- The paper introduces S2R-ViT, a novel vision transformer that mitigates both deployment and feature gaps in multi-agent cooperative perception.
- It leverages S2R-UViT’s multi-head self-attention and uncertainty modules to counter GPS errors and communication latency in vehicle networks.
- S2R-AFA applies adversarial domain adaptation to extract domain-invariant features, significantly boosting 3D object detection performance on real-world datasets.
S2R-ViT for Multi-Agent Cooperative Perception: Bridging the Gap from Simulation to Reality
Introduction
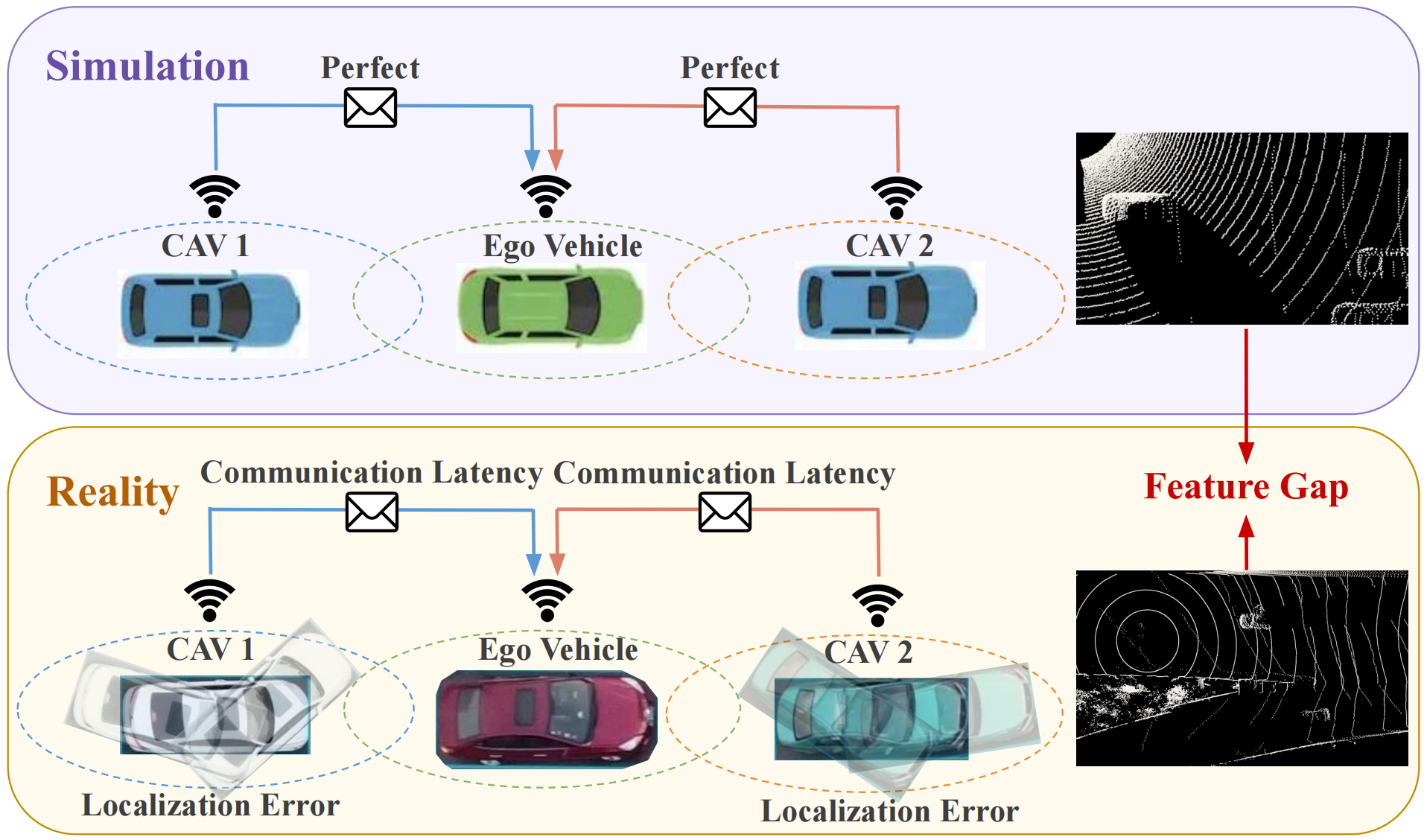
The paper examines the significant domain gap between simulated and real-world data in multi-agent cooperative perception frameworks. It introduces a Simulation-to-Reality transfer learning framework leveraging a novel Vision Transformer called S2R-ViT. This research focuses on addressing the Deployment Gap and Feature Gap within the simulation-to-reality context, particularly in Vehicle-to-Vehicle (V2V) cooperative perception systems for point cloud-based 3D object detection.
