- The paper demonstrates that LLMs function as universal pattern machines, solving abstract sequence transformations in zero-shot settings.
- Results show that LLMs achieve advanced sequence completion and extrapolation, outperforming several program synthesis-based systems on benchmarks like ARC.
- The study highlights limitations such as inference latency and tokenization sensitivity, while advocating further research in multimodal and efficient models.
LLMs as General Pattern Machines: An Expert Analysis
Introduction
"LLMs as General Pattern Machines" (2307.04721) systematically investigates the capacity of pre-trained LLMs to function as general-purpose pattern recognizers and manipulators, extending their utility beyond linguistic domains into abstract, symbolic, and robotic settings. The authors empirically demonstrate that LLMs, without additional fine-tuning, can perform in-context learning over sequences of arbitrary tokens, enabling them to complete, transform, and improve patterns in domains such as the Abstraction and Reasoning Corpus (ARC), procedurally generated sequence transformation tasks, and robotic trajectory optimization. This essay provides a technical summary and critical analysis of the paper's methodology, results, and implications for future AI research.
The paper's first major contribution is the demonstration that LLMs can perform nontrivial sequence transformations in a zero-shot, in-context setting. Using the ARC benchmark, which requires abstract spatial and symbolic reasoning, the authors show that models such as text-davinci-003 can solve up to 85 out of 800 problems—surpassing several recent program synthesis-based systems that rely on hand-crafted DSLs.
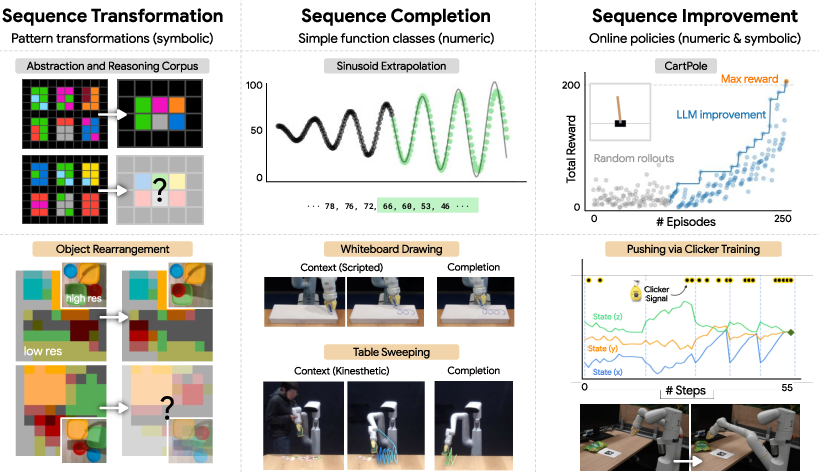
Figure 1: Pre-trained LLMs out-of-the-box may serve as basic versions of general pattern machines that can recognize and complete sequences of numeric or arbitrary (symbolic) tokens expressing abstract problems in robotics and sequential decision-making.
A key finding is the token mapping invariance: LLMs retain significant pattern completion ability even when the underlying tokens are randomly mapped to arbitrary vocabulary entries, or even to out-of-distribution continuous embeddings. This suggests that LLMs' pattern recognition is not solely dependent on semantic priors from pre-training, but also on their ability to model abstract sequence regularities.
