- The paper presents Transformer models that convert into human-readable code, making model decisions easier to inspect.
- It leverages constraints such as disentangled residual streams and categorical attention modules to map internal operations to explicit rules.
- Experiments on algorithmic and NLP tasks show competitive performance while offering improved debugging and interpretability.
Introduction
The paper "Learning Transformer Programs" explores the development of inherently interpretable Transformer models. These Transformer Programs are designed to be directly converted into human-readable code after training, thus addressing the issue of conventional Transformers being opaque and hard to interpret. By leveraging a programming language known as RASP and its compiler Tracr, the proposed approach enables the training of Transformers that can be decompiled into discrete, understandable programs.
Methodology
A novel Transformer variant is introduced that integrates constraints to enable conversion into interpretable programs. The Transformer Programs are constructed by constraining the parameter space into an interpretable subspace, which can be mapped to deterministic programs.
Figure 1 illustrates the general approach of designing a Transformer that can be discretized into a human-readable program.

Figure 1: We design a modified Transformer that can be trained on data and then automatically discretized and converted into a human-readable program.
In order to maintain interpretability, the residual stream is disentangled, meaning that each variable within the token embeddings is stored in orthogonal subspaces. During training, Gumbel-Softmax reparameterization is utilized to manage discrete distributions over model weights.
Figure 2 further describes the structure of these models with constraints to separate variables efficiently.
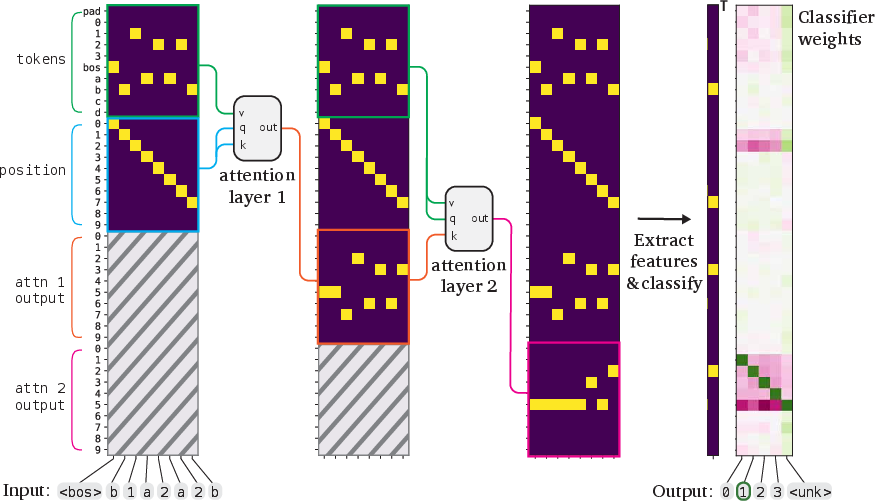
Figure 2: We constrain the Transformer to have a disentangled residual stream.
Model Components
The architecture includes categorical attention modules that utilize a rule-based mapping between input and output variables, ensuring outputs remain categorical. Modifying the standard attention heads and MLP layers allows for operations to be represented as explicit rules, thereby fostering interpretability.
Figure 3 elaborates on the categorical attention mechanism demonstrating rule-based variable mappings.
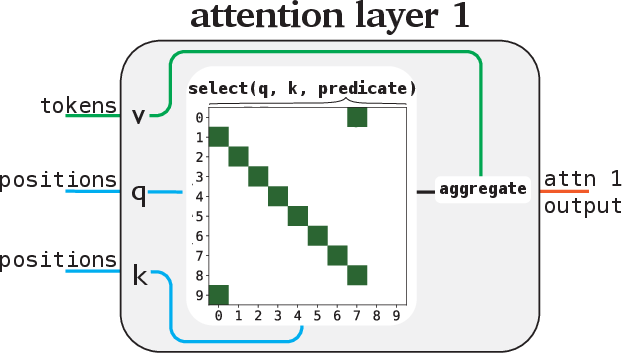
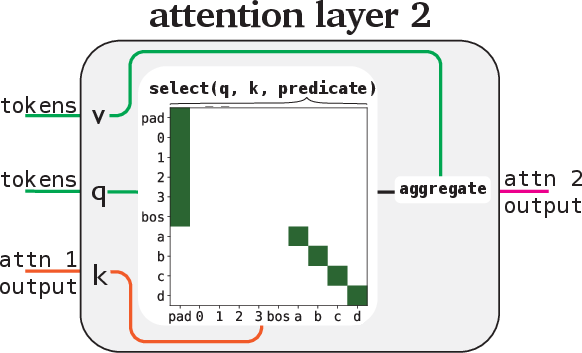
Figure 3: We further constrain each module to implement an interpretable, rule-based mapping between input and output variables.
Each module is structured to read a predetermined set of variables and write to a designated space, thus preserving the program's interpretability.
Experiments
The research validates these Transformer Programs across synthetic algorithmic tasks such as sorting and histogram generation and NLP tasks like named entity recognition.
Results with Algorithmic Tasks
The Transformer Programs were evaluated on a set of RASP tasks, confirming reasonable performance relative to standard Transformers. Despite this, they displayed significant drops in performance when scaling input size.