Domain Gap Analysis
The primary issues identified are the Deployment Gap and Feature Gap.
S2R-ViT Architecture
The proposed S2R-ViT consists of two critical components: the S2R-UViT module and the S2R-AFA module.
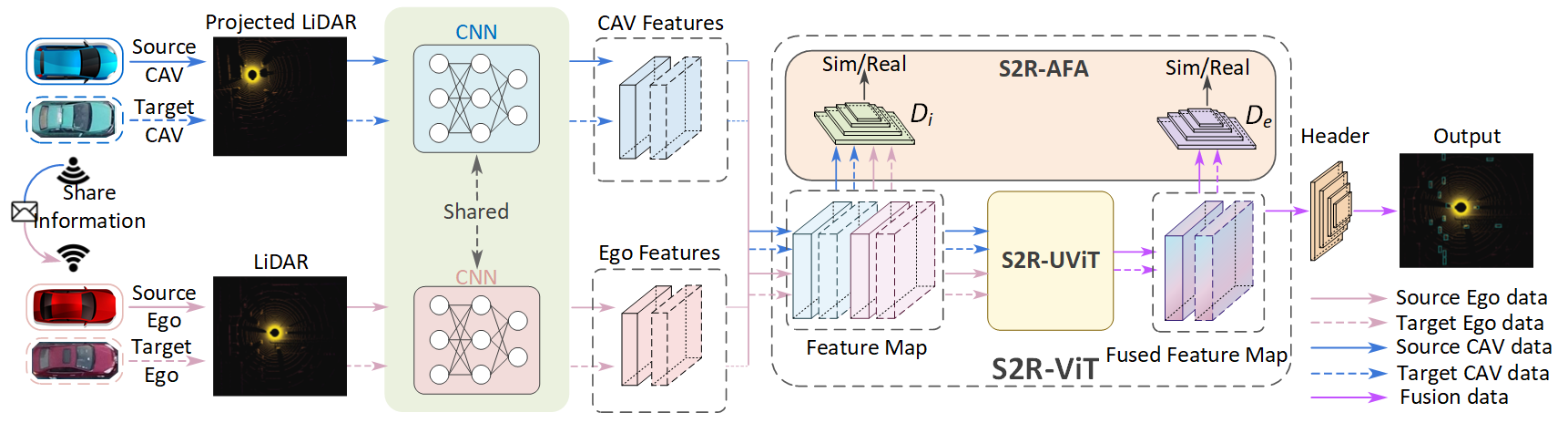
Figure 2: Overview of the proposed S2R-ViT leveraging S2R-UViT and S2R-AFA modules.
S2R-UViT is designed to address uncertainties arising from the deployment gap by enhancing feature interactions. It consists of:
- Local-and-Global Multi-head Self Attention (LG-MSA): This module enhances the comprehension of both local details and global context in agent feature spaces. Features from multiple agents are processed in parallel attention layers that capture positional accuracy across various scopes.
- Uncertainty-Aware Module (UAM): Utilizes an Uncertainty Prediction Network to determine the reliability of spatial features across agents, manipulating high-uncertainty feature spaces to suppress their negative influences on ego-agent data.