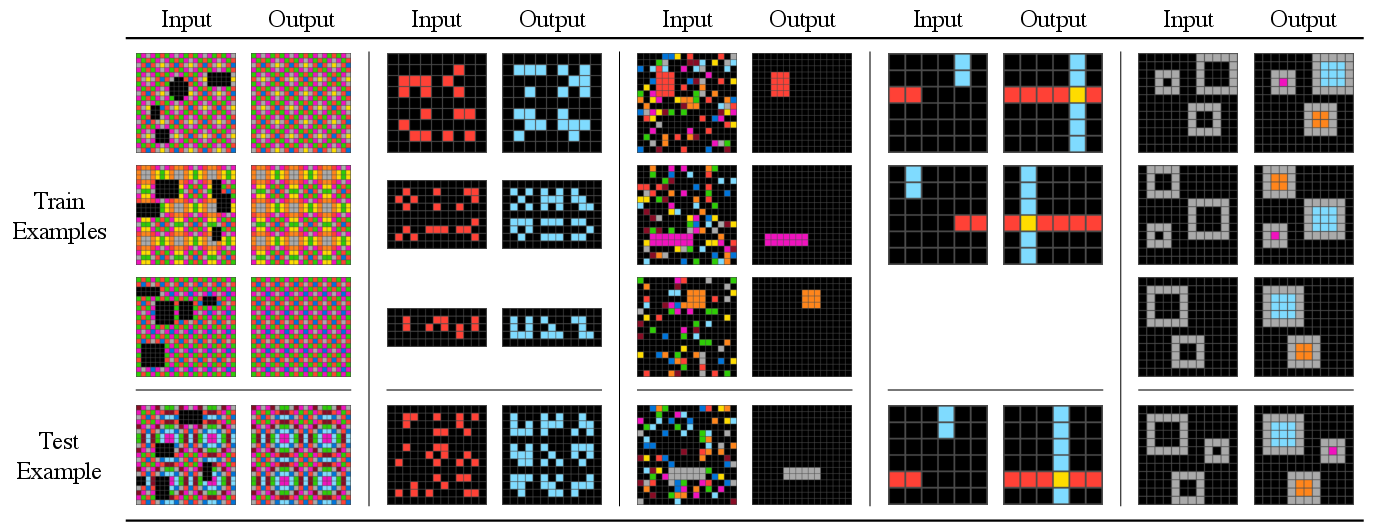
Figure 2: Sample ARC problems that are correctly solved by text-davinci-003.
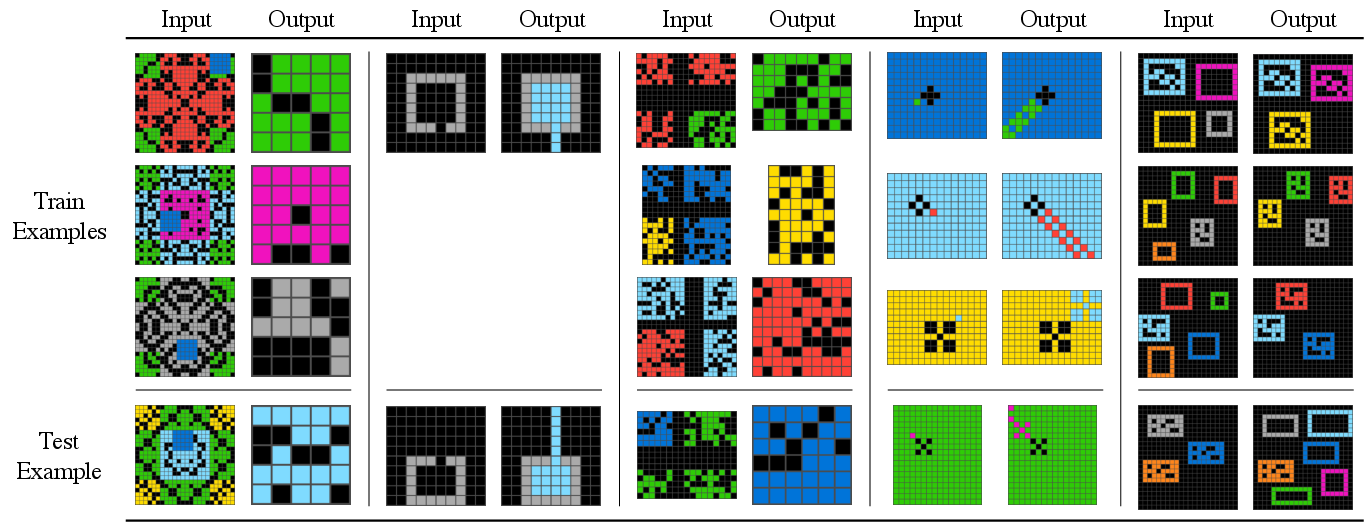
Figure 3: Sample ARC problems that are not correctly solved by text-davinci-003.
To further control for potential data contamination and to provide a scalable difficulty regime, the authors introduce a PCFG-based benchmark for sequence transformation. LLMs' performance on this benchmark scales with model size and correlates with ARC performance, providing a more unbiased measure of abstract pattern reasoning.