Figure 4 provides insights into how the accuracy of these models declines with increased input dimensions compared to standard Transformers.
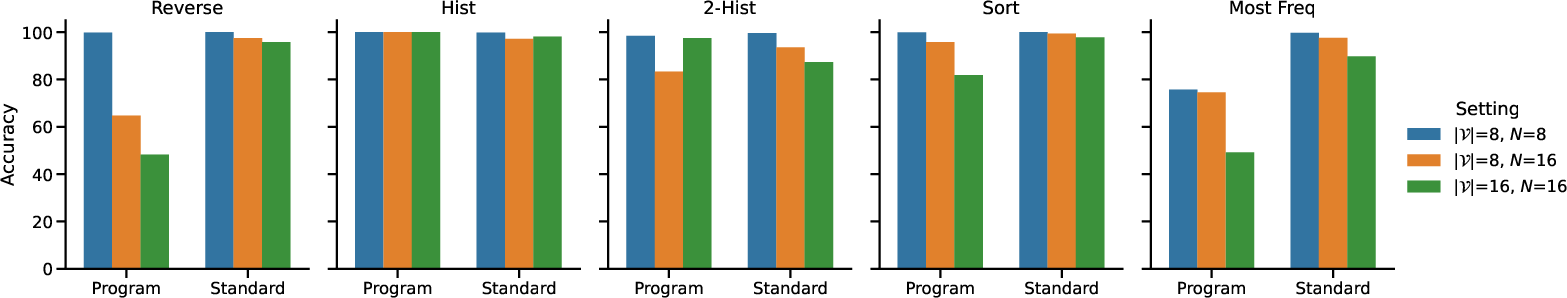
Figure 4: RASP accuracy after increasing the size of the input vocabularies and maximum sequence length, comparing Transformer Programs with standard Transformers.
Practical Application in NLP
For NLP tasks like named entity recognition, Transformer Programs demonstrated competitive performance with fewer parameters, showcasing their utility in contexts where interpretability is essential.
Interpretability Analysis
The generated Python code allows practitioners to utilize debugging tools to inspect and understand model decisions.
