- The paper's main contribution is the development of LLM-DP, a neuro-symbolic framework that combines LLM-generated predicates with symbolic planners to address dynamic planning challenges in embodied environments.
- The paper demonstrates that LLM-DP outperforms traditional methods by achieving a 96% success rate and reducing average episode length to 13.16 actions.
- The paper's methodology integrates natural language goal generation with PDDL-based symbolic planning, offering practical insights for adaptive and efficient agent planning.
Dynamic Planning with a LLM
Introduction to LLM-DP
The paper presents the LLM Dynamic Planner (LLM-DP), a neuro-symbolic framework that integrates LLMs and traditional symbolic planners to address dynamic planning tasks in embodied environments. While LLMs like GPT-4 can adeptly perform various NLP tasks, their application to embodied agents presents challenges such as hallucination and context window limitations. Conversely, symbolic planners provide optimal solutions quickly but require complete problem descriptions, restricting their practical application.
Neuro-Symbolic Integration: The LLM-DP Framework
LLM-DP leverages the strengths of LLMs in handling noisy observations and the efficiency of symbolic planners to solve complex tasks. LLM-DP applies LLM-generated predicates via semantic and pragmatic inference, enabling symbolic planning for unobserved objects.
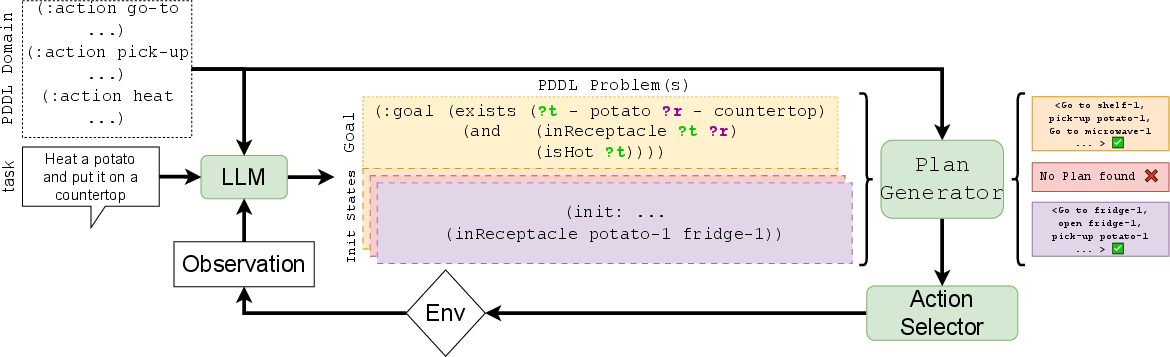
Figure 1: LLM Dynamic Planner (LLM-DP) transforms observations and linguistic instructions into PDDL, enabling symbolic planning.
The neuro-symbolic approach translates natural language task descriptions into Planning Domain Definition Language (PDDL) specifications. These specifications guide the symbolic planner to generate feasible action plans, maintaining flexibility in dynamically changing environments.
Application to Alfworld
Alfworld serves as the testbed for evaluating LLM-DP, a simulated domestic environment requiring agents to achieve specified objectives through interaction. Agents start with no object location information, demanding adaptive and strategic planning.
Key assumptions in LLM-DP include:
- Known action-descriptions and predicates.
- Perfect environmental observations.
- A causal environment driven solely by agent actions.
LLM-DP Workflow Components
- Goal Generation: The LLM produces the PDDL goal using task-specific prompts.
- Belief Sampling: Uncertain predicates are sampled to construct potential world states.
- Plan Generation: BFS(f) solver generates action plans from PDDL files.
- Action Selection: The Action Selector chooses optimal actions from feasible plans.
Algorithmically, LLM-DP continuously updates its world state and beliefs based on observed changes, embracing a closed-loop mechanism for adaptive planning.
LLM-DP significantly outperforms the ReAct approach, achieving a success rate of 96% compared to 54% with ReAct. The average episode length is reduced to 13.16 actions, denoting efficient plan execution.
LLM-DP's hybrid model offers a pragmatic balance, optimizing token usage cost and computational efficiency compared to a singular LLM model. LLM-DP proves robust in generating executable plans from linguistic goals, promoting continuous learning and environmental adaptability.
Conclusion and Future Directions
LLM-DP emerges as a competent framework combining linguistic interpretation, symbolic reasoning, and dynamic state management. It delineates a pathway for embodied agents integrating LLM capabilities with traditional planning tools.
Despite promising results, areas for future exploration include:
- Enhancing probabilistic reasoning capabilities.
- Incorporating visual data uncertainty into planning.
- Developing advanced self-reflection mechanisms for agent learning loops.
Addressing these challenges can further enhance LLM-DP's adaptability and scalability in diverse real-world scenarios, leading towards highly autonomous, learning-driven agents.

