- The paper proposes a hierarchical residual VQVAE integrated with spatiotemporal PixelCNN to compactly encode video frames and accurately predict future frames.
- The model mitigates high dimensionality and blurriness issues, achieving competitive SSIM, PSNR, and LPIPS results on Moving-MNIST and KTH datasets.
- Joint training of the architecture components enhances prediction accuracy and robustness, paving the way for real-time video processing applications.
S-HR-VQVAE: Sequential Hierarchical Residual Learning Vector Quantized Variational Autoencoder for Video Prediction
Introduction
The paper "S-HR-VQVAE: Sequential Hierarchical Residual Learning Vector Quantized Variational Autoencoder for Video Prediction" presents a novel approach to video prediction by integrating a hierarchical residual learning framework, namely HR-VQVAE, with a spatiotemporal version of the PixelCNN model, dubbed ST-PixelCNN. This method is aimed at overcoming four main challenges inherent to video prediction tasks: spatiotemporal modeling, high dimensionality, blurry predictions, and dealing with physical characteristics.
Model Architecture
The proposed model architecture (Figure 1) leverages HR-VQVAE to create a compact and efficient representation of video frames through hierarchical residual vector quantization. This allows capturing different levels of abstraction, where higher layers encapsulate broader context while lower layers focus on finer details. The integration with ST-PixelCNN facilitates spatiotemporal dependencies across video frames, enabling improved prediction of future frames from a set of preceding ones.
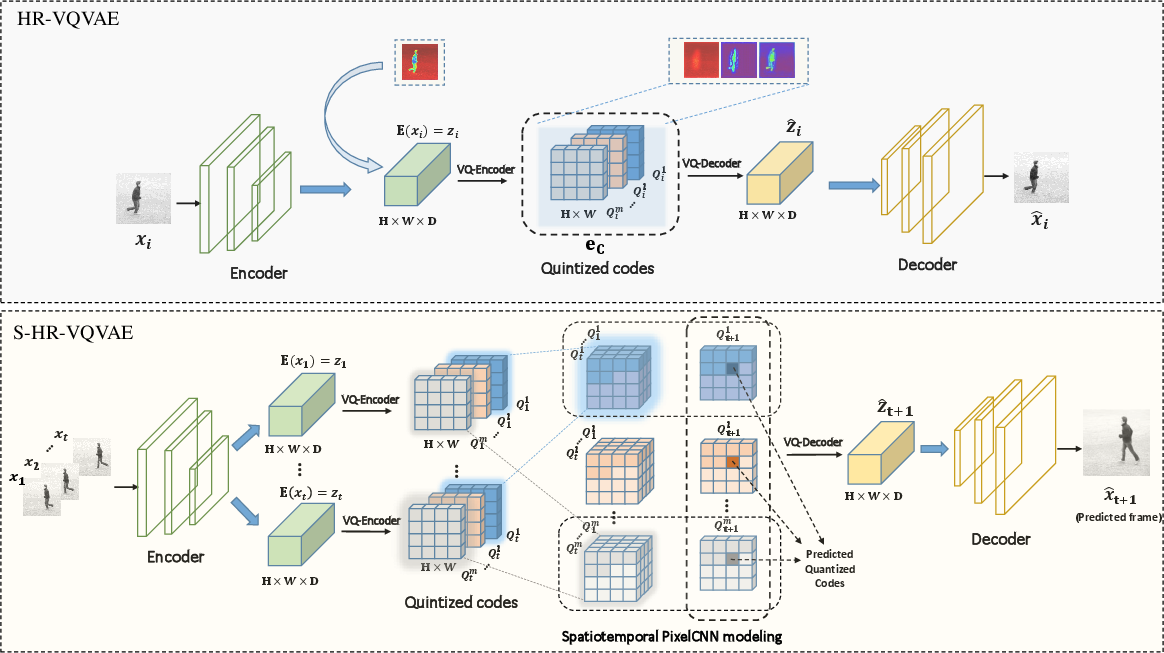
Figure 1: The architecture of the proposed approach. Top: HR-VQVAE for static image reconstruction. Bottom: S-HR-VQVAE for video prediction.
Theoretical Background
Key to the approach is the use of Vector Quantized Variational Autoencoders (VQVAEs), specifically in a hierarchical form. By discretizing latent variables into structured codebooks with a multilevel hierarchy, HR-VQVAE effectively compresses video data and models spatial features. This reduces the high dimensionality typically inherent to video data, allowing better scalability and handling of complex data without the excessive demands on computational resources.
Implementation and Training
Video frames are first encoded into continuous latent variables and then quantized through the hierarchical codebooks. The first step in the process involves mapping these frames into discrete indices which are then utilized by ST-PixelCNN to model spatiotemporal correlations. The final step reconstructs future video frames from these predicted indices using the HR-VQVAE decoder. Significantly, the model can be trained using either disjoint or joint training schemes, with joint training providing gains by simultaneously optimizing the model components.
Experimental Results
Comprehensive evaluations on the Moving-MNIST and KTH Human Action datasets reveal the competitiveness of S-HR-VQVAE against the state-of-the-art. Specifically, the study highlights performance metrics such as SSIM, PSNR, and LPIPS, demonstrating how S-HR-VQVAE attains favorable results in terms of image quality and prediction accuracy.
(Figure 2 and 3)
Figure 2: Comparison of S-HR-VQVAE with state-of-the-art methods on Moving-MNIST dataset over two sequences.
Figure 3: Comparison of S-HR-VQVAE with state-of-the-art-methods on KTH Human Moving Action dataset over three sequences.
Discussion and Implications
The findings suggest that the hierarchical structuring of latent representations not only preserves essential data features but also minimizes prediction inaccuracies such as blurriness and noise. As highlighted in the studies on blurry and noisy scenario tests, S-HR-VQVAE exhibits remarkable robustness. This positions the model as a promising candidate for future applications that require high-quality video predictions under varying conditions.
(Figure 4 and 5)
Figure 4: Heatmap of reconstructions obtained from different layers of a 3-layer HR-VQVAE.
Figure 5: Reconstructions of random frames by HR-VQVAE with different numbers of layers.
Conclusion
The introduction of S-HR-VQVAE expands the potential for efficient and accurate video predictions by combining hierarchical vector quantization with autoregressive modeling in time and space. Future work may further explore integrating such a method with real-time video processing systems. This research underscores the balance between model complexity and performance, illustrating the substantial benefits of using hierarchical structures in AI-driven video analysis tasks.

