- The paper presents a framework that formalizes and orders skills via a directed graph to improve language model training efficiency.
- It introduces the Skill-it algorithm, an online data selection method that adjusts sampling based on skill performance for various training settings.
- Experimental results on synthetic and real datasets show that leveraging skill dependencies significantly boosts training efficiency and transfers to larger models.
Skill-it! A Data-Driven Skills Framework for Understanding and Training LLMs
The paper "Skill-it! A Data-Driven Skills Framework for Understanding and Training LLMs" presents an innovative approach to optimize the training of LMs by leveraging the concept of ordered skills. It proposes a framework that formalizes skills and their ordering in datasets to enable more efficient learning using a novel algorithm called Skill-it. Below is a breakdown of the methodology, results, and practical implications.
Skills Framework and Definitions
The paper defines a skill as a model behavior unit identifiable via associated data, which, when trained upon, enhances the model's performance in validation on the skill's data subset. An ordered skill set is constructed through a directed graph where skills, represented as nodes, have directed edges if training on one skill reduces the data required to learn another. This construction aims to capture inherent training data synergies and facilitate strategic data sampling.
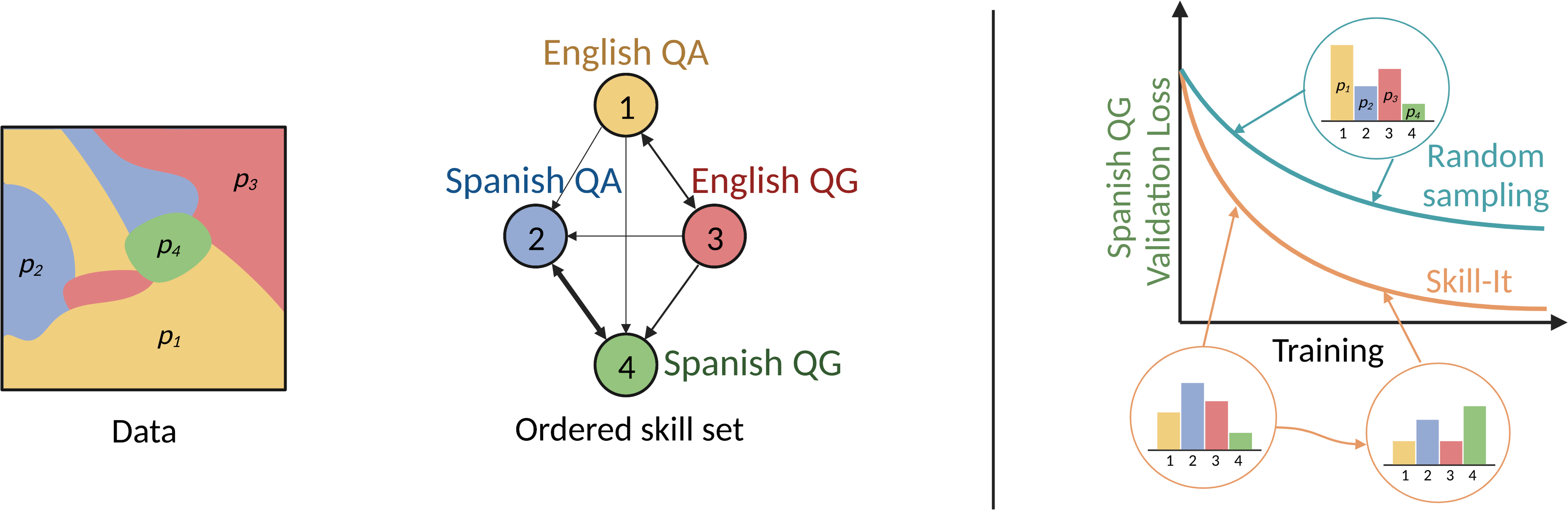
Figure 1: Inspired by how humans acquire knowledge, we hypothesize that LMs best learn skills in a particular order, which can help improve our understanding and training of LMs. Ordered skill sets exist in real data, enabling skills to be learned with less data given training on their prerequisites.
The paper further formalizes the skills graph, detailing methods for its construction and validation using both synthetic data (e.g., LEGO and addition datasets) and real-world tasks (e.g., Natural Instructions). The existence of ordered skill sets was demonstrated, with training efficiency improvements quantified when training incorporates prerequisite skills.