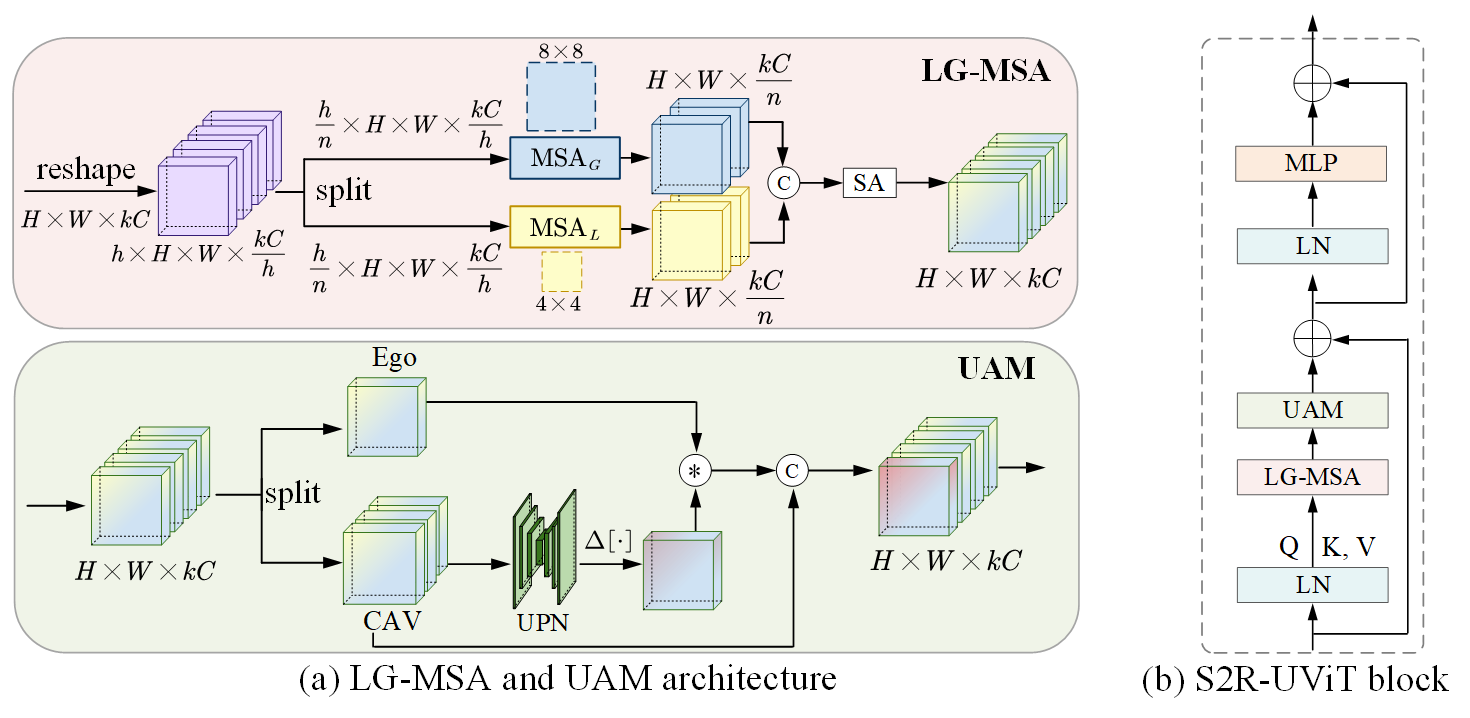
Figure 3: Architecture of the proposed S2R-UViT module.
S2R-AFA: Agent-based Feature Adaptation
S2R-AFA aims to reduce the feature gap by applying adversarial domain adaptation methods. It employs inter-agent and ego-agent domain discriminators to force extraction of domain-invariant features. The feature adaptation loss guides these discriminators adversarially, enhancing the model's ability to handle real-world data inputs effectively.
Experimental Results
Experiments were conducted using the OPV2V and V2V4Real datasets. The S2R-ViT framework demonstrated substantial improvements in addressing both deployment and feature gaps when evaluated on simulated and real-world scenarios.
Deployment-Gap Scenario
For testing on CARLA Towns under both perfect and noisy conditions, S2R-UViT exhibited robustness against GPS errors and communication latency, outperforming state-of-the-art methods in maintaining high object detection precision.
Figure 4: Robustness in Deployment-Gap Scenario showcasing resilience to GPS errors and communication latency.
