- The paper introduces reasoning segmentation, a novel task where implicit textual queries drive the generation of segmentation masks.
- LISA leverages a specialized embedding-as-mask approach and an end-to-end training method integrating text and vision tasks.
- The model exhibits superior zero-shot performance and outperforms state-of-the-art methods on the ReasonSeg benchmark.
Detailed Essay on "LISA: Reasoning Segmentation via LLM" (2308.00692)
Introduction to Reasoning Segmentation
The paper discusses the introduction of a novel task termed 'reasoning segmentation,' which extends conventional segmentation processes by outputting a segmentation mask informed by implicit and complex reasoning queries. Unlike traditional perception systems that depend heavily on explicit user commands, reasoning segmentation aims to comprehend and reason from implicit, richly descriptive instructions, presenting significant practical implications for robotics and intelligent systems.
LISA: Design and Capabilities
Architecture of LISA
LISA, or the Language Instructed Segmentation Assistant, is designed as a multimodal LLM capable of generating segmentation masks from implicit text instructions. The architecture incorporates a specialized embedding-as-mask methodology to translate text instructions and image inputs into binary masks. A unique <SEG> token is added to the vocabulary, whose embedding is decoded into segmentation masks through a vision backbone, such as SAM or Mask2Former (Figure 1).
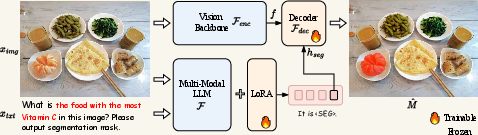
Figure 1: The pipeline of LISA. Given the input image and text query, the multimodal LLM (e.g., LLaVA) generates text output.
ReasonSeg Benchmark
To quantitatively evaluate the capability of reasoning segmentation, the authors establish the ReasonSeg benchmark comprising over a thousand image-instruction-mask samples. Importantly, these samples are derived from well-established datasets such as OpenImages and ScanNetv2, annotated with implicit reasoning tasks to challenge models (Figure 2).

Figure 2: Examples of the annotated image-instruction-mask data samples.
Training and Implementation
End-to-End Training Approach
LISA's architecture facilitates a seamless end-to-end training approach, integrating text generation and vision tasks. This is achieved through a balanced training objective combining cross-entropy loss for text and a composite loss for mask generation. The reliance on efficient fine-tuning mechanisms, such as LoRA, and the robust extraction capabilities of advanced vision backbones like ViT-H SAM, underscore the efficiency of the model, minimizing the resource-heavy requirements that plague existing large-scale polygon-based methods.
The training datasets encompass diverse inputs—semantic segmentation, referring segmentation, and VQA datasets—to support LISA's dual capacity for text and image processing. The absence of explicit reasoning data in the training phase demonstrates LISA's remarkably robust zero-shot performance in reasoning segmentation, which is further enhanced by fine-tuning with a small set of task-specific samples (Figure 3).

Figure 3: The illustration of training data formulation from different types of data, including semantic segmentation data, referring segmentation data, and VQA data.
Evaluation and Results
The results indicate a significant advantage of LISA over existing models in handling implicit and reasoning-based segmentation tasks, even surpassing previously state-of-the-art techniques such as OVSeg and X-Decoder by significant margins (Table 6). The authors highlight LISA's competency in both complex reasoning and standard referring segmentation tasks, emphasizing its potential in real-world applications (Figure 4).

Figure 4: Visual comparison among LISA and existing related methods.
Ablation Studies
The paper includes comprehensive ablation studies examining component contributions, which underscore the critical role of the specialized vision backbone and the integration of the new embedding-as-mask methodology. Pre-training on high-quality data, fine-tuning on targeted reasoning datasets, and architectural choices are proven vital in achieving optimal performance.
Conclusion
The introduction of reasoning segmentation and the development of LISA mark significant strides in bridging linguistic and visual reasoning capabilities within LLMs. This research not only advances the field of multimodal LLMs but sets a precedent for future work in embedding reasoning capabilities into AI systems, potentially inspiring advancements across diverse intelligent systems. The established ReasonSeg benchmark also provides the foundation for future studies to explore and expand reasoning capabilities in vision tasks.
Overall, LISA's design and implementation highlight the transformative promise of integrating advanced reasoning capabilities into segmentation tasks, with broad implications for AI's role in nuanced human-computer interaction contexts.