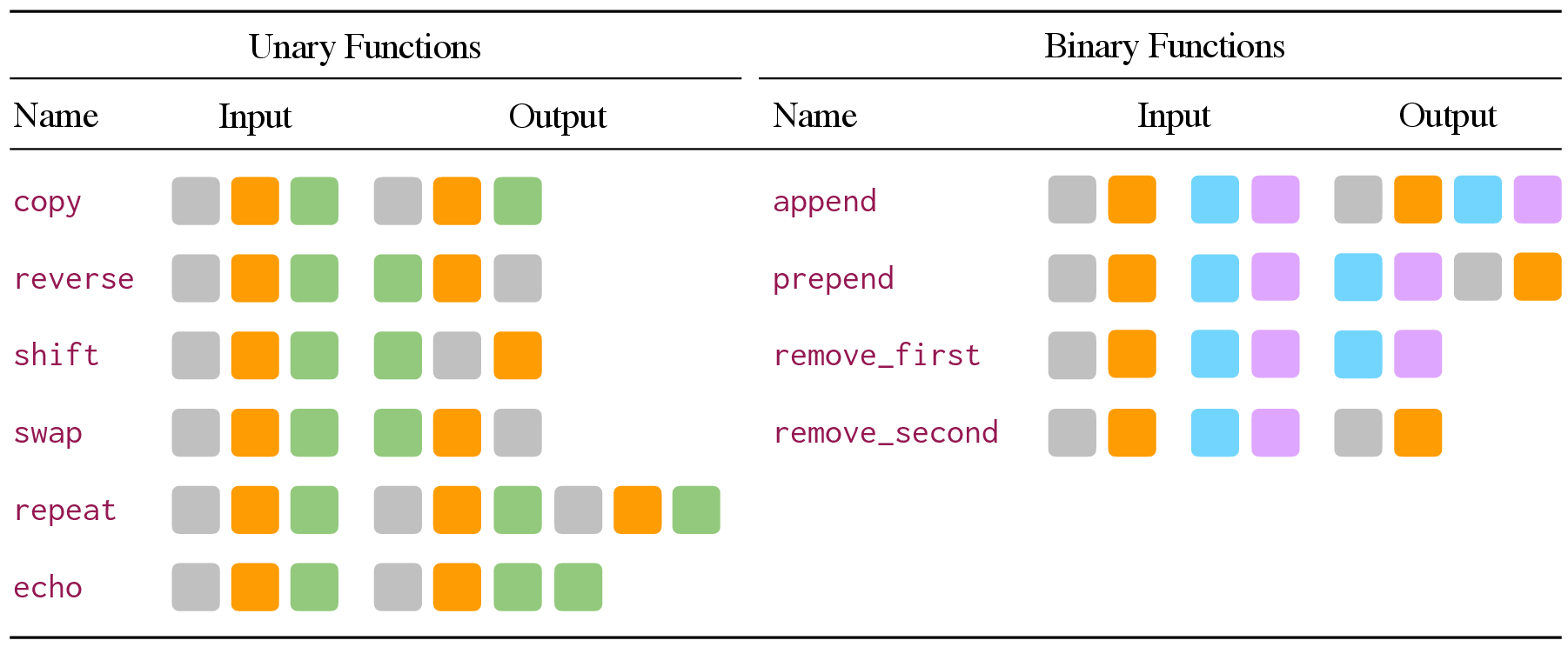
Figure 4: Illustrations depicting the unary and binary operators from Hupkes et al. 2020, which are used for the PCFG benchmark.