Sim2Real Scenario
In the Sim2Real setting, leveraging domain adaptation methods, S2R-ViT exhibited enhanced performance on the V2V4Real testing dataset, highlighting its superiority in extracting domain-invariant features crucial for real-world application.
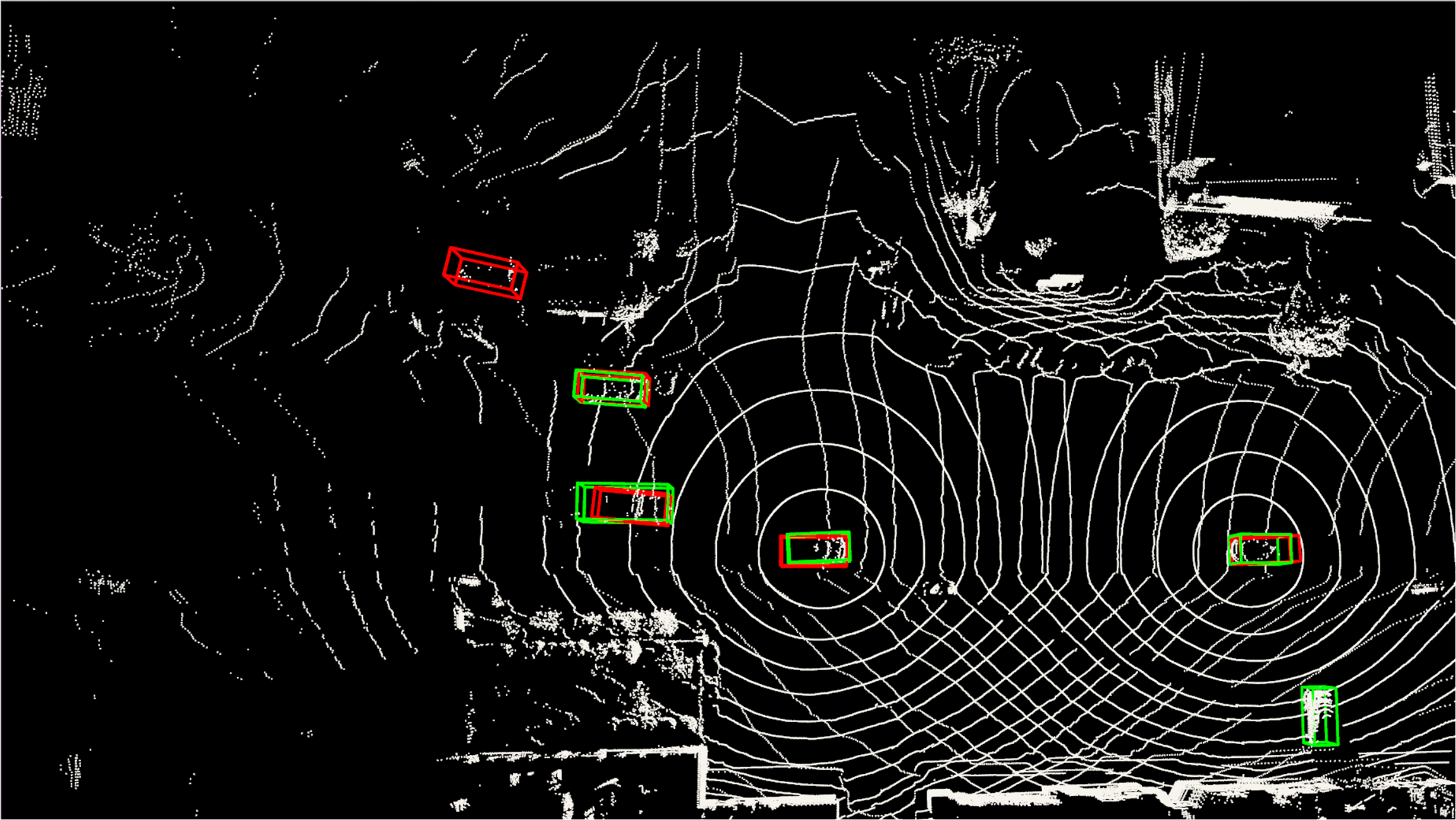
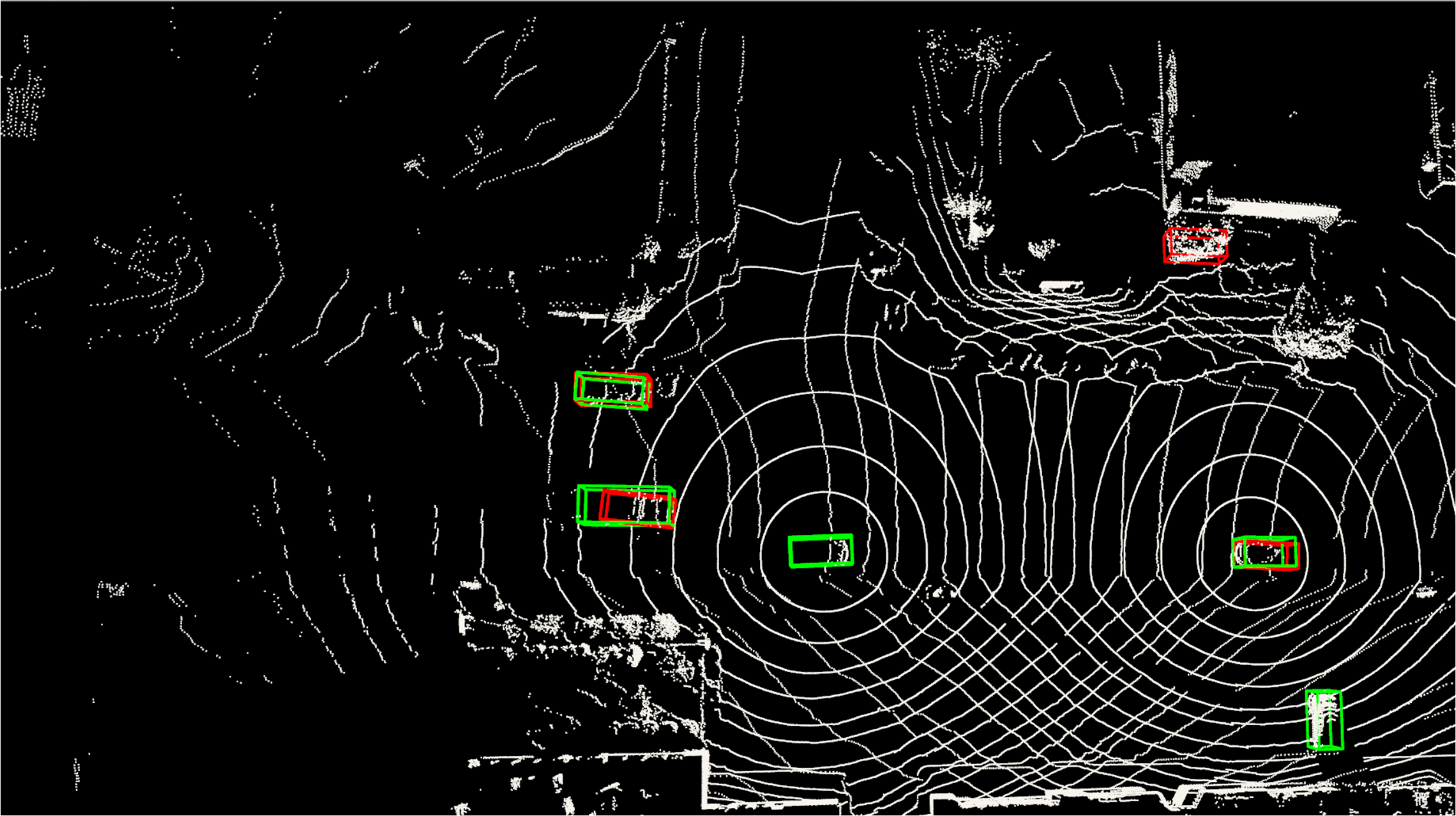
