- The paper reveals that LLMs often misjudge their factual knowledge, showing a gap between perceived and actual performance.
- The study demonstrates that integrating high-quality retrieval augmentation significantly improves QA accuracy, as measured by EM and F1 scores.
- The research highlights that dynamic incorporation of supporting documents reduces overconfidence and increases model caution in responses.
Investigating the Factual Knowledge Boundary of LLMs with Retrieval Augmentation
Introduction
The paper presents an analysis of the factual knowledge boundaries of LLMs with a focus on retrieval augmentation. This study addresses the knowledge-intensive task of open-domain question answering (QA), evaluating how LLMs perform with and without the support of external retrieval sources. The research explores three primary questions regarding the perception of factual knowledge boundaries, the effect of retrieval augmentation, and the impact of supporting document characteristics on LLM performance.
Methodology
The research focuses on open-domain QA, where models must provide answers from a large text corpus. This involves two processes: solving the QA task with internal model knowledge and enhancing the task with retrieval-augmented methods. The task is formalized through prompts that guide LLMs in generating responses based on either their stored knowledge or additional supporting documents retrieved externally.
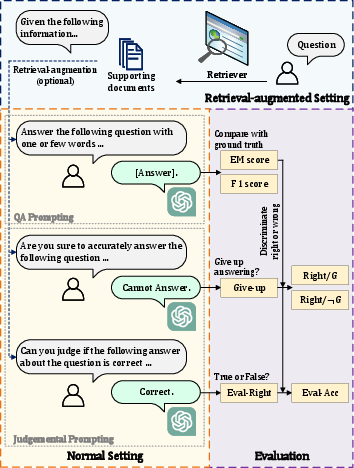
Figure 1: The illustration of different settings to instruct LLMs with natural language prompts, where the corresponding metrics are also displayed.
Retrieval-Augmented Settings
The study employs several retrieval sources to provide supporting documents, including dense and sparse retrieval methods, as well as generative LLM outputs such as those from ChatGPT. Various prompts guide LLMs to utilize these documents in generating QA responses.
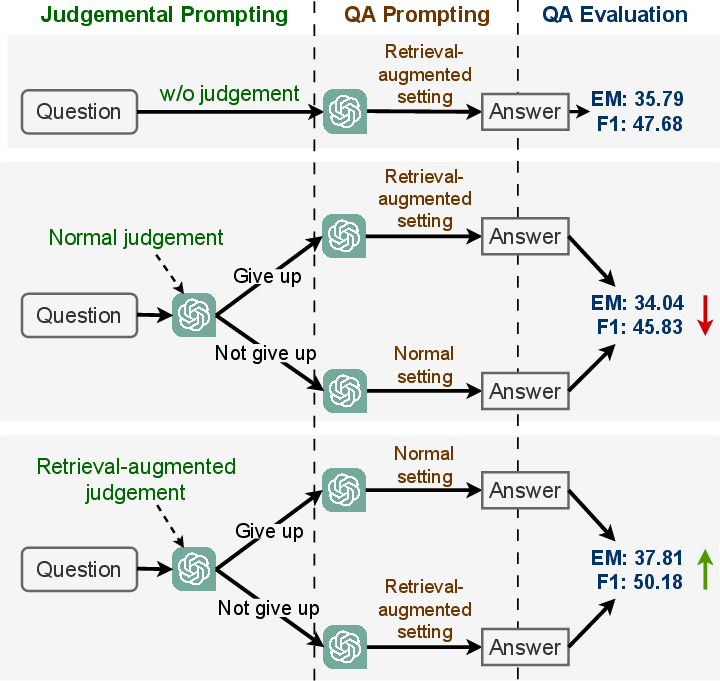
Figure 2: A simple method that dynamically introduces retrieval augmentation for LLMs, the dynamic introducing rules depend on different priori judgement setting.
Evaluation Metrics
The study uses standard QA metrics like exact match (EM) and F1 scores, along with newly defined metrics for judging LLM capabilities such as Give-up rate, Right/G, Right/¬G, Eval-Right, and Eval-Acc to assess both priori and posteriori judgement.
Results
Factual Knowledge Boundary Perception
Results indicate that LLMs are generally confident yet often inaccurate in perceiving their factual knowledge boundaries. They show a significant disparity between perceived and actual QA accuracy, with higher give-up rates in models like ChatGPT that correlate to a more cautious answering approach.
Retrieval Augmentation Impact
Retrieval augmentation notably improves LLM performance, enhancing both QA accuracy and judgement capabilities. This is achieved by providing LLMs with high-quality, relevant documents. A dynamic method involving judgement-based incorporation of retrieval augmentation increases performance further.
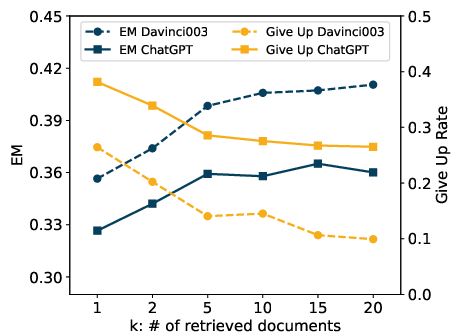
Figure 3: The performance and priori judgement of LLMs with increasing supporting document numbers.
Impact of Supporting Document Characteristics
The quality and relevance of supporting documents were found to significantly affect LLM performance. High-quality, precise documents enhance both the confidence and accuracy of LLM responses, while reliance on less relevant documents can degrade performance.
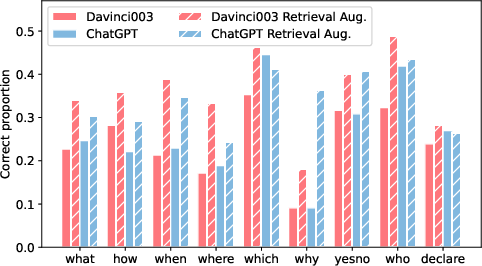
Figure 4: The proportion of questions answered correctly by LLMs in different question categories under two QA prompting settings.
Conclusion
The study concludes that LLMs do not fully utilize their inherent knowledge, benefitting significantly from retrieval augmentation. This not only improves QA capabilities but also reveals gaps in their perception of knowledge boundaries. Future work may explore more sophisticated retrieval mechanisms and prompt designs to further refine LLM capabilities in knowledge-intensive tasks.

