- The paper demonstrates that sample-based uncertainty estimation methods provide superior risk assessment for LLM outputs.
- It evaluates how task type and prompt design significantly influence the accuracy of uncertainty measurements.
- The study underscores the need for advanced, model-specific techniques to detect subtle prediction errors in LLMs.
An Exploratory Study of Uncertainty Measurement for LLMs
The paper investigates uncertainty measurement techniques for LLMs by analyzing their prediction risks. It employs twelve uncertainty estimation methods across various NLP and code-generation tasks, evaluating their effectiveness in identifying potential pitfalls in LLM outputs. The study aims to enhance the reliability of LLMs, particularly for industrial applications.
Introduction to the Problem
The recent advancements in LLMs have significantly improved their performance across a wide range of tasks. However, these models have a propensity for generating erroneous outputs, such as misinformation or non-factual content, which is a growing concern for deploying LLMs in safety-critical applications. Uncertainty estimation is a technique that provides insights into the confidence level of these models in their predictions, potentially serving as a tool to flag unreliable outputs. Despite its potential, the application of uncertainty estimation in the context of LLMs remains insufficiently explored due to the distinctive challenges posed by these models.
Methodology
The paper conducts a comprehensive analysis by integrating twelve uncertainty estimation methods into LLM workflows to assess their utility in identifying prediction errors (Figure 1).
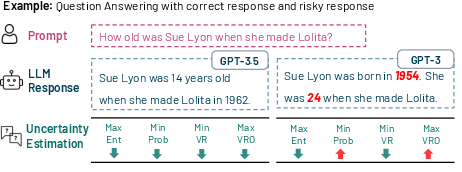
Figure 1: Uncertainty estimation for a QA task.
The study categorizes these methods into three main types based on the number of inferences required: single-inference, multi-inference through sampling, and perturbation-based multi-inference methods. The performance of these methods is evaluated across several prominent LLMs, including both open-source and proprietary models, on a variety of tasks such as question answering, text summarization, machine translation, and code generation.
Experimental Setup and Results
The experiments involved open-source models such as GPT-2 and LLaMA, alongside closed-source models like GPT-3. Tasks were selected to cover both broad NLP applications and specific code-generation scenarios, using datasets like ELI5-Category for QA and MBPP for coding tasks.
The results indicate that sample-based methods using multi-inference techniques showed the highest correlation with model performance across the evaluated tasks (Figure 2).
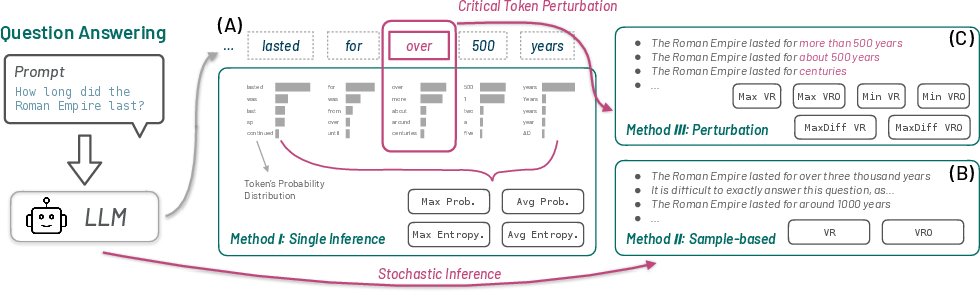
Figure 2: A running example of how different uncertainty estimation methods work for a QA problem with GPT3.
However, these methods also exhibited limitations, particularly when dealing with high-performing models where subtle errors were prevalent. Additionally, the study noted that perturbation-based methods were model-specific and sensitive to the choice of perturbation points, suggesting the need for model-specific optimization.
Key Findings
- Effectiveness of Sample-based Methods: Among the tested methods, sample-based uncertainty estimation consistently outperformed others, indicating its potential as a reliable risk assessment tool across different LLMs (Figure 3).

Figure 3: An example of multiple inferences with LLMs.
- Influence of Task and Prompt: The effectiveness of uncertainty estimation was found to be task-dependent. The prompt design, particularly for models incorporating RLHF, significantly influenced uncertainty measurement accuracy.
- Limitations in Detecting Subtle Errors: The study identified challenges in using uncertainty estimation to detect nuanced errors, especially when models performed exceptionally well or poorly across tasks.
Discussion: Implications and Opportunities
The findings underscore the utility of uncertainty estimation in enhancing LLM trustworthiness but also highlight several areas for improvement. The study suggests future research should focus on developing advanced methods that can discern both epistemic and aleatoric uncertainties more effectively. Given the complexity of LLMs and their diverse applications, future work could explore integrating model-specific uncertainties and incorporating prompt design considerations to optimize uncertainty estimation techniques.
Conclusion
This exploratory study provides valuable insights into the application of uncertainty estimation for LLMs, identifying both the potential and the limitations of current methods. By demonstrating the effectiveness of various uncertainty estimation techniques across different tasks and models, the research lays the groundwork for developing more robust risk assessment tools that can enhance the reliability of LLM deployments in real-world scenarios. As LLMs continue to expand their reach, ensuring their outputs are reliable remains a critical challenge that uncertainty estimation can help address.