A Simple and Effective Pruning Approach for Large Language Models
(2306.11695)Abstract
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prunes weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method Wanda on LLaMA and LLaMA-2 across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and performs competitively against recent method involving intensive weight update. Code is available at https://github.com/locuslab/wanda.
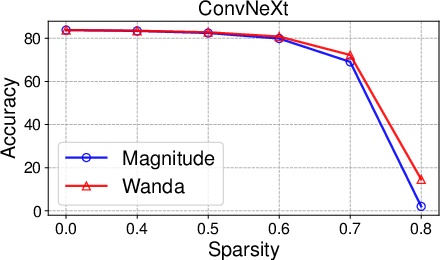
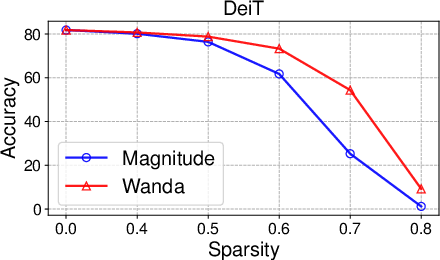
Overview
-
The paper introduces Wanda, a novel method for pruning LLMs that leverages a metric combining weight magnitudes and input activation norms, obviating the need for retraining or computationally expensive weight updates.
-
Wanda demonstrates superior performance in both unstructured and structured pruning tasks across various LLaMA and LLaMA-2 models, maintaining competitive perplexity scores and outperforming traditional pruning methods.
-
Implications of Wanda include the democratization of LLM deployment in computationally limited environments and the potential for further research into higher sparsity levels and real-time sparse training.
A Simple and Effective Pruning Approach for LLMs
The paper under review presents a novel method, termed Wanda, designed to effectively prune LLMs without the need for retraining or computationally expensive weight updates. This method targets the inherent challenges posed by current pruning and sparsity techniques when applied to LLMs with their billions of parameters.
Pruning Context and Motivation
LLMs like GPT-3 and GPT-4 have profoundly impacted the field of NLP with their superior performance. However, due to their substantial size and the associated computational costs, reducing these models' footprint without compromising performance is a critical area of research. Traditionally, network pruning and quantization are two primary approaches for model compression. While network pruning sets certain weights to zero, reducing the overall parameter count, it typically necessitates retraining to recover the performance losses, which is impractical for LLMs.
The paper highlights the recent advent of emergent large magnitude features in transformer-based models, as observed in models surpassing 6 billion parameters. These features are significantly larger in magnitude and crucial for the predictive capabilities of LLMs. Despite this, conventional pruning methods like magnitude pruning or those requiring second-order information for weight updates fall short due to their high computational demands or ineffectiveness without retraining.
Wanda Approach
Wanda distinguishes itself by focusing on pruning weights based on a novel metric combining weight magnitudes and input activation norms. Specifically, each weight's importance is evaluated by the product of its magnitude and the corresponding input activation norm. This metric is grounded in the observation that input activations can differ significantly in scale and must be considered for effective pruning.
Key Points of the Wanda Method:
- Pruning Metric: Defined by ( S{ij} = |W{ij}| \cdot |Xj|2 ). This metric evaluates each weight by considering both its magnitude and the norm of the corresponding input activation.
- Comparison Group: Weights are compared on a per-output basis, rather than globally or per-layer, to maintain a balanced pruning ratio across output features.
- Implementation: Computationally efficient, requiring only a single forward pass through the model and minimal memory overhead.
Empirical Evaluation
The effectiveness of Wanda is demonstrated through comprehensive experiments on the LLaMA and LLaMA-2 model families, including LLaMA-7B, 13B, 30B, 65B, and LLaMA-2-7B, 13B, 70B. The models were assessed on several language benchmarks, performing zero-shot and few-shot evaluations.
Zero-Shot Performance:
- Unstructured Pruning: At 50% sparsity, Wanda consistently outperforms traditional magnitude pruning and competes favorably with SparseGPT. Notably, the results show that sparse LLMs can achieve comparable performance to their dense counterparts.
- Structured Pruning: For structured 4:8 and 2:4 sparsity patterns, Wanda again outperforms magnitude pruning and provides results on par with SparseGPT, highlighting its robustness and efficiency.
Language Modeling Perplexity:
- Wanda delivers competitive performance in preserving the perplexity of pruned models. For unstructured 50% sparsity, it achieves comparable results to SparseGPT, while avoiding the computational overhead associated with weight updates.
Analysis and Robustness
The paper further explore the robustness of Wanda under varying calibration datasets, showing that it remains effective with minimal calibration data. It also explores the impact of fine-tuning pruned models, indicating that most performance losses can be recuperated with either LoRA fine-tuning or full-parameter dense fine-tuning.
Implications and Future Directions
The proposed Wanda method has significant implications for the deployment and democratization of LLMs. By enabling effective pruning without retraining, it facilitates the use of these models in environments with limited computational resources. This approach opens avenues for further research in pruning LLMs at higher sparsities and exploring its applicability in real-time sparse training.
In conclusion, Wanda offers a promising, efficient, and practical solution for pruning LLMs, contributing to the broader goal of making high-performing LLMs more accessible and sustainable. Further research could focus on extending Wanda to dynamic sparsity patterns and integrating it within sparse training paradigms, potentially revolutionizing how large models are trained and deployed.