Figure 5 shows how models can be inspected using standard programming debugging environments.
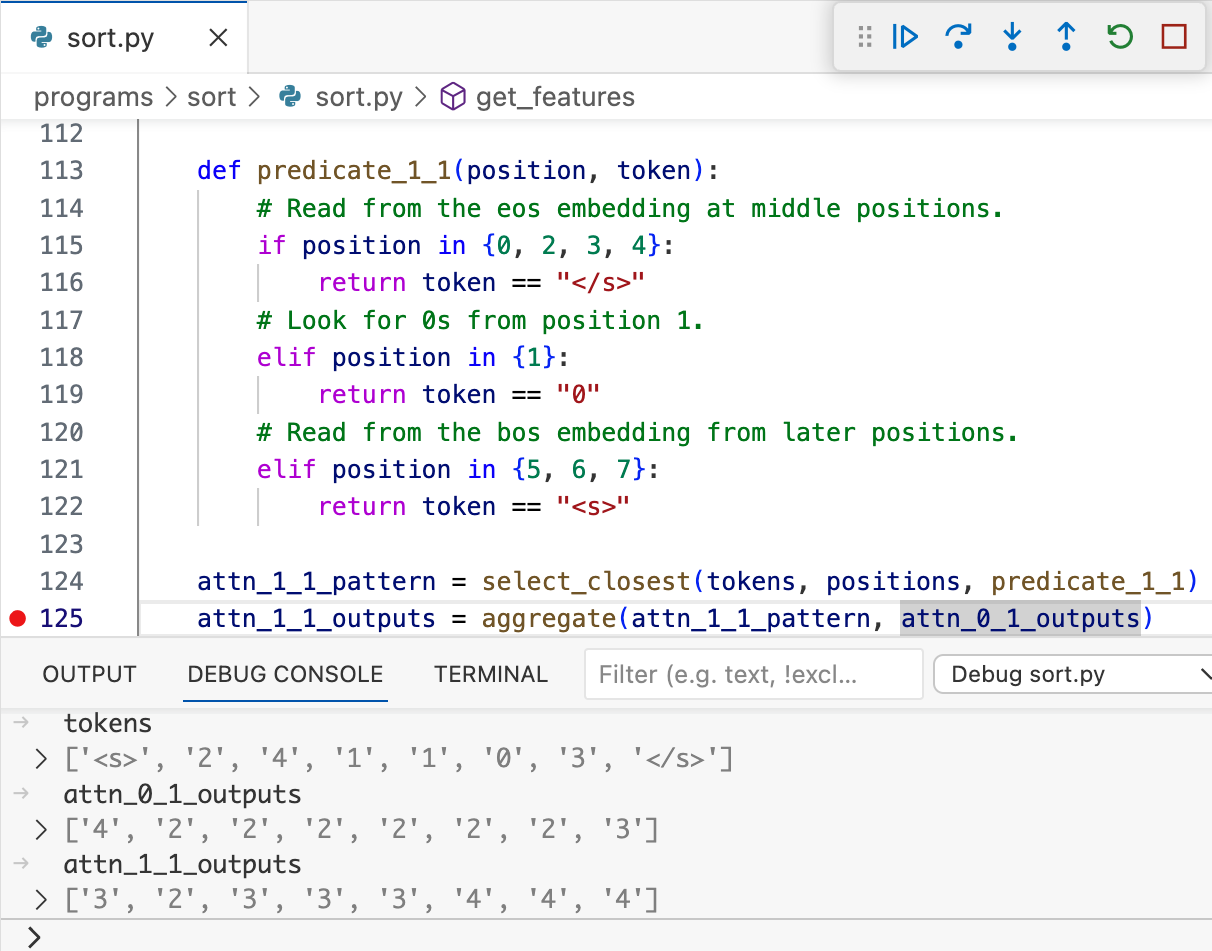
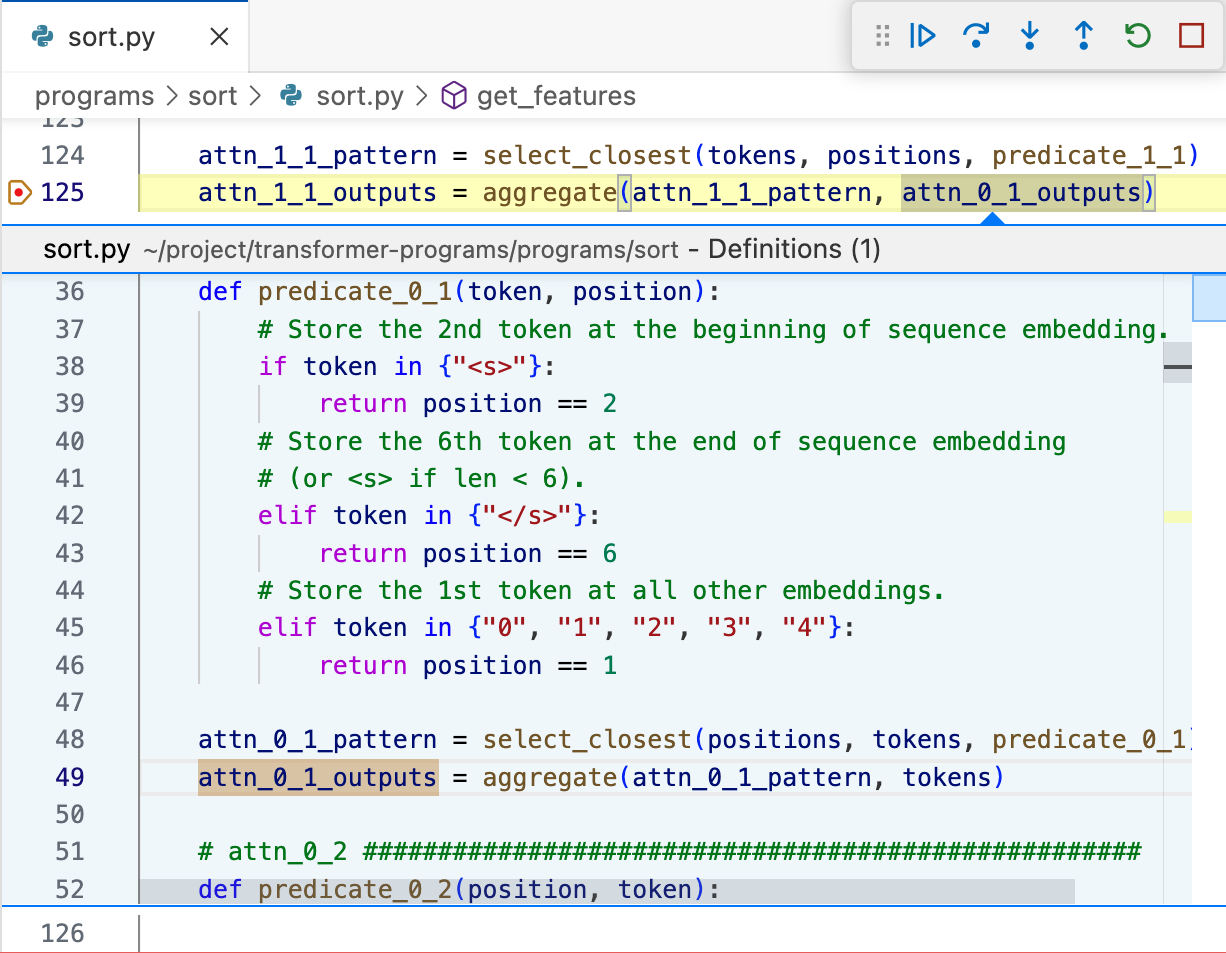
Figure 5: After converting a Transformer Program into Python code, we can analyze it using off-the-shelf debugging tools.
Conclusion
Transformer Programs represent a meaningful advance towards intrinsically interpretable machine learning models. They provide a foundational approach to building models where each component's function can be explicitly understood and analyzed using programming constructs. Future research can focus on enhancing optimization methods for these models and exploring how such interpretability contributes to model trust and error diagnosis in more complex settings.

