- The paper demonstrates that both fine-tuning and soft prompt tuning adapt Whisper to capture disfluencies for accurate spoken language assessment.
- It employs targeted retraining on limited data, achieving a 30% boost in error recall metrics on key transcription errors such as hesitations and abbreviations.
- Experiments on standard and L2 learner datasets highlight significant improvements, with recall reaching over 82% compared to a 15.4% baseline.
Adapting an ASR Foundation Model for Spoken Language Assessment
Introduction
The paper presents strategies to adapt the Whisper, a large-scale ASR foundation model, for automated spoken language assessment purposes. Whisper's default transcription methods optimize for human readability, incorporating features such as punctuation and inverse text normalization (ITN). However, these features can omit essential disfluencies, hesitations, and speech errors critical for assessing language proficiency. The paper offers fine-tuning and soft prompt tuning as potential solutions to customize Whisper's decoding behavior to provide precise transcriptions of the spoken language for a more accurate assessment.
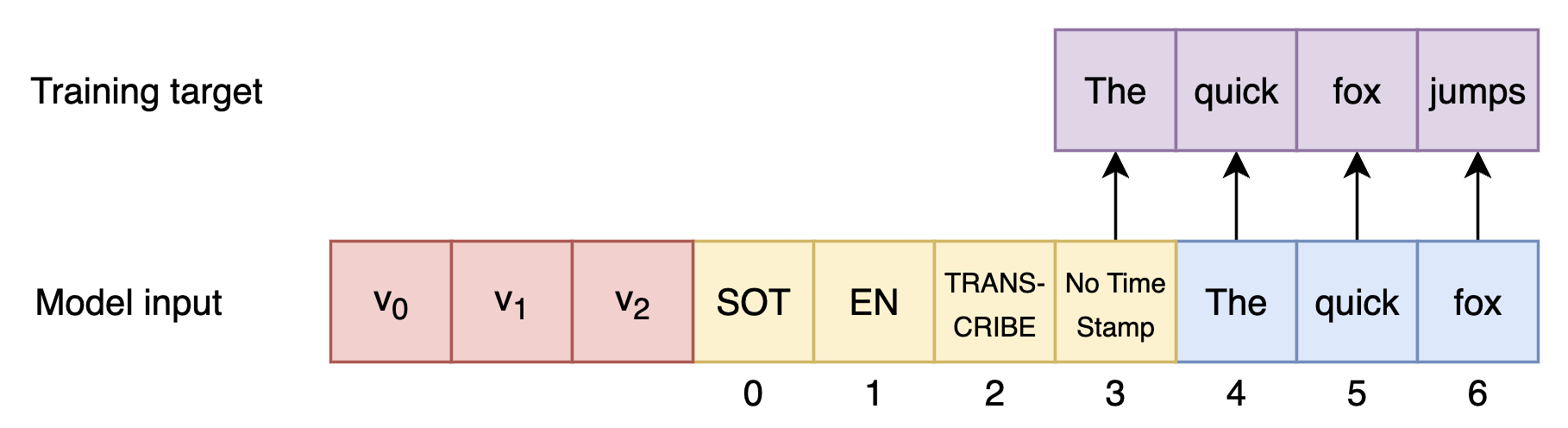
Figure 1: Modified decoder input with soft prompt training. Numbers refer to the order of positional embeddings.
Proposed Methods
Fine-Tuning Approach
Fine-tuning involves adjusting all parameters in Whisper using domain-specific data. By recalibrating the model with limited hours of targeted data, Whisper can be guided to recognize and reflect every word uttered, including hesitations and disfluencies that form the basis of spoken language assessments.
Soft Prompts Tuning Approach
The novel soft prompt tuning (SPT) method inserts limited parameter vectors into the decoder input, leaving the main ASR model unmodified. This technique focuses on optimizing soft prompt embeddings to imbue domain-specific information into the ASR process. This method is parameter-efficient and circumvents the risks of overfitting and forgetting inherent knowledge learned during pre-training.
Evaluation Metrics
Two main evaluation metrics were employed:
- WER Calculation: Speech WER, tailored to evaluate ASR performance for SLA, eliminates punctuation and adjusts hesitations uniformly.
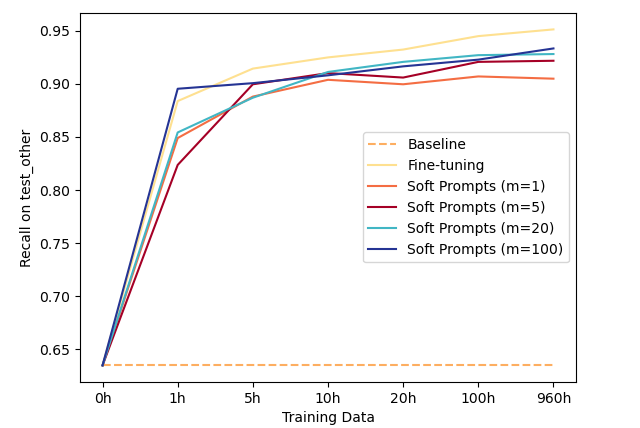
Figure 2: Overall word recall on test_other when tuning on different hours of LibriSpeech training data.
- Error Counts Analysis: Recall statistics for specific token types—hesitation, number, abbreviation, disfluency, and partial words—highlight model accuracy improvements across these categories.
Experimental Results
On Standard Datasets
Experiments conducted on datasets like LibriSpeech and TED-LIUM 3 demonstrate substantial performance improvements with both FT and SPT models, even when trained with only 10 hours of data. The recall metrics showed a roughly 30% boost in accuracy across all error types, notably in abbreviations and numerical representations.
On L2 Learner Data
Tests on the Linguaskill dataset, which consists of recordings from English learner proficiency tests, underline the proficiency of the proposed methods in real-world SLA contexts. Deletions in transcripts were substantially reduced, improving overall recall from 15.4% with the baseline model to over 82% with FT and SPT approaches. This improvement was crucial for accurate SLA application.
Conclusions
The paper illustrates compelling methods to adapt large-scale ASR foundation models for precise spoken language assessment. The fine-tuning and soft prompt tuning approaches successfully transform Whisper's transcription capabilities without needing extensive computational resources. Final results exhibit the potential of these approaches in both domain-specific and generalized SLA applications. The implication of this research could lead to efficient, accurate, and automated assessment systems being integrated into language learning platforms, providing consistent and timely feedback to language learners globally.
The strategic parameter estimation and optimization techniques demonstrated in this study offer a promising avenue for future AI development in language processing and assessment.