- The paper introduces a framework for answering complex existential first-order queries on knowledge graphs, extending beyond traditional set operations.
- It presents a detailed dataset with 741 query types and a complete pipeline for query generation, model training, and evaluation.
- The study identifies systematic biases in existing models, paving the way for more robust evaluations in complex knowledge graph querying.
EFOk-CQA: Towards Knowledge Graph Complex Query Answering beyond Set Operation
Introduction
The paper entitled "EFOk-CQA: Towards Knowledge Graph Complex Query Answering beyond Set Operation" addresses the problem of complex query answering (CQA) on knowledge graphs (KGs) extending beyond traditional set operations. It introduces a comprehensive framework that encompasses data generation, model training, and evaluation for Existential First-Order Queries with multiple variables (EFO). This approach significantly broadens the query space in comparison to existing literature, which predominantly focuses on set operations.
Problem Definition
To tackle complex query answering in knowledge graphs, the paper defines the problem using Existential First-Order (EFO) logical queries on KGs. Here, logical queries are formulated not just with set operations but also through complex logical connectives and quantifiers. This formulation enables a more comprehensive examination of data using the open-world assumption (OWA), where incomplete knowledge is a characteristic limitation.
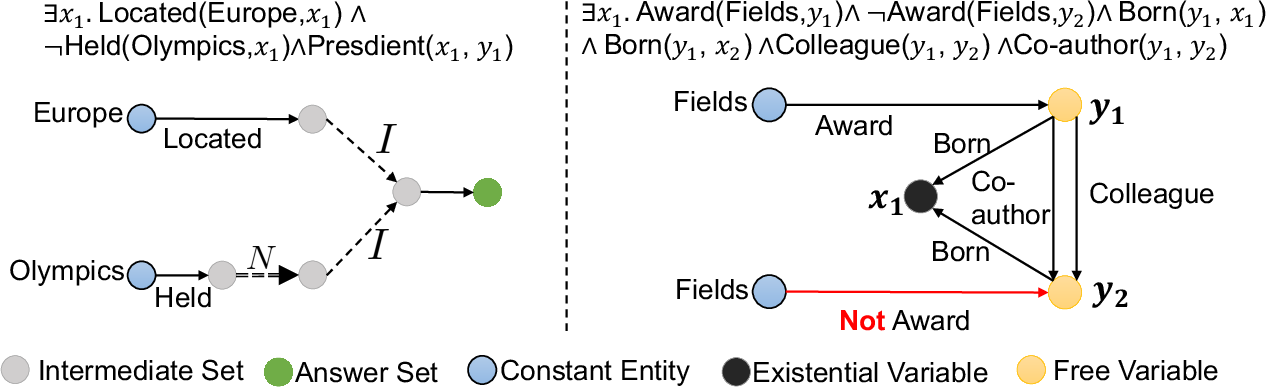
Figure 1: Operator Tree versus Query Graph for EFO query representation.
Framework for EFOk Queries
The introduced framework provides a systematic approach for querying knowledge bases using EFO queries. It is capable of capturing the complete scope of EFO queries, addressing combinatorial and structural hardness. Through the derivation of the EFO-CQA dataset, the paper expands on existing benchmarks like EFO-1-QA and includes high-quality, nontrivial queries.
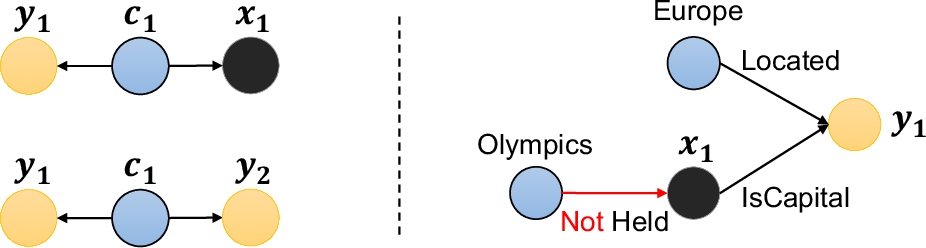
Figure 2: Example of abstract query graph demonstrating redundancy violation.
The framework also streamlines the process from query generation to evaluation. It supports the entire pipeline for model development, making it compatible with existing set-operation-based methods as well as more recent models that extend beyond these limitations.
Dataset and Benchmark Results
The dataset, EFO-CQA, is meticulously constructed to provide 741 query types for empirical evaluation. This dataset aids in deriving insights into how different query hardness influences results. Six representative CQA methods were evaluated, revealing systematic biases in existing datasets that hinder method development. The benchmarks included in this research demonstrate superior model performances on various query types and configurations, reshaping previous empirical conclusions.

Figure 3: The functionality of the framework, showing various phases from abstract mapping to query answering.
Implementation and Evaluation
The implementation strategy includes:
- Query Representation: Transition from operator trees to more expressive query graphs.
- Model Compatibility: Backward compatibility ensuring support for traditional CQA models and advanced ones.
- Evaluation Protocol: Proposes a novel metric for evaluating queries with multiple free variables, thereby enabling a robust assessment of learning-based methods in complex scenarios.
Conclusion
The paper contributes significantly to the field of complex query answering by addressing shortcomings in existing methodologies and datasets. The proposed EFO-CQA dataset and framework play a critical role in advancing the study and application of complex queries on knowledge graphs. It paves the way for more comprehensive and efficient methodologies that are crucial for databases and open-world knowledge inference.
Overall, the research emphasizes the importance of rigorous data-driven approaches in logical query answering, providing new perspectives on dataset construction and evaluation metrics. Future work may focus on refining these approaches to further enhance the scalability and efficiency in querying and knowledge extraction from large-scale knowledge graphs.

