- The paper introduces a novel integration of language reasoning and segmentation masks from foundation models to bridge high-level instructions with low-level robotic actions.
- It employs a two-stream policy model that fuses global (ResNet-50) and local (ResNet-18) features with attention mechanisms, enhancing precision in complex tasks.
- Experimental results show robust performance with an 81.25% success rate in standard settings and effective generalization to unseen objects and distractor-rich environments.
Transferring Foundation Models for Robotic Manipulation
This paper presents a novel approach to enhance the generalization capabilities of robotic manipulation systems by leveraging internet-scale foundation models to generate language-reasoning segmentation masks. These masks are then used to condition an end-to-end policy model, achieving sample-efficient learning for various manipulation tasks in complex, real-world scenarios. The approach aims to bridge the gap between high-level language instructions and low-level robot actions, enabling robots to perform tasks involving unseen objects and environments.
Methodology
The proposed system comprises four main components, as illustrated in Figure 1: a LLM for reasoning, a multi-modal prompt generator, a segmentation mask generator, and a two-stream policy model (TPM).
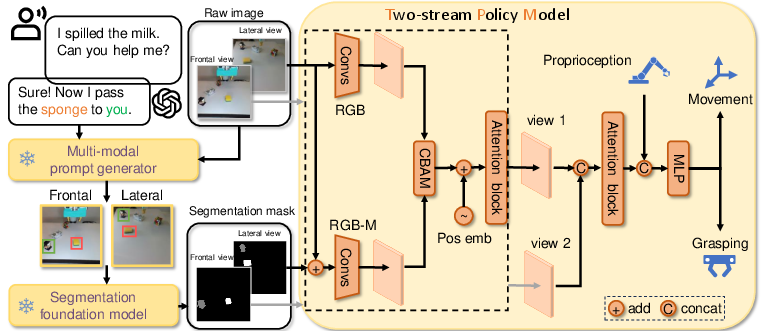
Figure 1: System architecture, highlighting the integration of GPT-4, object detection and tracking, SAM, and a two-stream policy model for robotic manipulation.
Language-Based Reasoning
GPT-4 is employed to interpret human language instructions and reason about the target objects required for task execution. This allows the system to convert abstract instructions, such as "I am thirsty," into specific object prompts, like "pick the milk."
Multi-Modal Prompt Generation
The multi-modal prompt generator identifies and locates the target objects using a combination of open-vocabulary object detection (Grounding DINO) and tracking (MixFormer). Grounding DINO is initially used to locate the objects based on language expressions, while MixFormer tracks the objects in subsequent frames, providing robustness against occlusions, disturbances, and distractors.
Segmentation Mask Generation
The Segment Anything Model (SAM) generates segmentation masks of the target objects using the bounding boxes provided by the multi-modal prompt generator. These masks incorporate semantic, geometric, and temporal correlation priors, enhancing the precision and reliability of object representation for robotic manipulation tasks.
Two-Stream Policy Model
The TPM is a two-stream architecture that processes raw images, language-reasoning object masks, and robot proprioception to predict robot actions. The model consists of a deeper branch (ResNet-50) to capture global RGB information and a shallower branch (ResNet-18) to capture local object-related RGB-M information. The features from both streams are fused using a CBAM block, and attention mechanisms are employed to enhance spatial perception and multi-view feature fusion.
Experimental Results
The effectiveness of the proposed approach was evaluated through real-world experiments on a Franka Emika robot arm. The experiments focused on pick-and-place tasks, assessing the system's ability to generalize to unseen objects, new backgrounds, and more distractors. The results, summarized in Table 1, demonstrate that the system exhibits robustness to a greater number of distractors and unseen objects, attributed to the inclusion of language-reasoning segmentation mask modality derived from foundation models for action prediction. The average success rate in the standard environment was 81.25%, while in the new background and more distractors scenarios, the success rates were 60.0% and 72.5%, respectively.
Further ablation studies (Table 2) validated the contributions of individual components, showing that segmentation masks outperform bounding boxes, tracking is more robust than frame-by-frame detection, multi-view fusion is more beneficial than single-view, and incorporating a separate RGB branch improves performance.

Figure 2: Experimental setup, including the robot arm, camera configurations, training backgrounds, and a challenging background for evaluation.

Figure 3: An example task where the robot interprets the instruction "I want to take a shower" to pick up a towel and place it near a Lego toy representing the user.
Discussion
The authors discuss the scalability of the approach and potential improvements. They suggest that the main performance bottleneck lies in the connection between the language reasoning module and the detection module, as current detectors still lack many visual concepts. They also recommend exploring offline LLMs and distilled lightweight vision models to improve the execution speed of the system.
The authors also address the limitations of their method by noting that extensive demonstrations are needed to learn complex behaviors for contact-rich skills. They acknowledge the need for manually designing complex prompt templates and leave this issue to future work.
Extension to Other Skills
The paper demonstrates the versatility of the policy model, which can be adapted to different manipulation skills such as opening a drawer, placing an object inside another, and placing an object on top of another. This is achieved by conditioning the model with different values assigned to the object masks, showcasing the potential for the system to be extended to a broader range of tasks.

Figure 4: The policy model's adaptability to different manipulation skills by assigning distinct values to object masks.
Conclusion
The paper makes a compelling case for leveraging internet-scale foundation models to enhance the generalization capabilities of robotic manipulation systems. By introducing language-reasoning segmentation masks as a condition representation, the proposed approach achieves sample-efficient learning and demonstrates robustness to unseen objects, new backgrounds, and more distractors. The two-stream policy model architecture further contributes to the system's excellent performance, and the scalability of the approach for new skills is highlighted. These results suggest a promising direction for future research in general-purpose robotic agents.