Skill-it Algorithm for Data Selection
Skill-it is introduced as an online data selection algorithm that samples data based on skills' learned ordering, ensuring efficient LM training under various settings: continual pre-training, fine-tuning, and out-of-domain. Each setting aims to leverage the learned skills graph to navigate datasets dynamically, adjusting sample weights towards still-underperforming skills or influential prerequisites.
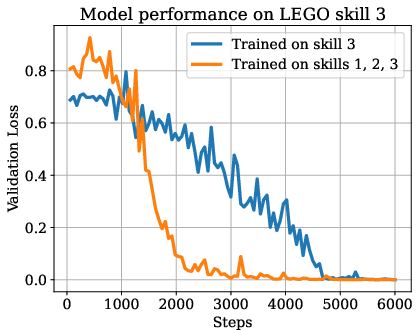
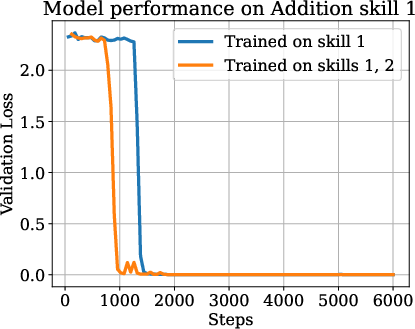
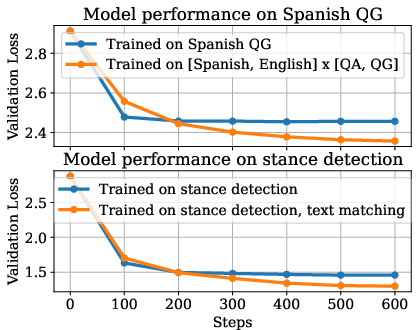
Figure 2: On synthetic datasets and Natural Instructions, ordered skill sets were identified where training on a mixture of skills leads to more efficient learning of an individual skill than training only on that skill.
Skill-it operates over multiple rounds, adjusting sampling strategies in response to evaluation skill losses, and shows superiority over static approaches and alternative baselines, such as random or stratified sampling.
Experimental Results and Observations
The empirical evaluation on various datasets and task settings demonstrates Skill-it's efficacy. For instance, in the LEGO synthetic dataset, Skill-it achieved a 35.8-point accuracy improvement over standard methods. In Natural Instructions, it delivered a 13.6% validation loss reduction during fine-tuning.
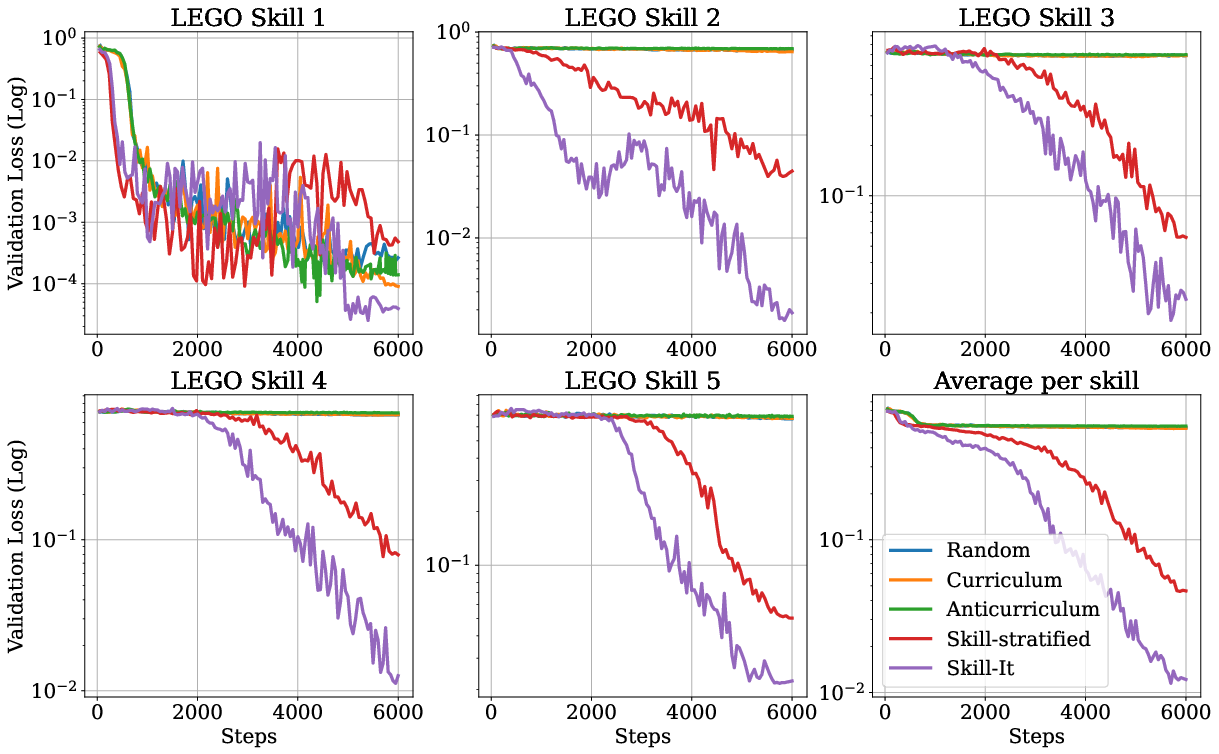
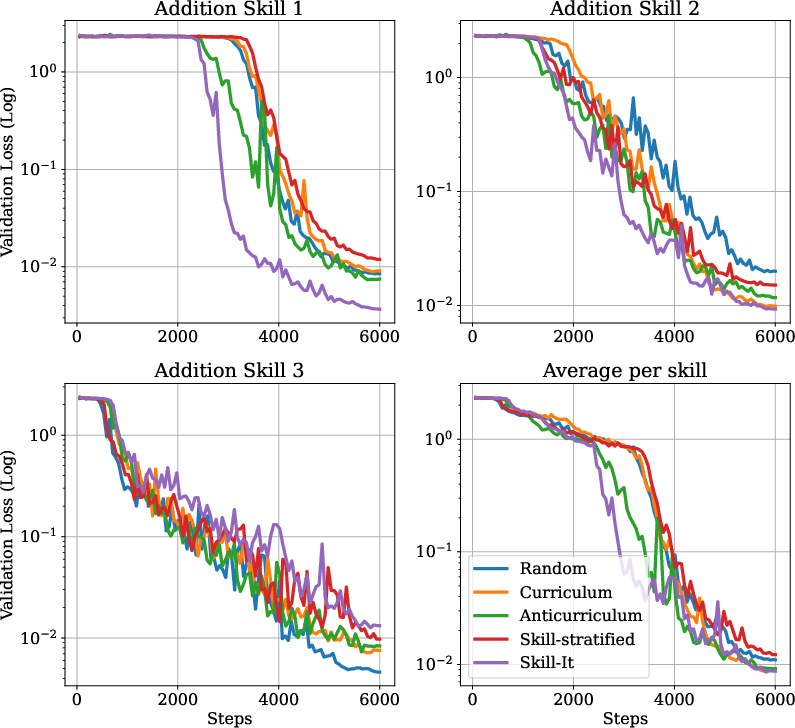
Figure 3: Performance of Skill-it in the continual pre-training setting shows significant efficiency over standard sampling in learning all skills collectively.
These findings suggest that modeling and utilizing skill dependencies are crucial for improving training efficiency. The transferability of learned skill graphs is noted, as graphs trained on smaller models can inform larger model training, optimizing computational resources.
Implications and Future Work
The developments presented in this work stress the importance of understanding training data structuring within the scope of LLM development. The usage of skill ordering enables the conservation of training resources and can direct research towards further exploration in skill discovery and exploitation of cross-task synergies.
Future research could involve exploring methods for deriving skill orders from large-scale datasets and investigating fine-grained adjustments to edge weights in skills graphs over varying model architectures.
Conclusion
The paper successfully integrates pedagogy-inspired concepts into machine learning, offering concrete techniques to enhance LLM training through informed data selection strategies. The Skill-it framework provides a promising direction for achieving accelerated and efficient LLM training while underlining the broader significance of skill-driven data structuration in AI research.