarks such as GSM8k and MATH, outstripping all other open-source LLMs and even certain closed-source models like ChatGPT-3.5.
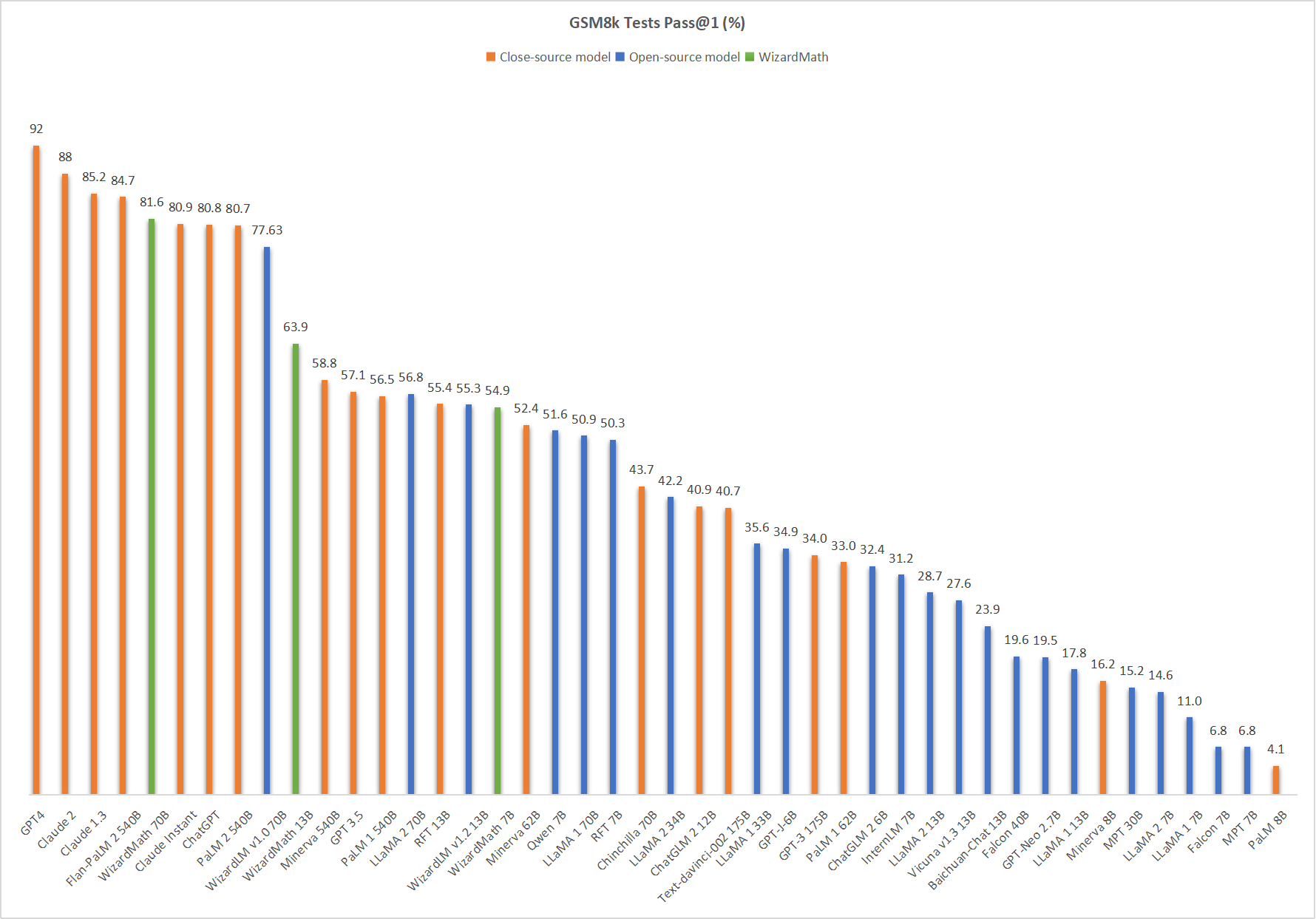
Figure 2: The pass@1 performance of main LLM models on the GSM8k benchmark, our model is currently ranked in the top five, slightly outperforming some close-source models such as ChatGPT-3.5.
The model achieved a pass@1 improvement of +24.8 on GSM8k (81.6 vs. 56.8) and +9.2 on MATH (22.7 vs. 13.5), demonstrating its enhanced capacity for mathematical reasoning and instruction following.
Discussion
The WizardMath framework represents a significant advancement in the field of mathematical reasoning within LLMs. By combining instruction-based reward models with reinforcement learning, WizardMath not only improves the immediate capability of LLMs to solve mathematical problems but also sets a precedent for integrating enhanced reasoning processes in AI models. This approach offers a scalable solution for developing even more advanced reasoning capabilities in future AI systems.
Conclusion
WizardMath advances the frontier of LLM capabilities by integrating innovative instructional methodologies and reinforcement learning frameworks, achieving a substantial leap in mathematical reasoning performance. This work highlights the potential of combining instruction and reinforcement learning techniques, paving the way for future advancements in AI-driven reasoning and problem-solving capabilities.
In future work, the development of more sophisticated reward models and instruction sets could further refine LLMs' capabilities, making them even more adept at tackling complex mathematical and logical challenges. The broader implications of this research suggest exciting possibilities for the future of AI in education, research, and beyond.