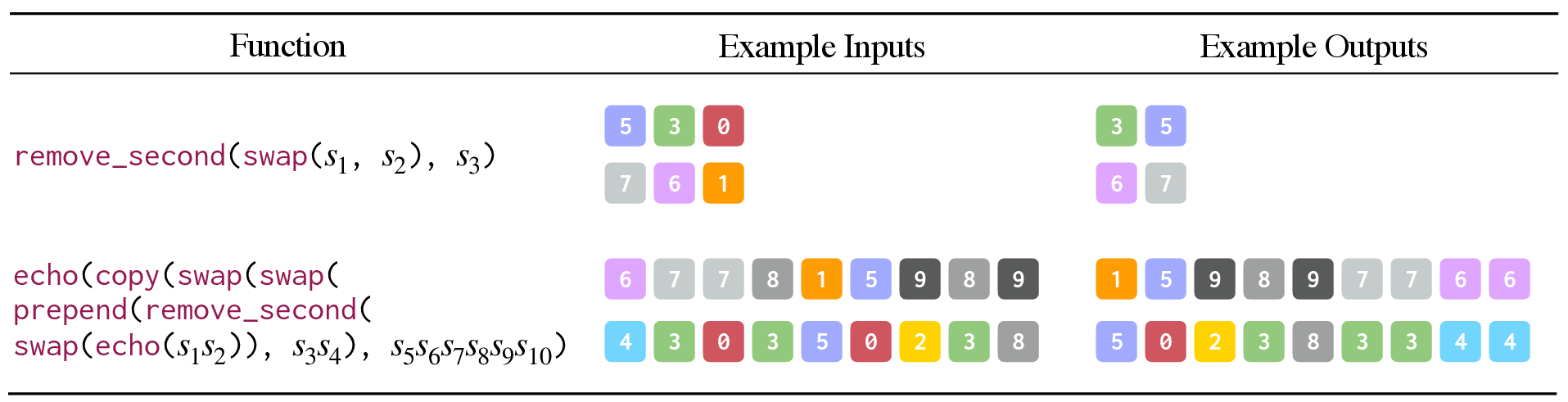
Figure 5: Illustrations of transformations in the PCFG benchmark, showing increasing complexity with more operations and longer sequences.
Sequence Completion: Function Extrapolation and Robotic Motions
The second axis of investigation is sequence completion, where LLMs are tasked with extrapolating the continuation of a function or trajectory given partial context. The authors show that LLMs can accurately extrapolate sinusoids and more complex functions (e.g., y=axsin(bx), y=2xasin(bx)) when outputs are discretized to integer tokens.