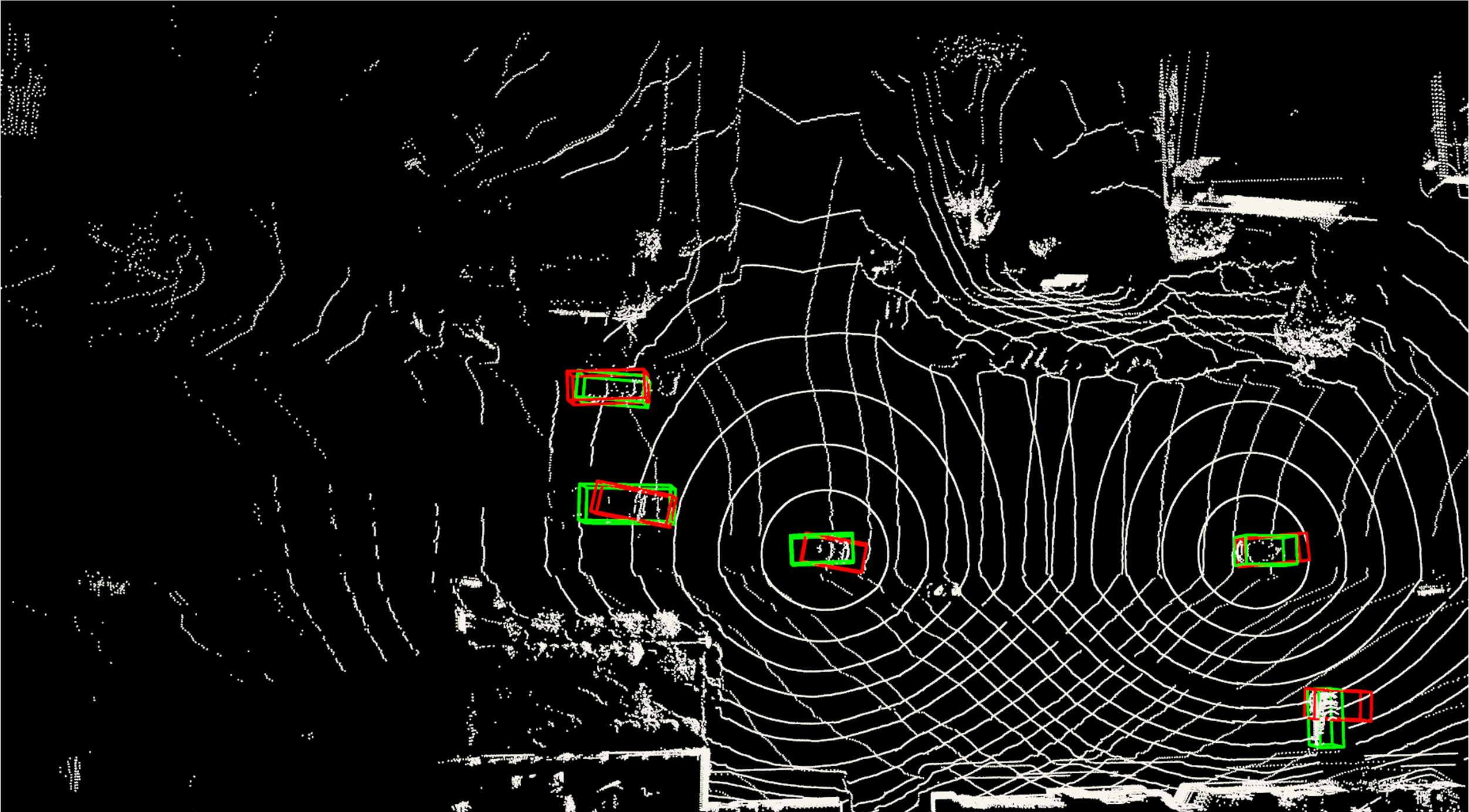
Figure 5: Visualization example of point cloud-based 3D object detection on V2V4Real, demonstrating S2R-ViT's real-world efficacy.
Conclusions
The development of S2R-ViT marks an advance in addressing the inherent challenges of translating multi-agent cooperative perception models from simulated environments to real-world applications. S2R-ViT effectively mitigates both deployment and feature gaps through innovative transformer-based architectures, enhancing the precision and reliability of autonomous perception systems. Future work could explore extending these methodologies to other sensory inputs and more complex operational scenarios.