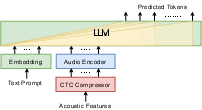
- The paper presents Speech-LLaMA, a decoder-only architecture that integrates an audio encoder and CTC compressor with a pretrained LLM for improved speech-to-text conversion.
- The methodology employs frame-averaging in the CTC compressor and non-causal attention masks with LoRA fine-tuning to achieve up to a 4.6 BLEU score gain.
- The study demonstrates parameter efficiency and superior multilingual translation performance across 13 languages using the CoVoST dataset.
Speech-to-Text and LLM Integration with Decoder-Only Architectures
Introduction
The integration of speech signals into LLMs remains a largely unexplored domain, particularly in leveraging the "decoder-only" architecture for speech processing tasks. The paper "On decoder-only architecture for speech-to-text and LLM integration" (2307.03917) presents an innovative approach, termed Speech-LLaMA, which integrates acoustic information into text-based LLMs. This research addresses the complexities of aligning speech and text modalities within LLM frameworks, deploying a decoder-only model architecture to streamline and enhance speech-to-text conversion processes.
Methodology
The Study introduces a sophisticated approach employing a pre-existing LLM integrated with an acoustic feature compressor and a simple audio encoder. The proposed Speech-LLaMA model utilizes Connectionist Temporal Classification (CTC) to map compressed acoustic features onto the continuous semantic space of the LLM, diverging from traditional methods that convert speech into discrete tokens. This direct mapping facilitates a seamless fusion of audio and text data, optimizing the LLM's ability to transcribe and translate speech inputs efficiently.
Architecture Overview:
The proposed system comprises three core components: a pre-trained text neural LLM, a CTC compressor for sequence length reduction, and an audio encoder bridging CTC outputs to the LLM's semantic space.
Experimental Setup
The researchers conducted extensive experiments on multilingual speech-to-text translation tasks. The framework was evaluated across 13 languages with data sourced from the CoVoST dataset. Speech-LLaMA was benchmarked against robust seq2seq architectures and enhanced using various configurations, including causal and non-causal attention mask strategies to allow full context learning of acoustic features.
Baseline Comparison:
- Baseline models employed a seq2seq architecture, with additional experiments using LLaMA n-best rescoring to enhance their performance.
- Speech-LLaMA demonstrated significant improvements over these baselines, achieving up to a 4.6 BLEU score gain, highlighting its superiority in parameter efficiency and performance.
Results
The results underscore the capabilities of the Speech-LLaMA model in multilingual speech translation tasks, with notable advances in BLEU scores across all language pairs tested. The "frame-averaging" approach in the CTC compressor outperformed other strategies, effectively leveraging pretrained transcription data to enhance performance. Further, experiments indicated that non-causal attention masks and LoRA fine-tuning yield substantial improvements, underscoring the importance of contextual and low-resource adaptations in enhancing LLM capabilities for speech tasks.
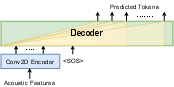
Figure 2: The architecture of the decoder-only model for the from-scratch training.
Discussion
The study emphasizes the advantages of the decoder-only architecture in speech processing, validating its efficacy in achieving competitive results with fewer parameters than traditional encoder-decoder models. This shared parameter system offers improved parameter efficiency, potentially advancing both academic research and practical applications of LLMs in speech-related tasks. Future research directions could explore dynamic integration with extensive language resources and optimized fine-tuning techniques for broader application domains.
Conclusion
The development of the Speech-LLaMA framework marks a significant stride in integrating speech and text modalities within LLMs using a decoder-only architecture. This research not only demonstrates substantial gains in multilingual speech-to-text tasks but also sets the stage for future advancements in parameter-efficient, deeply integrated LLMs capable of processing diverse inputs seamlessly.