Full Parameter Fine-tuning for Large Language Models with Limited Resources
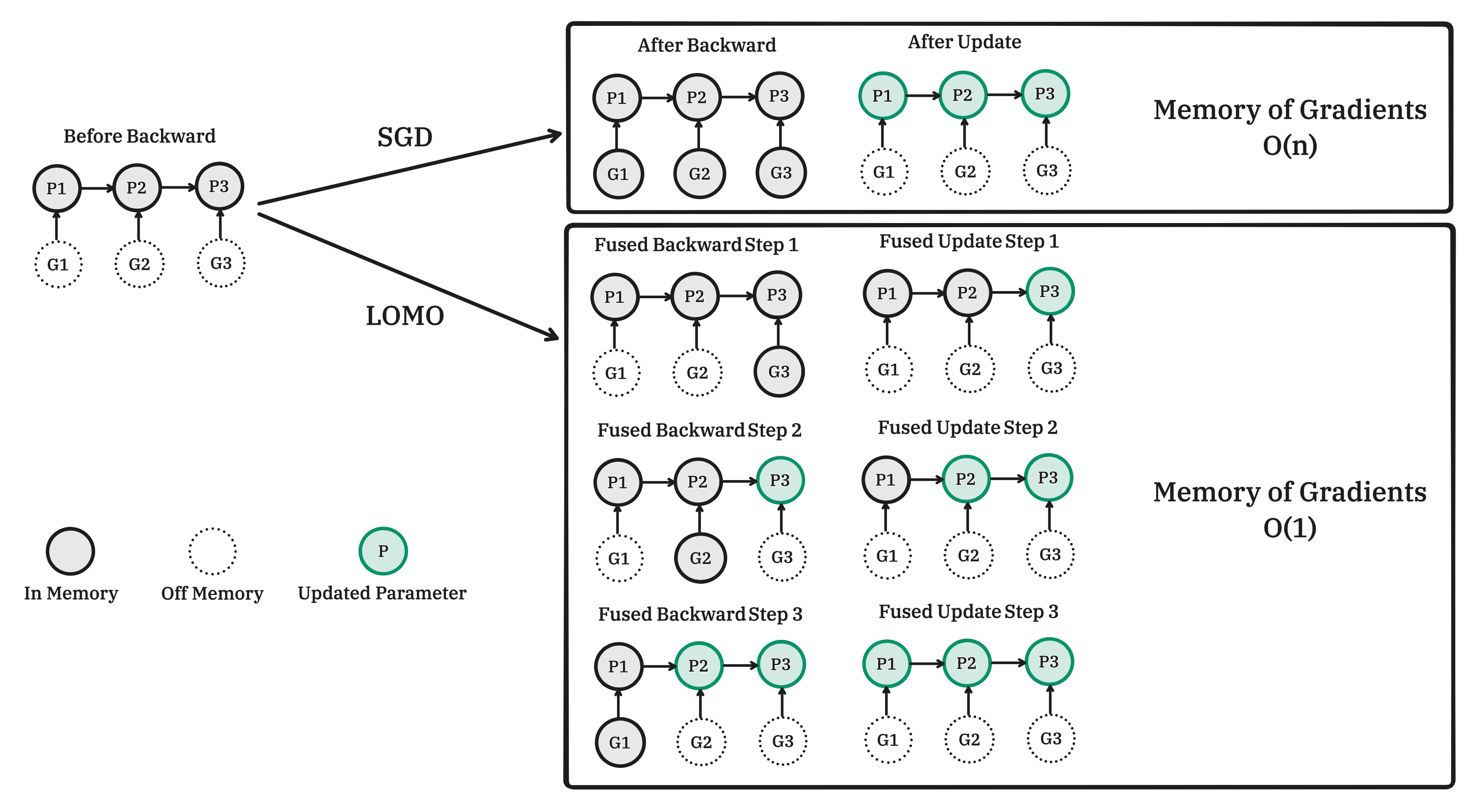
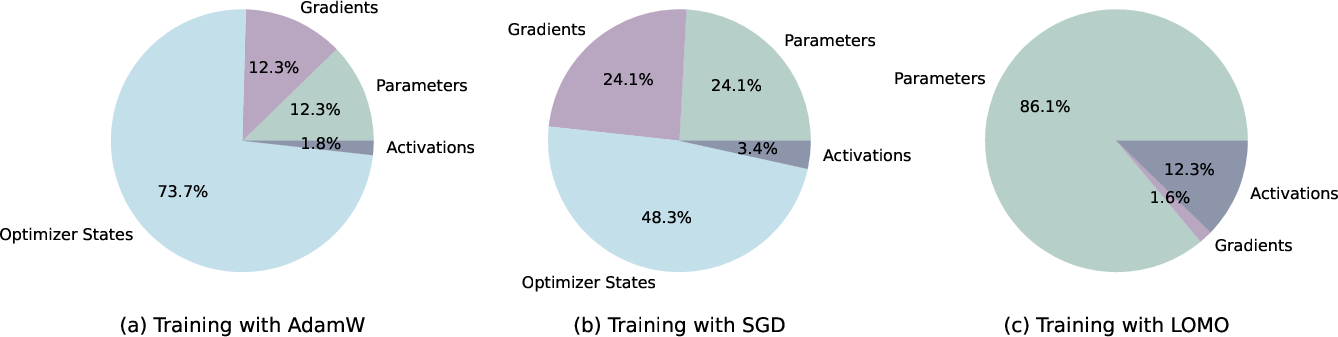
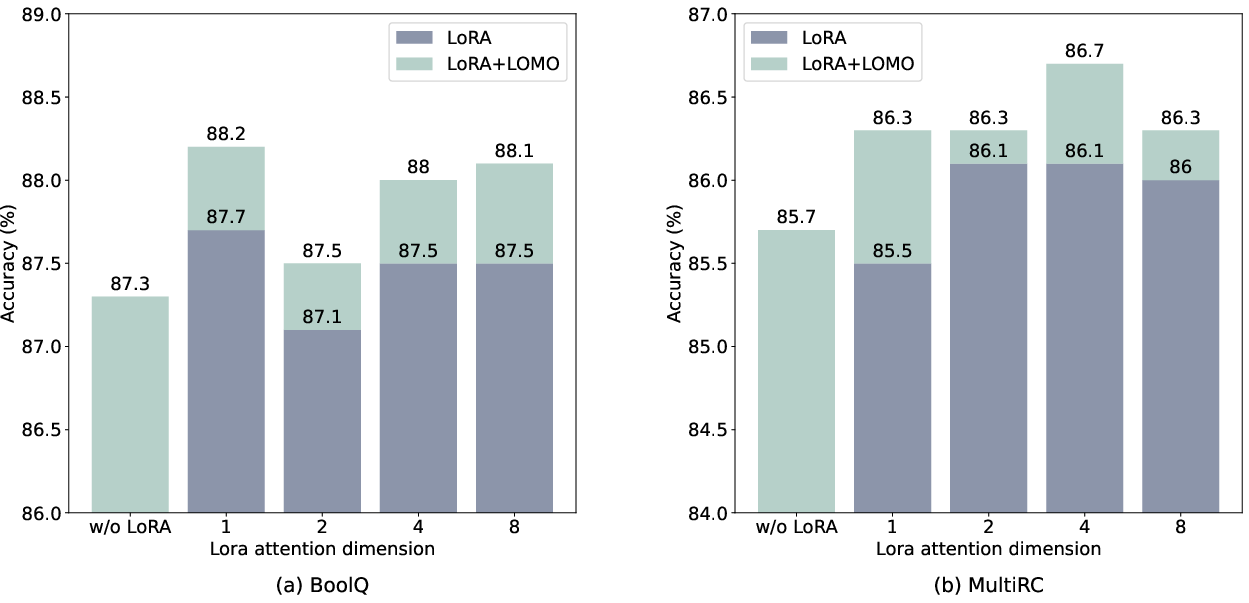
Abstract: LLMs have revolutionized NLP but demand massive GPU resources for training. Lowering the threshold for LLMs training would encourage greater participation from researchers, benefiting both academia and society. While existing approaches have focused on parameter-efficient fine-tuning, which tunes or adds a small number of parameters, few have addressed the challenge of tuning the full parameters of LLMs with limited resources. In this work, we propose a new optimizer, LOw-Memory Optimization (LOMO), which fuses the gradient computation and the parameter update in one step to reduce memory usage. By integrating LOMO with existing memory saving techniques, we reduce memory usage to 10.8% compared to the standard approach (DeepSpeed solution). Consequently, our approach enables the full parameter fine-tuning of a 65B model on a single machine with 8 RTX 3090, each with 24GB memory.Code and data are available at https://github.com/OpenLMLab/LOMO.
- Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174, 2016.
- Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. In Jennifer G. Dy and Andreas Krause (eds.), Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 of Proceedings of Machine Learning Research, pp. 793–802. PMLR, 2018. URL http://proceedings.mlr.press/v80/chen18a.html.
- Boolq: Exploring the surprising difficulty of natural yes/no questions. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 2924–2936. Association for Computational Linguistics, 2019. doi: 10.18653/v1/n19-1300. URL https://doi.org/10.18653/v1/n19-1300.
- The PASCAL recognising textual entailment challenge. In Joaquin Quiñonero Candela, Ido Dagan, Bernardo Magnini, and Florence d’Alché-Buc (eds.), Machine Learning Challenges, Evaluating Predictive Uncertainty, Visual Object Classification and Recognizing Textual Entailment, First PASCAL Machine Learning Challenges Workshop, MLCW 2005, Southampton, UK, April 11-13, 2005, Revised Selected Papers, volume 3944 of Lecture Notes in Computer Science, pp. 177–190. Springer, 2005. doi: 10.1007/11736790_9. URL https://doi.org/10.1007/11736790_9.
- Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models. CoRR, abs/2203.06904, 2022. doi: 10.48550/arXiv.2203.06904. URL https://doi.org/10.48550/arXiv.2203.06904.
- Visualizing and understanding the effectiveness of BERT. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pp. 4141–4150. Association for Computational Linguistics, 2019. doi: 10.18653/v1/D19-1424. URL https://doi.org/10.18653/v1/D19-1424.
- Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Looking beyond the surface: A challenge set for reading comprehension over multiple sentences. In Marilyn A. Walker, Heng Ji, and Amanda Stent (eds.), Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 1 (Long Papers), pp. 252–262. Association for Computational Linguistics, 2018. doi: 10.18653/v1/n18-1023. URL https://doi.org/10.18653/v1/n18-1023.
- Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun (eds.), 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http://arxiv.org/abs/1412.6980.
- The winograd schema challenge. In Gerhard Brewka, Thomas Eiter, and Sheila A. McIlraith (eds.), Principles of Knowledge Representation and Reasoning: Proceedings of the Thirteenth International Conference, KR 2012, Rome, Italy, June 10-14, 2012. AAAI Press, 2012. URL http://www.aaai.org/ocs/index.php/KR/KR12/paper/view/4492.
- Prefix-tuning: Optimizing continuous prompts for generation. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pp. 4582–4597. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.acl-long.353. URL https://doi.org/10.18653/v1/2021.acl-long.353.
- Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7.
- Fine-tuning language models with just forward passes. CoRR, abs/2305.17333, 2023. doi: 10.48550/arXiv.2305.17333. URL https://doi.org/10.48550/arXiv.2305.17333.
- Mixed precision training. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=r1gs9JgRZ.
- Efficient large-scale language model training on gpu clusters using megatron-lm. Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–15, 2021.
- Automatic differentiation in pytorch. 2017.
- Wic: the word-in-context dataset for evaluating context-sensitive meaning representations. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 1267–1273. Association for Computational Linguistics, 2019. doi: 10.18653/v1/n19-1128. URL https://doi.org/10.18653/v1/n19-1128.
- Training large neural networks with constant memory using a new execution algorithm. arXiv preprint arXiv:2002.05645, 2020.
- Zero: Memory optimizations toward training trillion parameter models. SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–16, 2020.
- Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning. Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–14, 2021.
- Sentinel: Efficient tensor migration and allocation on heterogeneous memory systems for deep learning. In 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pp. 598–611, 2021a. doi: 10.1109/HPCA51647.2021.00057.
- Zero-offload: Democratizing billion-scale model training. USENIX Annual Technical Conference, pp. 551–564, 2021b.
- vdnn: Virtualized deep neural networks for scalable, memory-efficient neural network design. In 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 1–13, 2016. doi: 10.1109/MICRO.2016.7783721.
- Choice of plausible alternatives: An evaluation of commonsense causal reasoning. In Logical Formalizations of Commonsense Reasoning, Papers from the 2011 AAAI Spring Symposium, Technical Report SS-11-06, Stanford, California, USA, March 21-23, 2011. AAAI, 2011. URL http://www.aaai.org/ocs/index.php/SSS/SSS11/paper/view/2418.
- Sebastian Ruder. An overview of gradient descent optimization algorithms. CoRR, abs/1609.04747, 2016. URL http://arxiv.org/abs/1609.04747.
- A survey of optimization methods from a machine learning perspective. IEEE Trans. Cybern., 50(8):3668–3681, 2020. doi: 10.1109/TCYB.2019.2950779. URL https://doi.org/10.1109/TCYB.2019.2950779.
- A comparative study between full-parameter and lora-based fine-tuning on chinese instruction data for instruction following large language model. CoRR, abs/2304.08109, 2023. doi: 10.48550/arXiv.2304.08109. URL https://doi.org/10.48550/arXiv.2304.08109.
- Llama: Open and efficient foundation language models. CoRR, abs/2302.13971, 2023. doi: 10.48550/arXiv.2302.13971. URL https://doi.org/10.48550/arXiv.2302.13971.
- Superglue: A stickier benchmark for general-purpose language understanding systems. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pp. 3261–3275, 2019. URL https://proceedings.neurips.cc/paper/2019/hash/4496bf24afe7fab6f046bf4923da8de6-Abstract.html.
- Superneurons: dynamic gpu memory management for training deep neural networks. ACM SIGPLAN Notices, 53:41–53, 02 2018. doi: 10.1145/3200691.3178491.
- Emergent abilities of large language models. Trans. Mach. Learn. Res., 2022, 2022. URL https://openreview.net/forum?id=yzkSU5zdwD.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.