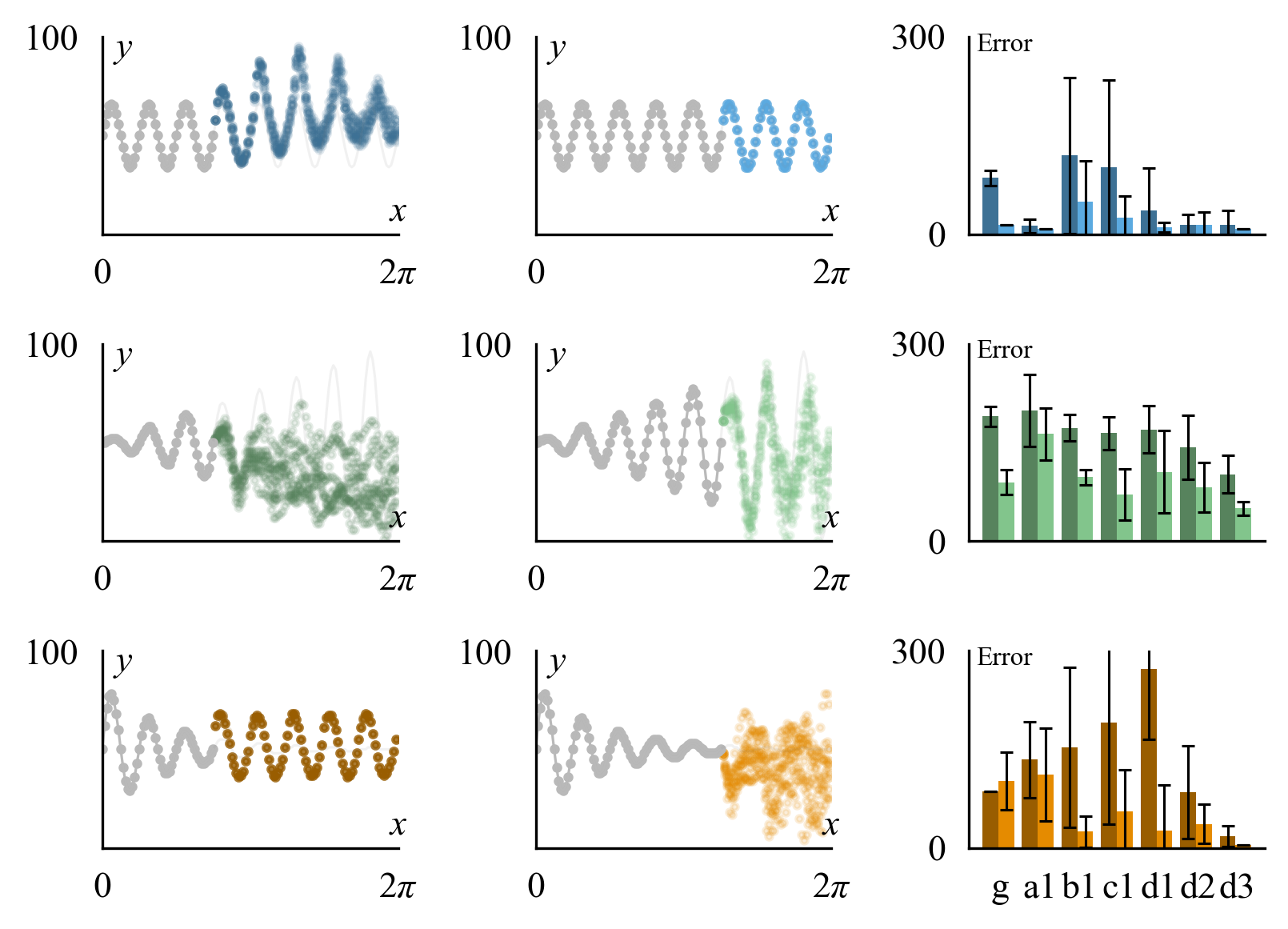
Figure 6: The structure learning approach extrapolates various functions y=a⋅sin(bx) with different degrees of error; LLMs perform well with sufficient context.
This capability is leveraged for robotic applications such as table sweeping and whiteboard drawing, where LLMs are prompted with partial demonstrations and asked to complete the motion trajectory. Larger models consistently yield lower error rates and more stable extrapolations.
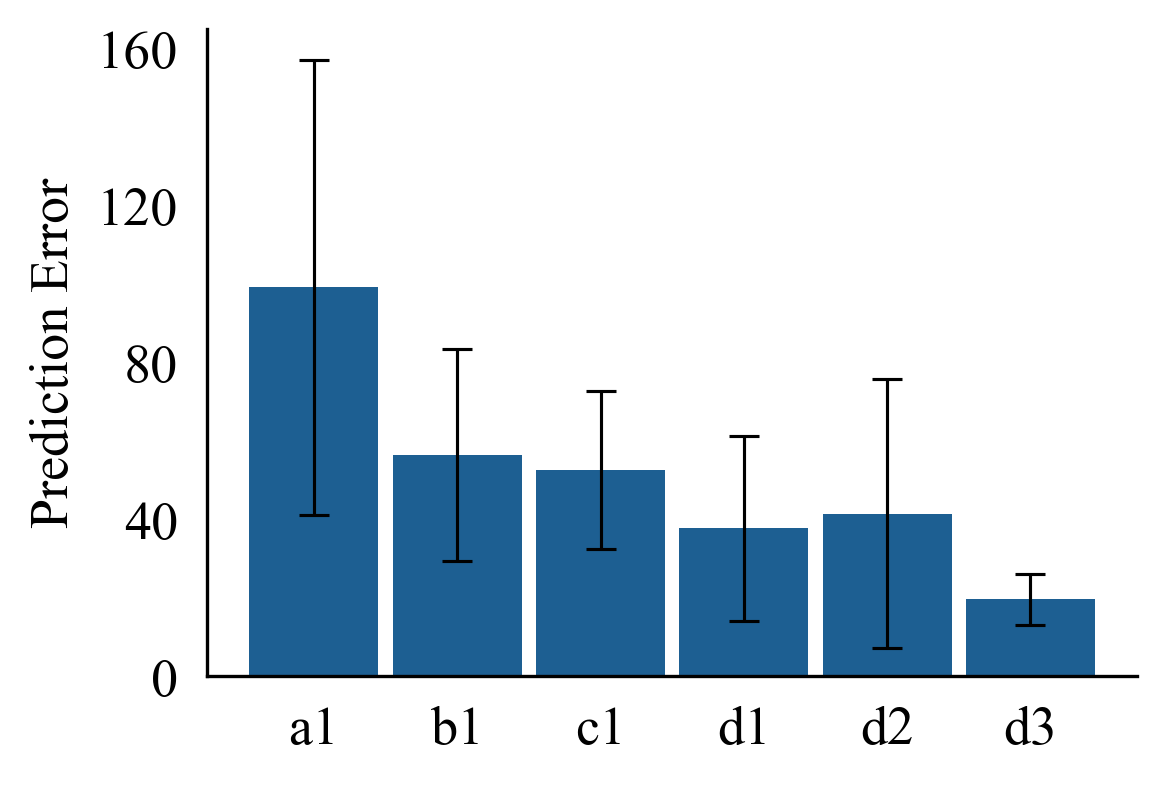
Figure 7: LLM trajectory predictions for Table Sweeping improve with larger models.
