- The paper presents Detector Guidance, a novel approach that integrates latent object detection to address object mixing in multi-object text-to-image generation.
- The methodology refines cross-attention maps using detection and correction stages, resulting in an 8-22% improvement in object alignment without extra iterations.
- The approach minimizes manual intervention and leverages robust CAM corrections, setting a foundation for enhancing multimodal generation in diffusion models.
Detector Guidance for Multi-Object Text-to-Image Generation
This essay provides a technical summary of the paper titled "Detector Guidance for Multi-Object Text-to-Image Generation" (2306.02236). The paper presents a novel approach aimed at improving the alignment of text prompts with multiple object generation in text-to-image diffusion models using a method termed Detector Guidance (DG).
Introduction and Background
Diffusion models have demonstrated considerable success in generating images conditioned on textual inputs. They employ text encoders and cross-attention modules to infuse textual information into image generation at a pixel level. Although these models have achieved state-of-the-art performance in generating single-object images from text, challenges persist in generating images containing multiple objects, particularly when object attributes are mixed or objects inadvertently disappear. The inherent issue stems from the lack of global object understanding within the cross-attention blocks, compounded by the noisy intermediate results of diffusion models causing different objects to appear similar.
Previous methods have attempted to address these problems using strong prior knowledge or introducing alternative text encoders. However, these solutions often require significant human intervention and lack the ability to simultaneously resolve issues on the image side. Detector Guidance seeks to overcome these limitations by employing a latent object detection model to preserve distinct object representations during image generation.

Figure 1: Examples of the object mixing problem in text-to-image diffusion models can be observed in DALLcdotE, Midjourney v5, and Stable Diffusion 2.1. This issue can be resolved in Stable Diffusion 2.1 through the implementation of our Detector Guidance.
Detector Guidance Methodology
Cross-Attention Map Analysis
Stable Diffusion models use cross-attention blocks to project the features of textual conditions into image regions. These blocks produce cross-attention maps (CAMs) that exhibit strong alignment capability for text-to-image tasks. Nevertheless, the local alignment process is plagued by uncoordinated competition among text conditions representing multiple objects, leading to hybrid object generation. DG capitalizes on CAMs’ spatial information to enhance global object coherence.
Latent Object Detection and CAM Correction
DG integrates a latent object detection model that operates on CAMs to discern object boundaries. This model, trained on the COCO dataset, generates bounding boxes that enable accurate object detection even in the presence of noisy image data. The detection model’s robustness is attributed to input CAMs' structural similarity across various categories, facilitating generalization to novel objects.
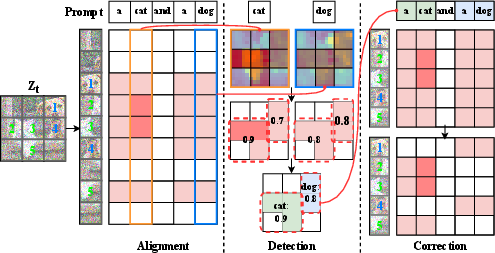
Figure 2: The pipeline of Detector Guidance comprises two stages: detection and correction. In the detection stage, CAMs of nouns are resized into squares, and latent object detection is performed on them. We then assign different regions to different objects to maximize the total confidence value. In the correction stage, we utilize the global alignment between regions and prompts by masking conflicting alignment and enhancing target alignment to generate new, corrected CAMs.
Once DG establishes bounding boxes, it applies corrections to CAMs through several operations:
- Boundary Correction refines object edges using segmentation, addressing overlapping bounding boxes.
- Conflict Elimination replaces inappropriate object alignment in CAMs with unconditional alignment, preventing information mixing.
- Target Enhancement strengthens the alignment of correct text conditions with objects by adjusting CAM values based on historical maximum values.
- Smooth Involvement ensures CAMs' transition is gradual, facilitating compatibility with high-order numerical methods.
Experimental Evaluation
DG's effectiveness is evaluated using Stable Diffusion on benchmarks like COCO and a novel Multi-Related Object (MRO) benchmark. Human evaluations indicate an 8-22% improvement in object alignment without additional iterations or human input. The experiments highlight DG's capability to maintain uniqueness in object regions and reduce conceptual amalgamation.

Figure 3: Each pair of images compares Stable Diffusion v2.1 without (left) or with (right) DG. The first line shows DG's effectiveness for attribute mixing, object mixing, and object disappearance, while the second line demonstrates its effectiveness with complex prompts from COCO.
Implications and Future Work
The introduction of Detector Guidance represents a significant step toward resolving multi-object generation issues in text-to-image models. This method enhances models' comprehensiveness, enabling them to assign regions globally and generate distinct objects simultaneously.
The potential applications of DG extend beyond text-to-image generation. As diffusion models continue to evolve and accommodate more modalities for image generation, DG can serve as a foundational framework for ensuring the alignment and separation of multimodal elements. Moreover, DG's minimal intervention approach, requiring no hyperparameters, supports robust and efficient real-world implementation.
Future research may explore further enhancements in latent object detection, such as adaptive learning mechanisms that respond to dynamic prompt variety, ensuring even greater model generalization and accuracy across diverse domains.
Figure 4: The website used for human evaluation.
Conclusion
Detector Guidance offers a novel solution to object mixing issues in modern text-to-image diffusion models by integrating latent object detection with strategic CAM corrections. Its minimal intervention principle and robust detection performance make it a viable approach for enhancing complex object alignment, paving the way for improved multimodal generation in diffusion models.

