- The paper introduces an imitation learning framework that discovers, aligns, and transfers cross-embodiment skills from human demonstration videos to robotic actions.
- It employs conditional diffusion models and self-supervised clustering to create a unified skill representation space across human and robot data.
- Evaluations in simulated and real-world settings show significant improvements over baselines, demonstrating robustness and scalability in complex task compositions.
XSkill: Cross Embodiment Skill Discovery
Introduction
XSkill introduces an imitation learning framework that tackles the challenges of skill discovery, transfer, and composition across different embodiments. By leveraging human demonstration videos, which are abundant and possess intuitive task representations, XSkill bridges the gap between human demonstrations and robot actions through a cross-embodiment skill representation space, conditional diffusion policies, and a skill alignment transformer.
Methodology
Cross-Embodiment Skill Discovery
XSkill begins with the discovery of robust cross-embodiment skill prototypes using self-supervised learning on human and robot video data.
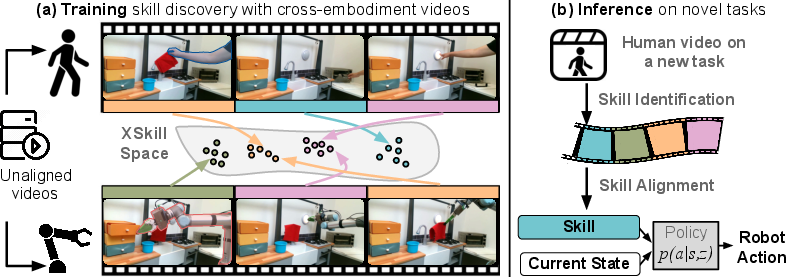
Figure 1: Cross Embodiment Skill Discovery. XSkill identifies and executes skills through a learned representation space.
The framework employs feature clustering via learnable skill prototypes, aligning skill representations from different embodiments by using shared prototypes across the spaces. This approach prevents embodiment-specific segmentation and ensures unified skill representation.
Transfer via Skill-Conditioned Imitation Learning
The transfer phase involves learning a skill-conditioned visuomotor policy using imitation techniques. XSkill utilizes diffusion models, specifically Denoising Diffusion Probabilistic Models (DDPMs), to manage multimodal action distributions derived from human teleoperation data. This technique ensures the stable representation of action distributions, even with limited datasets.
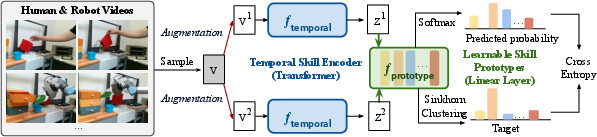
Figure 2: XSkill Discover: Temporal encoding and clustering process for aligning cross-embodiment skill representations.
Skill Composition for New Tasks
In the final phase, a single human prompt video is used to specify a new task, for which the robot extrapolates a sequence of skills. However, speed mismatches between human and robot executions pose a challenge. To address this, XSkill employs a Skill Alignment Transformer (SAT) to align task execution with the robot's pace, introducing robustness against execution errors.
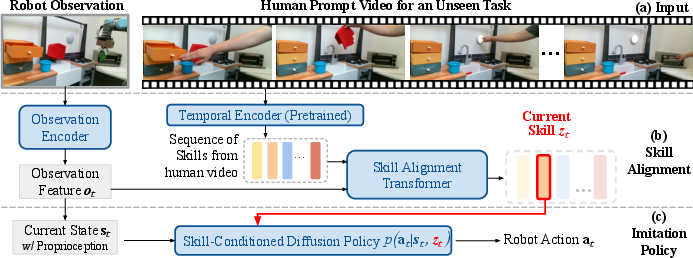
Figure 3: Transfer and Composition: Skill execution plan alignment using SAT for mismatch handling between human demonstrations and robot tasks.
Evaluation
The framework is evaluated in both simulated and real-world environments, demonstrating significant improvements over baselines in cross-embodiment skill performance. XSkill outperforms goal-conditioned diffusion policies and shows robustness against variations in task execution speed.
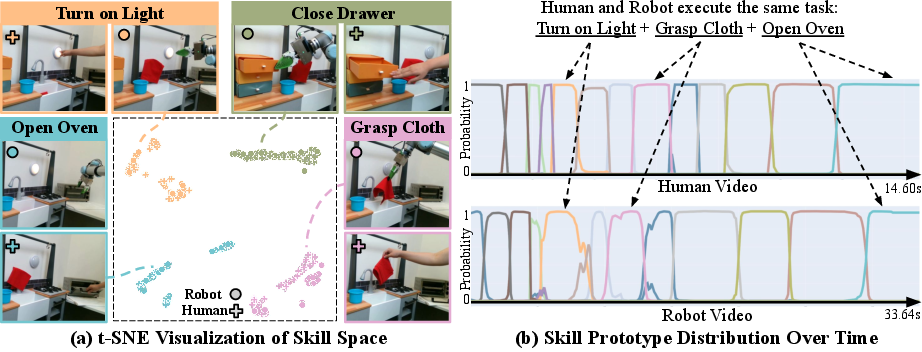
Figure 4: XSkill embedding. Alignment of skill representations via t-SNE visualization, showcasing embodiment consistency.
This performance is particularly evident in tasks with unseen compositions, where the composition framework significantly boosts imitation learning's applicability to real-world scenarios.
Key Findings and Implications
XSkill excels at leveraging human demonstration videos to infer cross-embodiment skills, thereby enhancing the scalability and generalizability of skill transfer to robotic actions. However, the method performs optimally when provided with sufficient and diverse robotic teleoperation data to encapsulate transition dynamics across varying environments. Future research directions may explore further diversifying data sources, including varied camera setups and leveraging extensive publicly available human video data.

Figure 5: Robot execution on novel tasks, demonstrating robustness and skill re-composition after perturbation.
Conclusion
XSkill's framework provides a compelling approach to cross-embodiment skill learning, utilizing shared skill prototypes to bridge the gap between distinct embodiments. It sets the foundation for future work in expanding imitation capabilities across various robotic systems, emphasizing cost-effective and scalable learning methodologies from human demonstrations. The combination of discovery, transfer, and composition phases heralds a more generalized solution to imitation learning challenges, poised for further enhancement and adoption across varied domains.