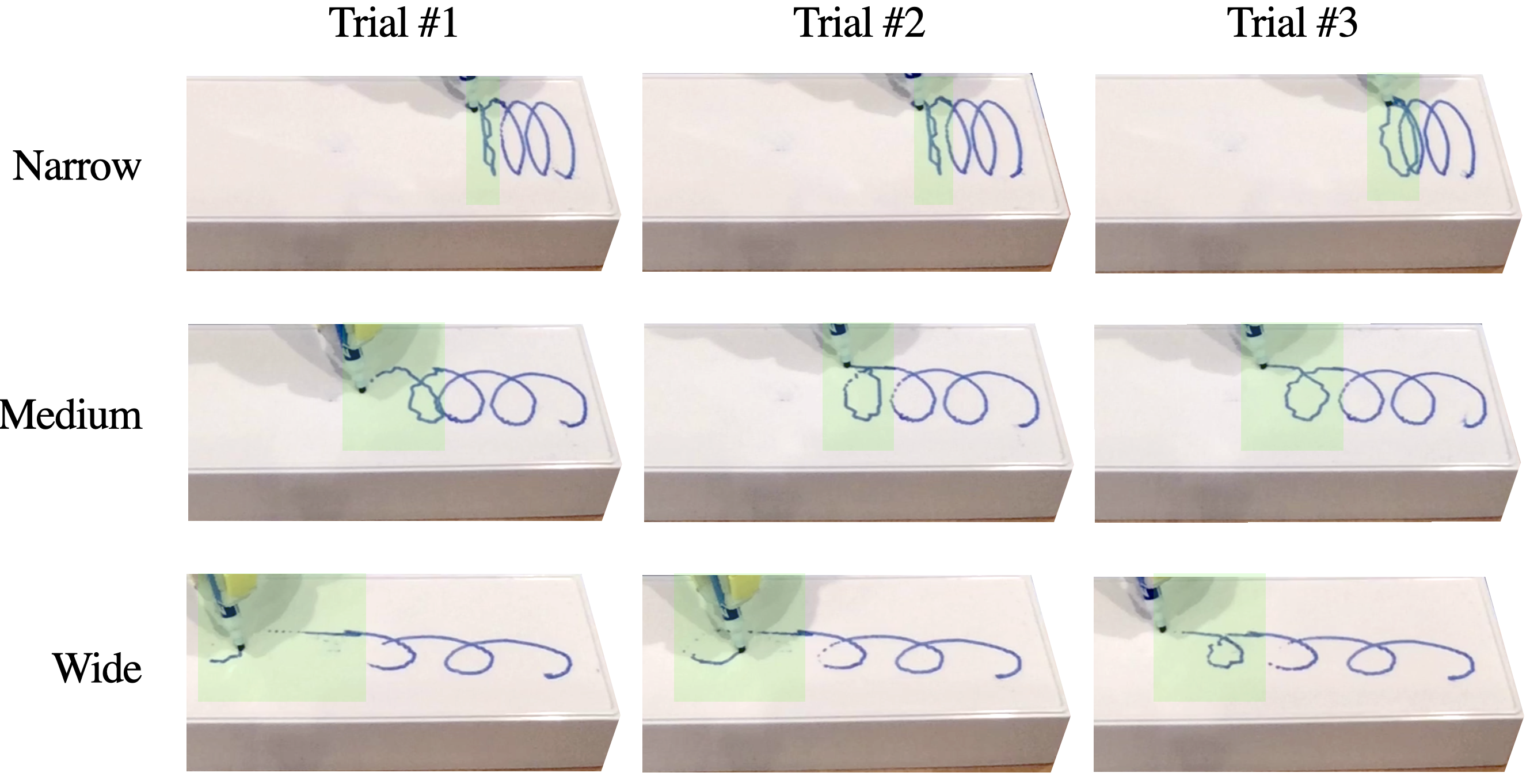
Figure 8: Sampled drawings produced by in-context completion given a scripted demonstration of two loops; each row is a different loop style, each column a different trial.
