MiniLLM: Knowledge Distillation of Large Language Models
Abstract: Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of LLMs. However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge of white-box LLMs into small models is still under-explored, which becomes more important with the prosperity of open-source LLMs. In this work, we propose a KD approach that distills LLMs into smaller LLMs. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative LLMs, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. The student models are named MiniLLM. Extensive experiments in the instruction-following setting show that MiniLLM generates more precise responses with higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance than the baselines. Our method is scalable for different model families with 120M to 13B parameters. Our code, data, and model checkpoints can be found in https://github.com/microsoft/LMOps/tree/main/minillm.
- Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Why exposure bias matters: An imitation learning perspective of error accumulation in language generation. In Findings of the Association for Computational Linguistics: ACL 2022, pages 700–710, Dublin, Ireland, May 2022. Association for Computational Linguistics.
- On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow, March 2021.
- Language models are few-shot learners. In Proceedings of NeurIPS, 2020.
- Pythia: A suite for analyzing large language models across training and scaling. arXiv preprint arXiv:2304.01373, 2023.
- Scheduled sampling for sequence prediction with recurrent neural networks. Advances in neural information processing systems, 28, 2015.
- Language gans falling short. In International Conference on Learning Representations, 2020.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of NAACL-HLT, 2019.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Distilling policy distillation. In The 22nd international conference on artificial intelligence and statistics, pages 1331–1340. PMLR, 2019.
- Born again neural networks. In International Conference on Machine Learning, pages 1607–1616. PMLR, 2018.
- Openwebtext corpus, 2019.
- Google. Bard, 2023.
- The false promise of imitating proprietary llms. arXiv preprint arXiv:2305.15717, 2023.
- The curious case of neural text degeneration. In International Conference on Learning Representations, 2020.
- Unnatural instructions: Tuning language models with (almost) no human labor. arXiv preprint arXiv:2212.09689, 2022.
- Reinforcement learning with deep energy-based policies. In International conference on machine learning, pages 1352–1361. PMLR, 2017.
- Ferenc Huszár. How (not) to train your generative model: Scheduled sampling, likelihood, adversary? arXiv preprint arXiv:1511.05101, 2015.
- Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- Pre-trained models: Past, present and future. AI Open, 2021.
- Knowledge distillation: A survey. International Journal of Computer Vision, 129(6):1789–1819, 2021.
- Smart: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2177–2190, 2020.
- Tailoring language generation models under total variation distance. In The Eleventh International Conference on Learning Representations, 2023.
- Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023.
- Tinybert: Distilling bert for natural language understanding. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4163–4174, 2020.
- Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Sequence-level knowledge distillation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1317–1327, 2016.
- Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Proceedings of Text Summarization Branches Out (ACL 2004), 2004.
- Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020.
- Improving text generation with student-forcing optimal transport. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9144–9156, 2020.
- RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Tom Minka et al. Divergence measures and message passing. Technical report, Citeseer, 2005.
- Reverse kl-divergence training of prior networks: Improved uncertainty and adversarial robustness. Advances in Neural Information Processing Systems, 32, 2019.
- MosaicML. Introducing mpt-7b: A new standard for open-source, commercially usable llms, 2023.
- Measuring calibration in deep learning. In CVPR workshops, 2019.
- OpenAI. Openai: Introducing chatgpt, 2022.
- OpenAI. Gpt-4 technical report, 2023.
- Training language models to follow instructions with human feedback. In Proceedings of NeurIPS, 2022.
- Richard Yuanzhe Pang and He He. Text generation by learning from demonstrations. In International Conference on Learning Representations, 2021.
- Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023.
- Eligibility traces for off-policy policy evaluation. In Proceedings of the Seventeenth International Conference on Machine Learning, pages 759–766, 2000.
- Is reinforcement learning (not) for natural language processing: Benchmarks, baselines, and building blocks for natural language policy optimization. In The Eleventh International Conference on Learning Representations, 2023.
- Policy distillation. arXiv preprint arXiv:1511.06295, 2015.
- Language models are unsupervised multitask learners. OpenAI Technical report, 2019.
- Patient knowledge distillation for bert model compression. arXiv preprint arXiv:1908.09355, 2019.
- Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019.
- Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- Energy and policy considerations for deep learning in nlp. arXiv preprint arXiv:1906.02243, 2019.
- Defining and characterizing reward gaming. In Advances in Neural Information Processing Systems, 2022.
- Policy gradient methods for reinforcement learning with function approximation. Advances in neural information processing systems, 12, 1999.
- Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of EMNLP, October 2013.
- Lightpaff: A two-stage distillation framework for pre-training and fine-tuning. arXiv preprint arXiv:2004.12817, 2020.
- Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Multitask prompted training enables zero-shot task generalization. In Proceedings of ICLR, 2022.
- Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- MiniLMv2: Multi-head self-attention relation distillation for compressing pretrained transformers. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2140–2151, Online, August 2021. Association for Computational Linguistics.
- Finetuned language models are zero-shot learners. In Proceedings of ICLR, 2022.
- Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Reinforcement learning, pages 5–32, 1992.
- GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model, 2021.
- Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560, 2022.
- Benchmarking generalization via in-context instructions on 1,600+ language tasks. In Proceedings of EMNLP, 2022.
- Emergent abilities of large language models. Transactions on Machine Learning Research, 2022.
- MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Red Hook, NY, USA, 2020. Curran Associates Inc.
- Lamini-lm: A diverse herd of distilled models from large-scale instructions. arXiv preprint arXiv:2304.14402, 2023.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Do not blindly imitate the teacher: Using perturbed loss for knowledge distillation. arXiv preprint arXiv:2305.05010, 2023.
- Minimum divergence vs. maximum margin: an empirical comparison on seq2seq models. In International Conference on Learning Representations, 2019.

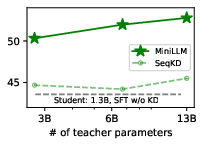
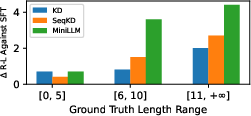
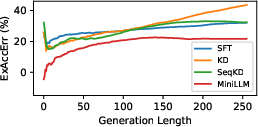
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