Sequence Improvement: In-Context Policy Optimization
The most ambitious extension is the use of LLMs for sequence improvement—iteratively generating improved trajectories or policies in a reward-conditioned setting. By prefixing trajectories with their cumulative reward and prompting the LLM to generate higher-reward sequences, the authors demonstrate basic forms of in-context policy optimization.
Experiments include:
- Marker in Cup: LLMs extrapolate trajectories to maximize reward (minimize distance to goal), with performance sensitive to the ordering and annotation of context examples.
- Grid Navigation: LLMs, especially larger ones, can discover higher-reward trajectories in an online, closed-loop setting, outperforming random exploration.
- CartPole: LLMs discover oscillatory control policies to stabilize the pole, with return improving over episodes.
- Human-in-the-Loop Clicker Training: LLMs adapt trajectories in response to sparse, binary human feedback, enabling real-time, reward-driven behavior shaping.
Implementation Considerations and Limitations
The practical deployment of LLMs as general pattern machines in robotics and control is currently constrained by several factors:
- Inference Latency and Cost: Autoregressive token generation for high-dimensional, long-horizon trajectories is computationally expensive and slow.
- Context Length: The number of in-context examples is limited by the model's context window, restricting the complexity and diversity of patterns that can be learned or improved.
- Tokenization Sensitivity: Consistent and appropriate tokenization is critical; mismatches between the pattern's structure and the tokenizer's segmentation can degrade performance.
- Lack of Grounding: LLMs operating solely on symbolic or numeric tokens lack direct perceptual grounding, which may limit robustness in real-world, noisy environments.
Despite these limitations, the demonstrated capabilities suggest that LLMs can serve as a flexible, domain-agnostic prior for pattern recognition and manipulation, with potential for integration into more efficient, grounded, or hybrid systems.
Theoretical and Practical Implications
The findings challenge the prevailing view that LLMs are limited to linguistic or semantically grounded tasks. The observed token invariance and ability to generalize over arbitrary symbolic domains indicate that LLMs' pre-training on language data induces a form of universal sequence modeling capacity. This has several implications:
- Transfer to Non-Linguistic Domains: LLMs can be repurposed for abstract reasoning, program synthesis, and control without retraining, provided the input/output is appropriately tokenized.
- In-Context Meta-Learning: The results support the hypothesis that LLMs perform a form of meta-learning, inferring task structure and regularities from few-shot examples in context.
- Foundation Models for Robotics: LLMs could serve as a backbone for generalist robotic agents, especially as multimodal pre-training and efficient inference techniques mature.
Future Directions
Key avenues for future research include:
- Scaling to Multimodal and Real-World Tasks: Integrating visual, proprioceptive, and language modalities to enable more robust and grounded pattern manipulation.
- Efficient Inference and Memory Augmentation: Developing architectures or retrieval mechanisms to overcome context length and latency bottlenecks.
- Fine-Tuning and Domain Adaptation: Investigating how domain-specific objectives and data can further enhance LLMs' pattern reasoning in robotics and control.
- Formal Characterization of Pattern Capacity: Theoretical analysis of the classes of patterns and transformations that LLMs can represent and generalize.
Conclusion
This work provides compelling evidence that pre-trained LLMs possess a significant degree of general pattern recognition and manipulation capability, extending well beyond language. Through systematic evaluation on abstract benchmarks and robotic tasks, the authors demonstrate that LLMs can perform sequence transformation, completion, and improvement in a zero-shot, in-context manner, with performance scaling with model size and context. While practical deployment in real-world systems remains limited by computational and architectural constraints, these findings motivate further exploration of LLMs as universal sequence modelers and their integration into future embodied AI systems.

